



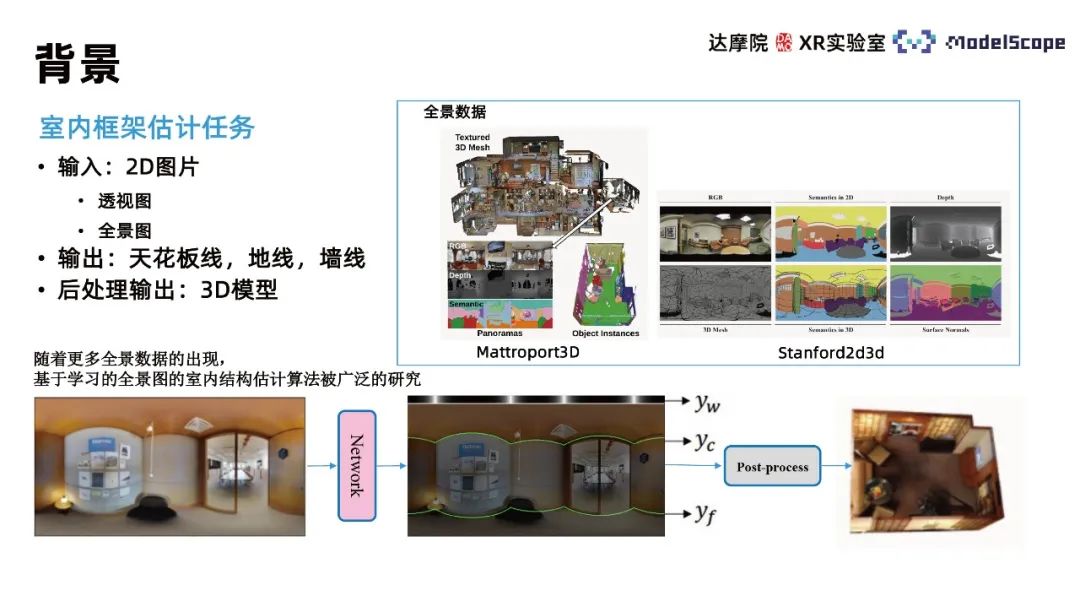
This method mainly focuses on the task of indoor estimation layout estimation, and the task inputs 2D images. , output a three-dimensional model of the scene described by the picture. Considering the complexity of directly outputting a 3D model, this task is generally broken down into outputting the information of three lines: wall lines, ceiling lines, and ground lines in the 2D image, and then reconstructing the 3D model of the room through post-processing operations based on the line information. . The three-dimensional model can be further used in specific application scenarios such as indoor scene reproduction and VR house viewing in the later stage. Different from the depth estimation method, this method restores the spatial geometric structure based on the estimation of indoor wall lines. The advantage is that it can make the geometric structure of the wall flatter; the disadvantage is that it cannot restore the geometric information of detailed items such as sofas and chairs in indoor scenes.
