


This article is reprinted with the authorization of the Autonomous Driving Heart public account. Please contact the source for reprinting.
I believe that except for a few major manufacturers that develop self-developed chips, most autonomous driving companies will use NVIDIA chips, which cannot be separated from TensorRT. TensorRT is a C inference that runs on various NVIDIA GPU hardware platforms frame. The model we have trained using Pytorch, TF or other frameworks can first be converted to onnx format, and then converted to TensorRT format, and then use the TensorRT inference engine to run our model, thereby improving the speed of running this model on NVIDIA GPUs.
Generally speaking, onnx and TensorRT only support relatively fixed models (including fixed input and output formats at all levels, single branches, etc.), and support at most the outermost dynamic input (onnx can be exported by setting the dynamic_axes parameter Determine the dimensions that allow dynamic changes). But friends who are active at the forefront of perception algorithms will know that an important development trend is end-2-end (End-2-End), which may cover target detection, target tracking, trajectory prediction, All aspects of autonomous driving such as decision-making and planning, and must be a timing model that is closely related to the previous and next frames. The MUTR3D model that realizes end-to-end target detection and target tracking can be used as a typical example (for model introduction, please refer to:)
In MOTR/MUTR3D, we will explain the theory and examples of the Label Assignment mechanism in detail to achieve true end-to-end multi-target tracking. Please click the link to read more: https://zhuanlan.zhihu.com/p/609123786
Converting this model to TensorRT format and achieving precision alignment, even precision alignment of fp16, may face a series of problems Dynamic elements, such as multiple if-else branches, dynamic changes in sub-network input shapes, and other operations and operators that require dynamic processing
 Picture
Picture
MUTR3D architecture Because the whole process involves many details, the situation is different. Looking at the reference materials on the entire network, and even searching on Google, it is difficult to find a plug-and-play solution. We can only solve it one by one through continuous splitting and experimentation. Solution. After more than a month of hard exploration and practice by the blogger (I didn’t have much experience with TensorRT before, and I didn’t understand its temperament), I used a lot of brains and stepped on a lot of pitfalls, and finally successfully converted and implemented fp32/ fp16 is accurately aligned, and the delay increase is very small compared to simple target detection. I would like to make a simple summary here and provide a reference for everyone (yes, I have been writing reviews and finally writing practice!)
The first is the data of MUTR3D The format is rather special and is in the form of instances. This is because each query is bound to a lot of information and is packaged into instances for easier one-to-one access. But for deployment, the input and output can only be tensors, so First, the instance data must be disassembled into multiple tensor variables. And since the query and other variables of the current frame are generated in the model, you only need to input the query and other variables retained in the previous frame, and then The two are spliced.
For the input pre-frame query and other variables, an important problem is that the shape is uncertain. This is because MUTR3D only retains queries that have detected targets in previous frames. This problem is relatively easy to solve. The simplest way is padding, that is, padding to a fixed size. For query, you can use all 0s for padding. The appropriate number can be determined by experiments based on your own data. Too few will easily miss the target, too many will waste space. Although the dynamic_axes parameter of onnx can realize dynamic input, there should be a problem because it involves the size calculated by the subsequent transformer. I have not tried it, readers can try it
If you do not use special operators, you can successfully convert to ONNX and TensorRT. In fact, this situation must be encountered, but it is beyond the scope of this article. For example, in MUTR3D, using the torch.linalg.inv operator to find the pseudo-inverse matrix is not supported when moving the reference point between frames. If you encounter an unsupported operator, you can only try to replace it. If it doesn't work, it can only be used outside the model. Experienced people can also write their own operators. But since this step can be placed in the pre- and post-processing of the model, I chose to move it outside the model. It would be more difficult to write your own operators.
Successful conversion does not mean that everything is smooth, the answer is often is negative. We will find that the accuracy gap is very large. This is because the model has many modules, let’s talk about the first reason first. In the self-attention stage of the Transformer, information interaction between multiple queries occurs. However, the original model only retains the queries where the target was once detected (called active queries in the model), and only these queries should interact with the query of the current frame. Now, because many invalid queries are filled in, if all queries interact together, it will inevitably affect the results
The solution to this problem was inspired by DN-DETR[1], which is to use attention_mask, which corresponds to the 'attn_mask' parameter in nn.MultiheadAttention. The function is to block queries that do not require information interaction. Initially, this was because in NLP The length of each sentence in the set is inconsistent, which exactly meets my current needs. I just need to note that True represents the query that needs to be blocked, and False represents the valid query.