Depending on the input image, it can be divided into perspective-based and panorama-based methods. Compared with perspective views, panoramas have a larger viewing angle and richer image information. With the popularization of panoramic acquisition equipment, panoramic data is becoming more and more abundant, so there are currently many algorithms for indoor frame estimation based on panoramic images that have been widely studied
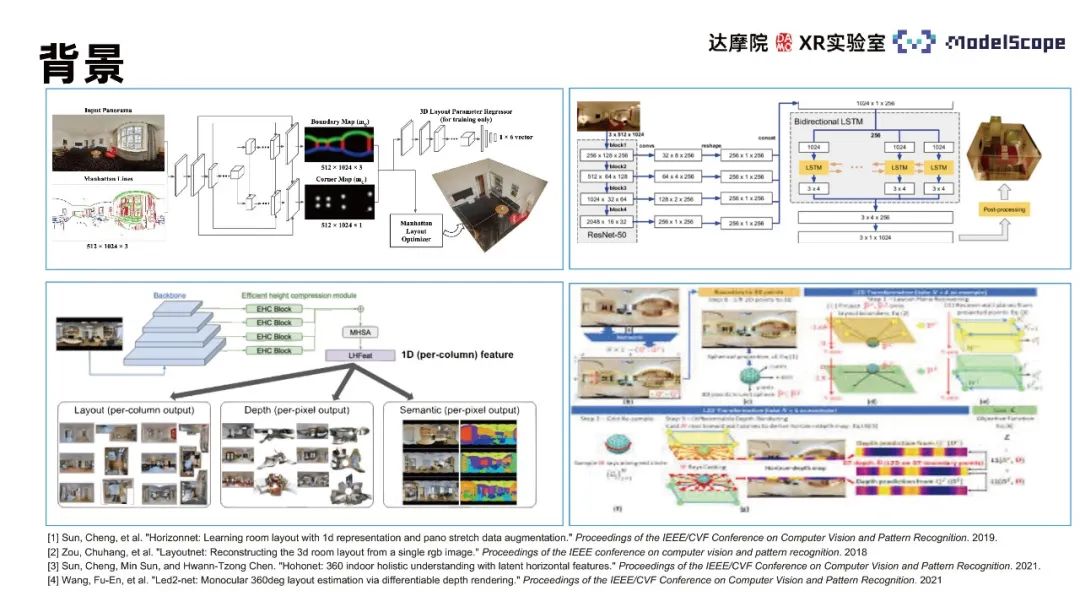
Relevant algorithms mainly include LayoutNet, HorizonNet, HohoNet and Led2-Net, etc. Most of these methods are based on convolutional neural networks. The wall line prediction effect is poor in locations with complex structures, such as noise interference, self-occlusion, etc. Prediction results such as discontinuous wall lines and incorrect wall line positions. In the wall line position estimation task, only focusing on local feature information will lead to this type of error. It is necessary to use the global information in the panorama to consider the position distribution of the entire wall line for estimation. The CNN method performs better in the task of extracting local features, and the Transformer method is better at capturing global information. Therefore, the Transformer method can be applied to indoor frame estimation tasks to improve task performance.