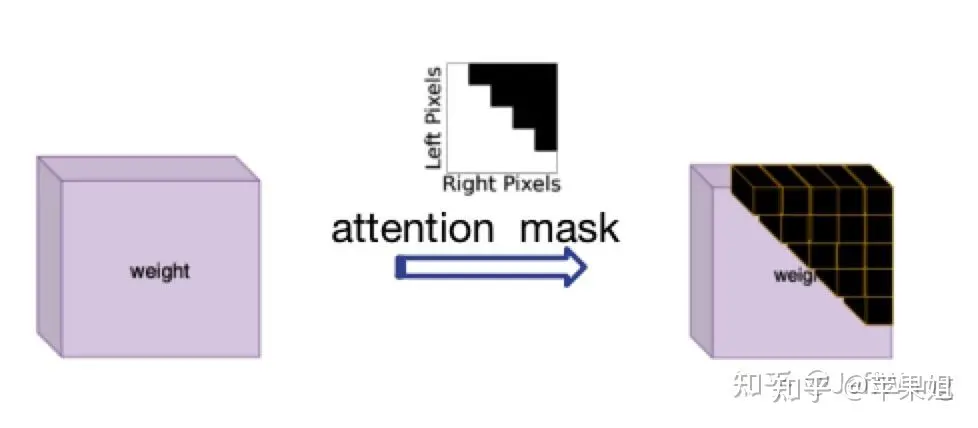 Picture
Picture
Attention mask diagram Because the logic of calculating attention_mask is a bit complicated, new problems may arise when converting many operations to TensorRT, so it should be calculated outside the model and entered as an input variable into the model, and then passed to the transformer. The following is a sample code:
data['attn_masks'] = attn_masks_init.clone().to(device)data['attn_masks'][active_prev_num:max_num, :] = Truedata['attn_masks'][:, active_prev_num:max_num] = True[1]DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
QIM is a post-processing module in MUTR3D for the query output by the transformer. It is mainly divided into three steps. The first step is to filter the active query, that is, in The query of the target detected in the current frame is based on whether obj_idxs >= 0 (the training phase also includes random drop query and random addition of fp query, which is not involved in the inference phase). The second step is update query, which is for the first step. Make an update to the filtered query, including the self-attention, ffn of the query output value, and the shortcut connection with the query input value. The third step is to splice the updated query with the regenerated initial query as the input of the next frame . It can be seen that the problem we mentioned in point 3 still exists in the second step, that is, self-attention does not interact with all queries, but only interacts with information between active queries. So it needs to be used here again attention mask.
Although the QIM module is optional, experiments show that it is helpful to improve the accuracy of the model. If you want to use QIM, this attention mask must be calculated in the model because it cannot be obtained outside the model. Know the detection results of the current frame. Due to the syntax limitations of tensorRT, many operations will either fail to convert, or will not get the desired results. After many experiments, the conclusion is to directly use index slice assignment (similar to the example in point 3 Code) operation is generally not supported. It is best to use matrix calculation, but when it comes to calculations, the bool type of the attention mask must be converted to the float type. Finally, the attention mask needs to be converted back to the bool type before it can be used. The following is an example code:
obj_mask = (obj_idxs >= 0).float()attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()attn_mask = ~attn_mask
After completing the above four points, we can basically ensure that there is no problem with the logic of model conversion tensorRT, but the output results still have problems in some frames after multiple verifications. This puzzles me. But if you analyze the data frame by frame, you will find that even though the padding query in some frames does not participate in the transformer calculation, it can get a higher score, and then get the wrong result. In this case It is indeed possible when the amount of data is large, because the padding query only has an initial value of 0, and the reference points are also [0,0], which performs the same operation as other randomly initialized queries. But since it is a padding query after all , we do not intend to use their results, so we must filter.
How to filter the results of the fill query? The tokens that populate the query are only their index positions, no other information is specific. The index information is actually recorded in the attention mask used in point 3, which is passed in from outside the model. This mask is two-dimensional, and we can use one of the dimensions (any row or column) to set the filled track_score directly to 0. Remember to still pay attention to the caveats in step 4, that is, try to use matrix calculations instead of indexed slice assignments, and the calculations must be converted to float type. The following is a code example:
mask = (~attention_mask[-1]).float()track_scores = track_scores * mask
In addition to the model body, there is actually a very critical step, which is to dynamically update track_id, which is what the model can achieve end-to-end. An important factor. But the way to update track_id in the original model is a relatively complex loop judgment, that is, if it is higher than score thresh and is a new target, assign a new obj_idx, and if it is lower than filter score thresh and is an old target, the corresponding disappear time 1, if the disappear time exceeds miss_tolerance, the corresponding obj idx is set to -1, that is, the target is discarded.
We know that tensorRT does not support if-else multi-branch statements (well, I started I don’t know), this is a headache. If the updated track_id is also placed outside the model, it will not only affect the end-to-end architecture of the model, but also make it impossible to use QIM, because QIM filters queries based on the updated track_id. So I racked my brains to put the updated track_id into the model.