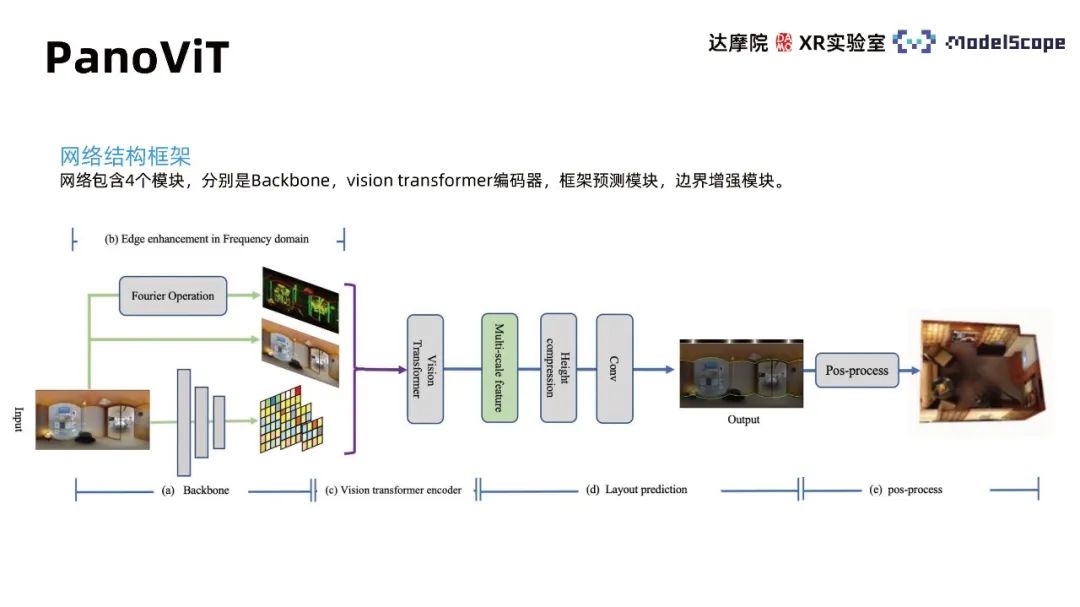
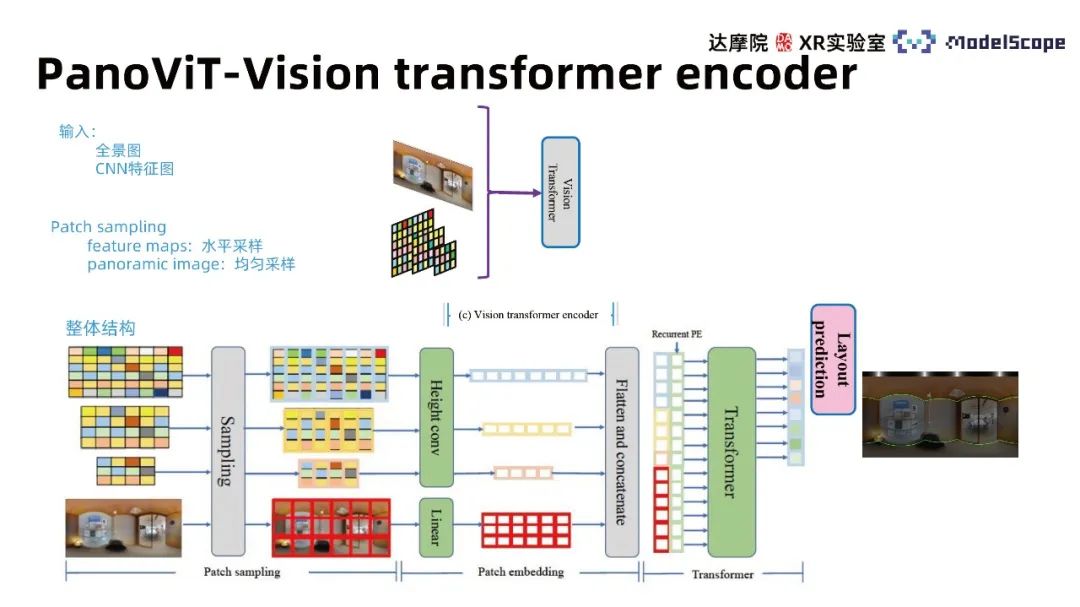
#Due to the dependence of training data, the effect of estimating the panoramic indoor frame by applying the Transformer based on perspective pre-training alone is not ideal. The PanoViT model maps the panorama to the feature space in advance, uses the Transformer to learn the global information of the panorama in the feature space, and also considers the apparent structure information of the panorama to complete the indoor frame estimation task.

Network The structural framework contains 4 modules, namely Backbone, vision transformer decoder, frame prediction module, and boundary enhancement module. The Backbone module maps the panorama to the feature space, the vison transformer encoder learns global correlations in the feature space, and the frame prediction module converts the features into wall line, ceiling line, and ground line information. Post-processing can further obtain the three-dimensional model of the room and its boundaries. The enhancement module highlights the role of boundary information in panoramic images for indoor frame estimation.
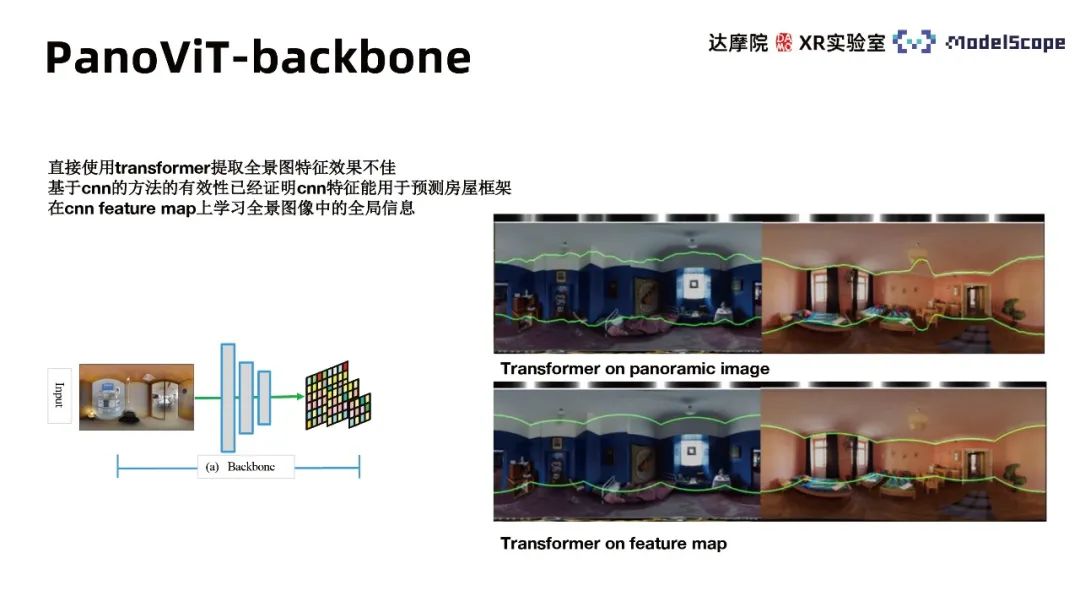
Since the direct use of transformer to extract panoramic features is not effective, it has been proven that the CNN-based method is effective Effectiveness, i.e. CNN features can be used to predict house frames. Therefore, we use the backbone of CNN to extract feature maps of different scales of the panorama, and learn the global information of the panoramic image in the feature maps. Experimental results show that using transformer in feature space is significantly better than applying it directly on the panorama
The main architecture of Transformer can be mainly divided into three modules, including patch sampling, patch embedding and transformer’s multi-head attention. The input considers both the panoramic image feature map and the original image and uses different patch sampling methods for different inputs. The original image uses the uniform sampling method, and the feature map uses the horizontal sampling method. The conclusion from HorizonNet believes that horizontal features are of higher importance in the wall line estimation task. Referring to this conclusion, the feature map features are compressed in the vertical direction during the embedding process. The Recurrent PE method is used to combine features of different scales and learn in the transformer model of multi-head attention to obtain a feature vector with the same length as the horizontal direction of the original image. The corresponding wall line distribution can be obtained through different decoder heads.
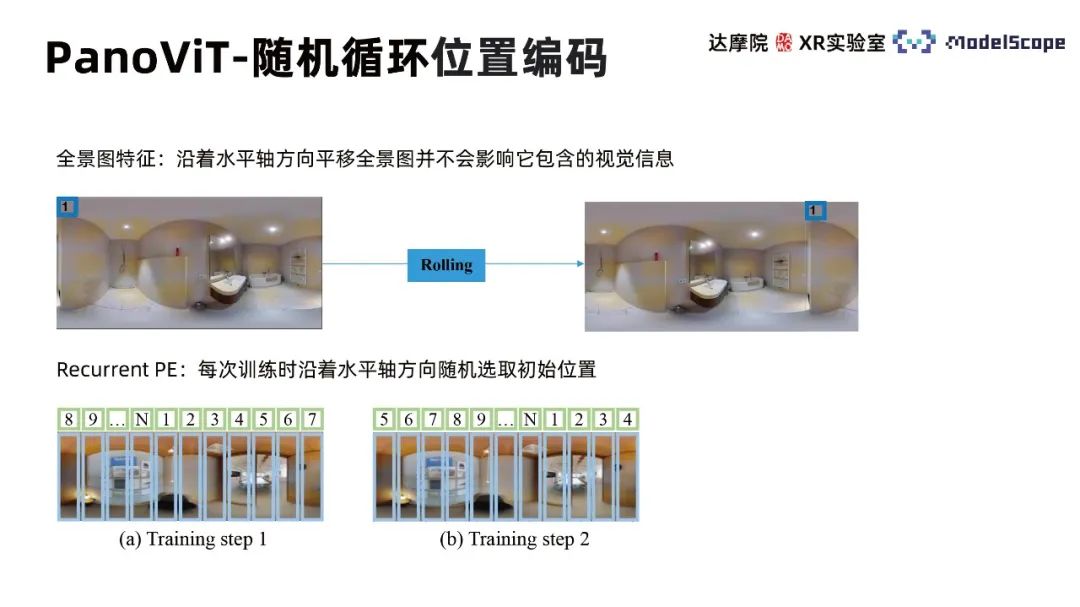
Random cyclic position encoding (Recurrent Position Embedding) takes into account that the displacement of the panorama along the horizontal direction does not change the characteristics of the visual information of the image, so each training The initial position is randomly selected along the horizontal axis, so that the training process pays more attention to the relative position between different patches rather than the absolute position.