Use your ingenuity again (almost running out), the if-else statement is not irreplaceable, such as using mask to operate in parallel. For example, conditional Convert to mask (for example, tensor[mask] = 0). Fortunately, although tensorRT mentioned in points 4 and 5 does not support index slice assignment operations, it does support bool index assignments. It is speculated that it may be because the slice operations are implicit. Change the shape of the tensor. However, after many experiments, bool index assignment is not supported in all cases. The following headaches have occurred:
需要重新写的内容是:赋值的值必须是一个,不能是多个。例如,当我更新新出现的目标时,我不会统一赋值为某个ID,而是需要为每个目标赋予连续递增的ID。我想到的解决办法是先统一赋值为一个比较大且不可能出现的数字,比如1000,以避免与之前的ID重复,然后在后续处理中将1000替换为唯一且连续递增的数字。(我真是个天才)
如果要进行递增操作(+=1),只能使用简单的掩码,即不能涉及复杂的逻辑计算。例如,对disappear_time的更新,本来需要同时判断obj_idx >= 0且track_scores = 0这个条件。虽然看似不合理,但经过分析发现,即使将obj_idx=-1的非目标的disappear_time递增,因为后续这些目标并不会被选入,所以对整体逻辑影响不大
综上,最后的动态更新track_id示例代码如下,在后处理环节要记得替换obj_idx为1000的数值.:
def update_trackid(self, track_scores, disappear_time, obj_idxs):disappear_time[track_scores >= 0.4] = 0obj_idxs[(obj_idxs == -1) & (track_scores >= 0.4)] = 1000disappear_time[track_scores 5] = -1
至此模型部分的处理就全部结束了,是不是比较崩溃,但是没办法,部署端到端模型肯定比一般模型要复杂很多.模型最后会输出固定shape的结果,还需要在后处理阶段根据obj_idx是否>0判断需要保留到下一帧的query,再根据track_scores是否>filter score thresh判断当前最终的输出结果.总体来看,需要在模型外进行的操作只有三步:帧间移动reference_points,对输入query进行padding,对输出结果进行过滤和转换格式,基本上实现了端到端的目标检测+目标跟踪.
需要重新写的内容是:以上六点的操作顺序需要说明一下。我在这里按照问题分类来写,实际上可能的顺序是1->2->3->5->6->4,因为第五点和第六点是使用QIM的前提,它们之间也存在依赖关系。另外一个问题是我没有使用memory bank,即时序融合的模块,因为经过实验发现这个模块的提升效果并不明显,而且对于端到端跟踪机制来说,已经天然地使用了时序融合(因为直接将前序帧的查询信息带到下一帧),所以时序融合并不是非常必要
好了,现在我们可以对比TensorRT的推理结果和PyTorch的推理结果,会发现在FP32精度下可以实现精度对齐,非常棒!但是,如果需要转换为FP16(可以大幅降低部署时延),第一次推理会发现结果完全变成None(再次崩溃)。导致FP16结果为None一般都是因为出现数据溢出,即数值大小超限(FP16最大支持范围是-65504~+65504)。如果你的代码使用了一些特殊的操作,或者你的数据天然数值较大,例如内外参、姿态等数据很可能超限,一般可以通过缩放等方式解决。这里再说一下和我以上6点相关的一个原因:
7.使用attention_mask导致的fp16结果为none的问题
这个问题非常隐蔽,因为问题隐藏在torch.nn.MultiheadAttention源码中,具体在torch.nn.functional.py文件中,有以下几句:
if attn_mask is not None and attn_mask.dtype == torch.bool:new_attn_mask = torch.zeros_like(attn_mask, dtype=q.dtype)new_attn_mask.masked_fill_(attn_mask, float("-inf"))attn_mask = new_attn_mask
可以看到,这一步操作是对attn_mask中值为True的元素用float("-inf")填充,这也是attention mask的原理所在,也就是值为1的位置会被替换成负无穷,这样在后续的softmax操作中,这个位置的输入会被加上负无穷,输出的结果就可以忽略不记,不会对其他位置的输出产生影响.大家也能看出来了,这个float("-inf")是fp32精度,肯定超过fp16支持的范围了,所以导致结果为none.我在这里把它替换为fp16支持的下限,即-65504,转fp16就正常了,虽然说一般不要修改源码,但这个确实没办法.不要问我怎么知道这么隐蔽的问题的,因为不是我一个人想到的.但如果使用attention_mask之前仔细研究了原理,想到也不难.
好的,以下是我在端到端模型部署方面的全部经验分享,我保证这不是标题党。由于我对tensorRT的接触时间不长,所以可能有些描述不准确的地方

需要进行改写的内容是:原文链接:https://mp.weixin.qq.com/s/EcmNH2to2vXBsdnNvpo0xw
The above is the detailed content of Practical deployment: Dynamic sequential network for end-to-end detection and tracking. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