Full utilization of geometric information in panorama can contribute to indoor frame estimation task performance improvement. The boundary enhancement module in the PanoViT model emphasizes how to use the boundary information in the panorama, and 3D Loss helps reduce the impact of panorama distortion.
The boundary enhancement module takes into account the linear characteristics of the wall lines in the wall line detection task. The line information in the image is of prominent importance, so it is necessary to highlight the boundary information so that the network can understand the distribution of the center lines of the image. . Use the boundary enhancement method in the frequency domain to highlight the panorama boundary information, obtain the frequency domain representation of the image based on fast Fourier transform, use a mask to sample in the frequency domain space, and transform back to the image with highlighted boundary information based on the inverse Fourier transform . The core of the module lies in the mask design. Considering that the boundary corresponds to high-frequency information, the mask first selects a high-pass filter; and samples different frequency domain directions according to the different directions of different lines. This method is simpler to implement and more efficient than the traditional LSD method. 
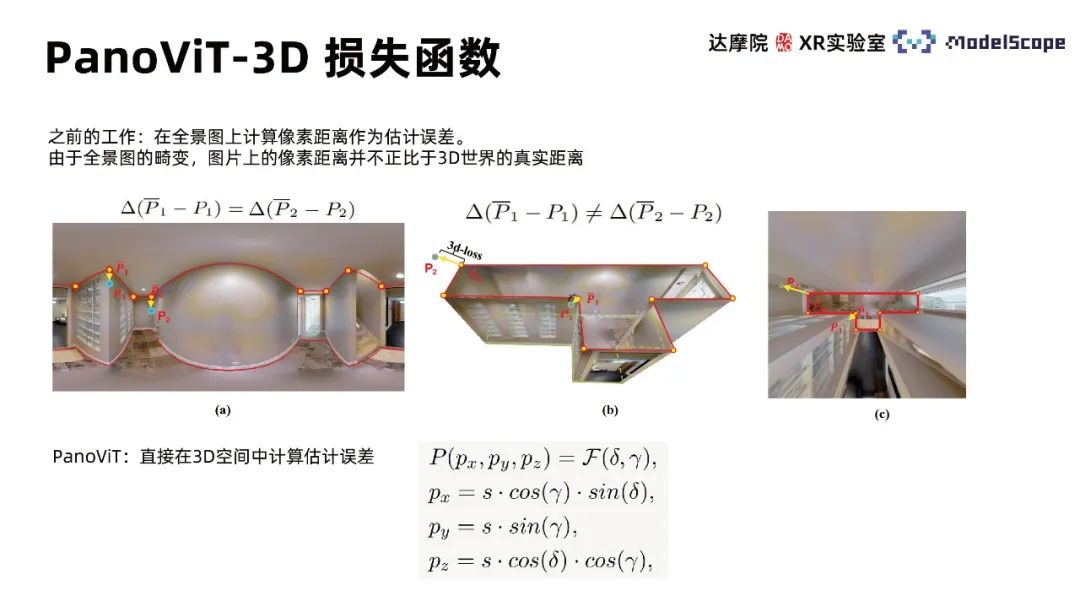
Previous work calculated the pixel distance on the panorama as an estimation error. Due to the distortion of the panorama, the pixel distance on the picture is not proportional to the real distance in the 3D world. PanoViT uses a 3D loss function to calculate the estimation error directly in 3D space.
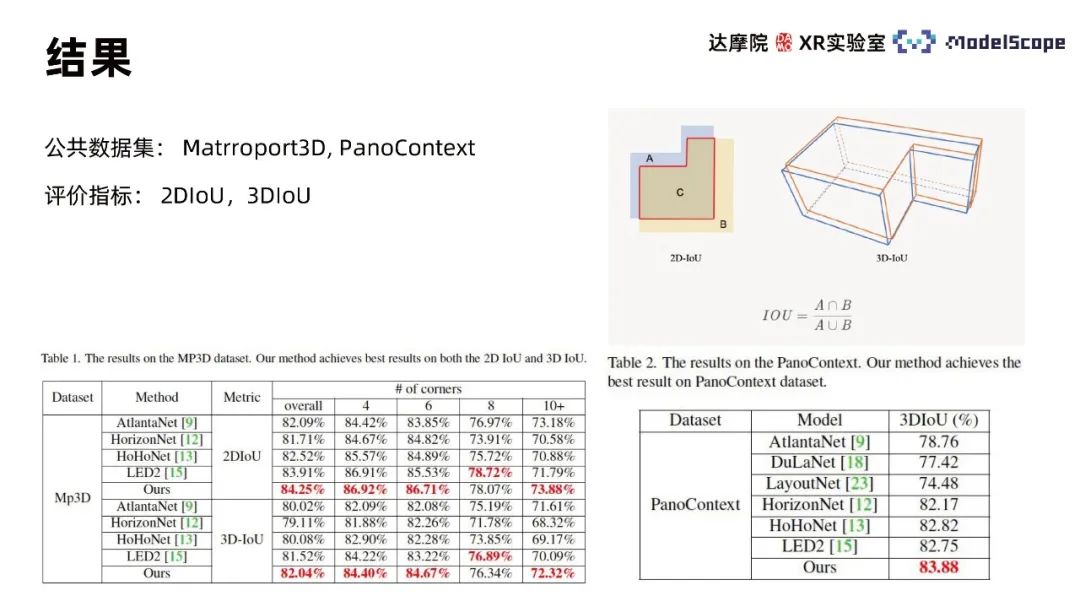
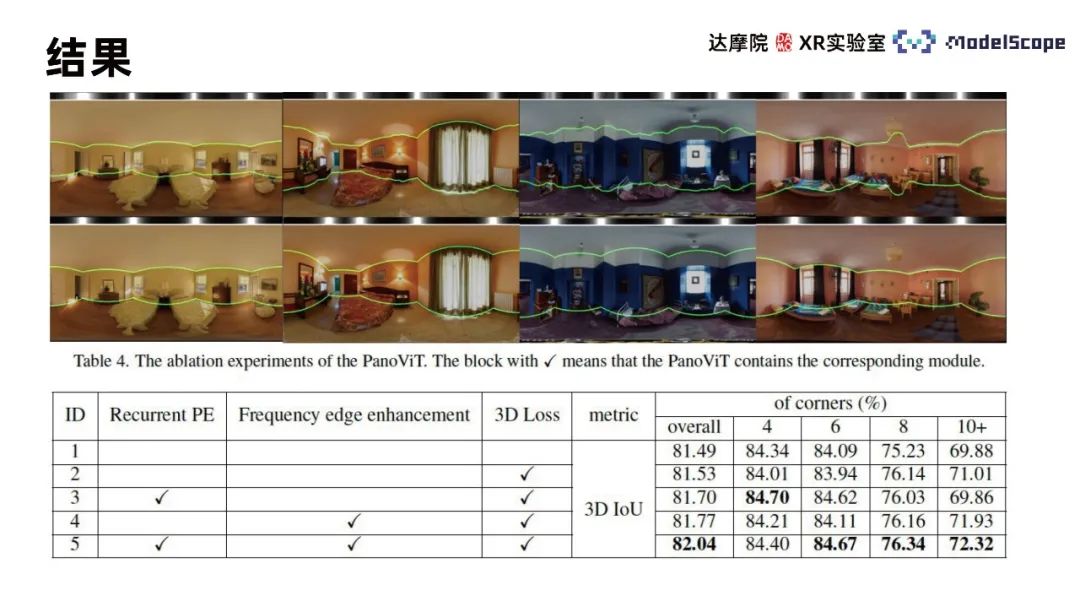
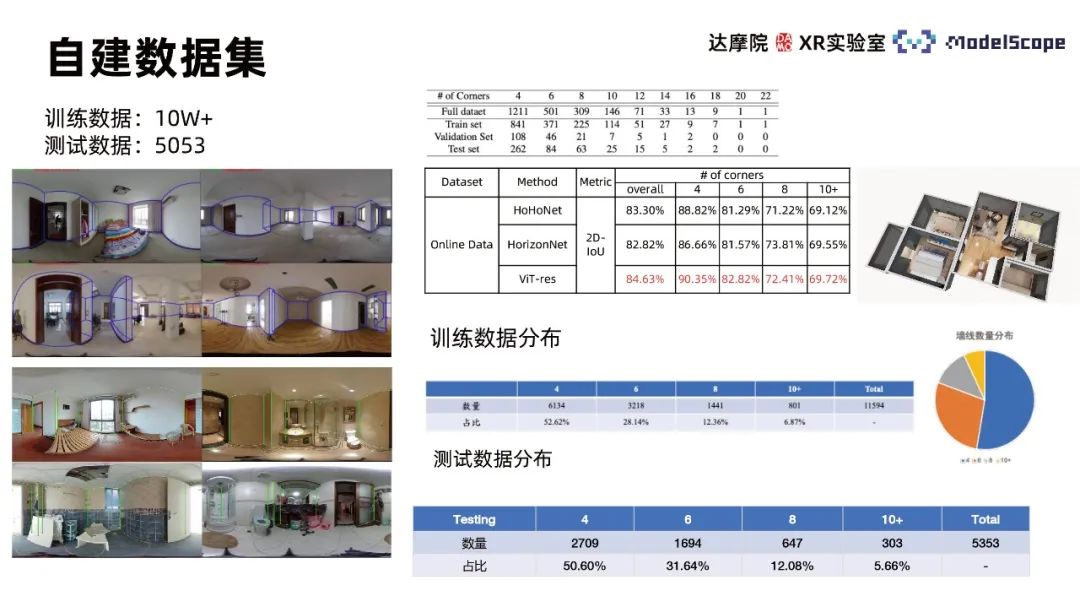
Use Martroport3D and PanoContext public data sets to conduct experiments, using 2DIoU and 3DIoU as evaluation indicators, and Compare with SOTA method. The results show that PanoViT's model evaluation indicators on the two data sets have basically reached the optimal level, and are only slightly inferior to LED2 on specific indicators. By comparing the model visualization results with Hohonet, it can be found that PanoViT can accurately identify the direction of wall lines in complex scenes. By comparing the Recurrent PE, boundary enhancement and 3D Loss modules in ablation experiments, the effectiveness of these modules can be verified


The above is the detailed content of Method for indoor frame estimation using panoramic visual self-attention model. For more information, please follow other related articles on the PHP Chinese website!
 Page replacement algorithm
Page replacement algorithm
 Stepper motor control method
Stepper motor control method
 How to import mdf files into database
How to import mdf files into database
 netframework
netframework
 Introduction to carriage return and line feed characters in java
Introduction to carriage return and line feed characters in java
 Which company does Android system belong to?
Which company does Android system belong to?
 How to open an account with u currency
How to open an account with u currency
 What skills are needed to work in the PHP industry?
What skills are needed to work in the PHP industry?





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



