


The first Chinese-English bilingual voice dialogue open source large model is here!
In the past few days, a paper on a large-scale speech-text multi-modal model has appeared on arXiv, and the name of Kai-fu Lee’s large model company 01.ai - 01.ai - has appeared among the signature companies.
 Picture
Picture
This paper introduces a Chinese-English bilingual commercial dialogue model called LLaSM. This model not only supports recording and text input, but also can realize the function of "hybrid doubles"
 Picture
Picture
Research points out that "voice chat" is a combination of AI and A more convenient and natural way for people to interact is not just through text input
using large models. Some netizens are already imagining the scenario of "writing code while lying down and talking".
 Picture
Picture
This research was jointly completed by LinkSoul.AI, Peking University and 01Wanyuan. It is now open source and can be directly used in Try it out in Hugface
 Picture
Picture
Let’s see how it works
According to researchers, LLaSM is the first open source and commercially available dialogue model that supports Chinese and English bilingual speech-text multi-modal dialogue.
So, let’s take a look at its voice text input and Chinese-English bilingual capabilities.
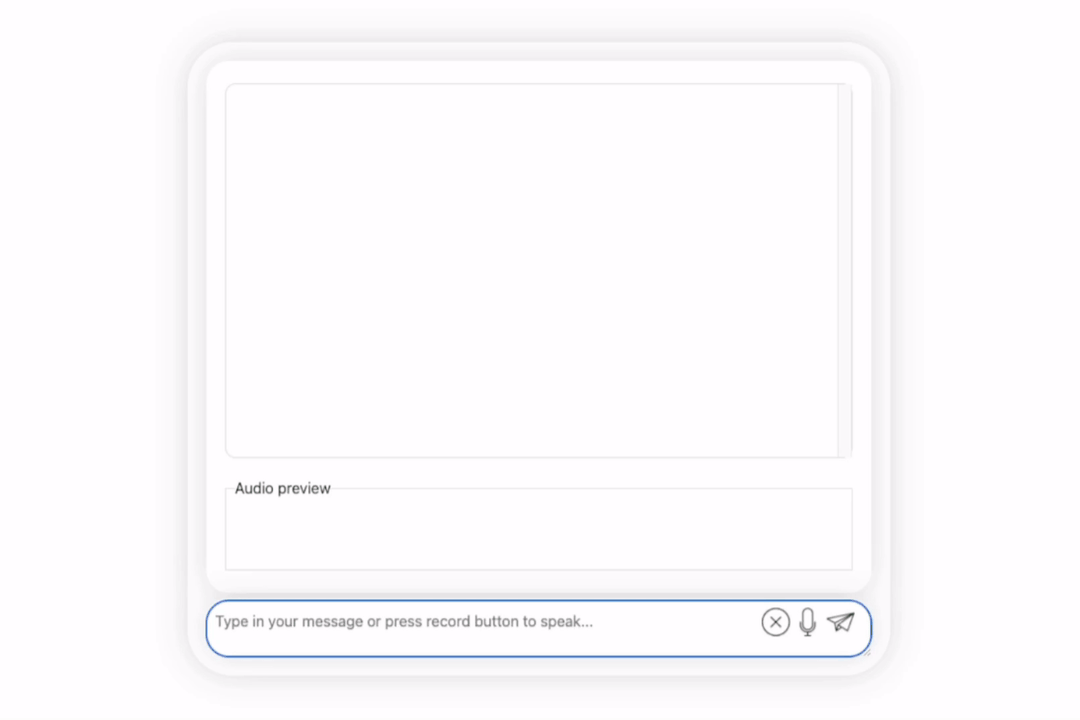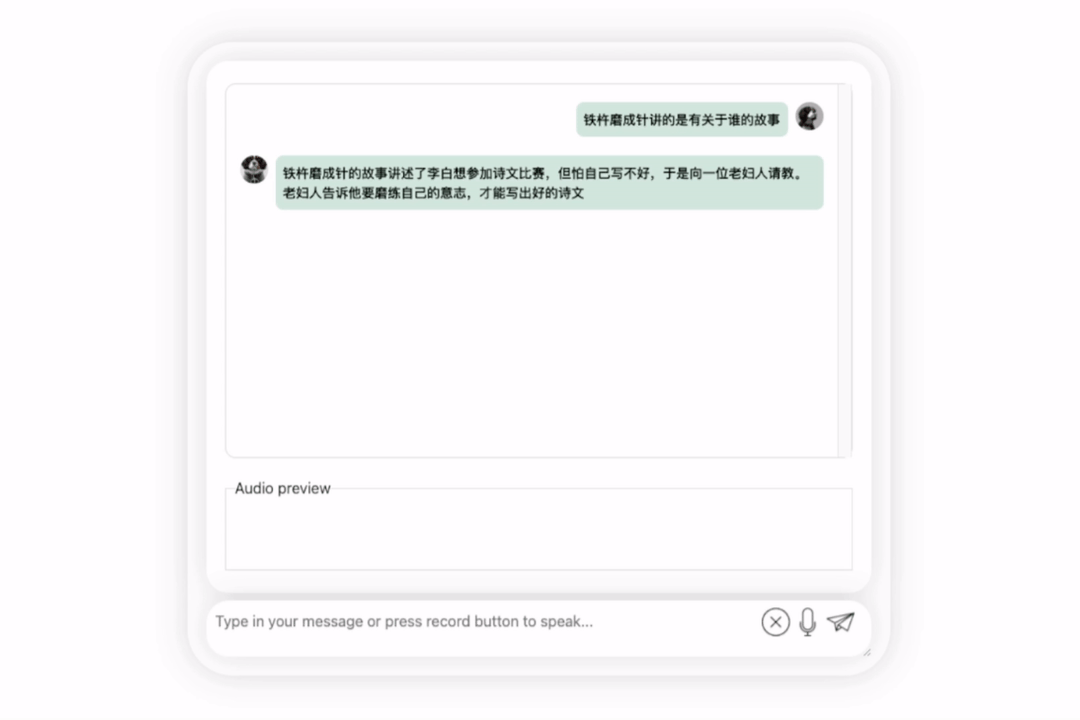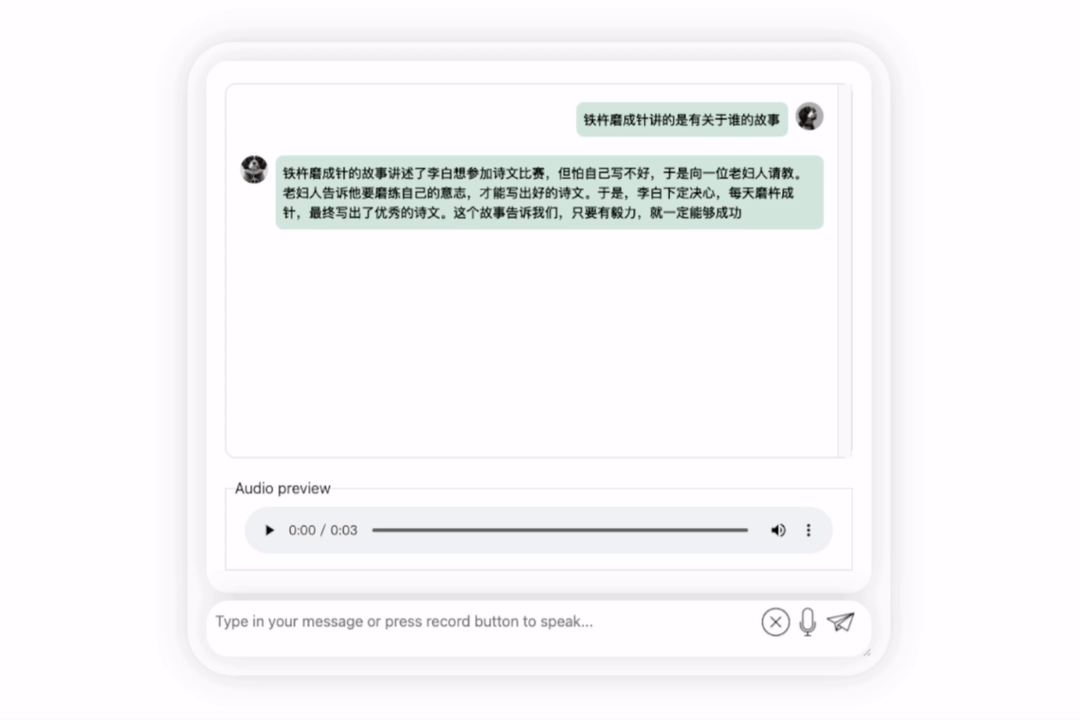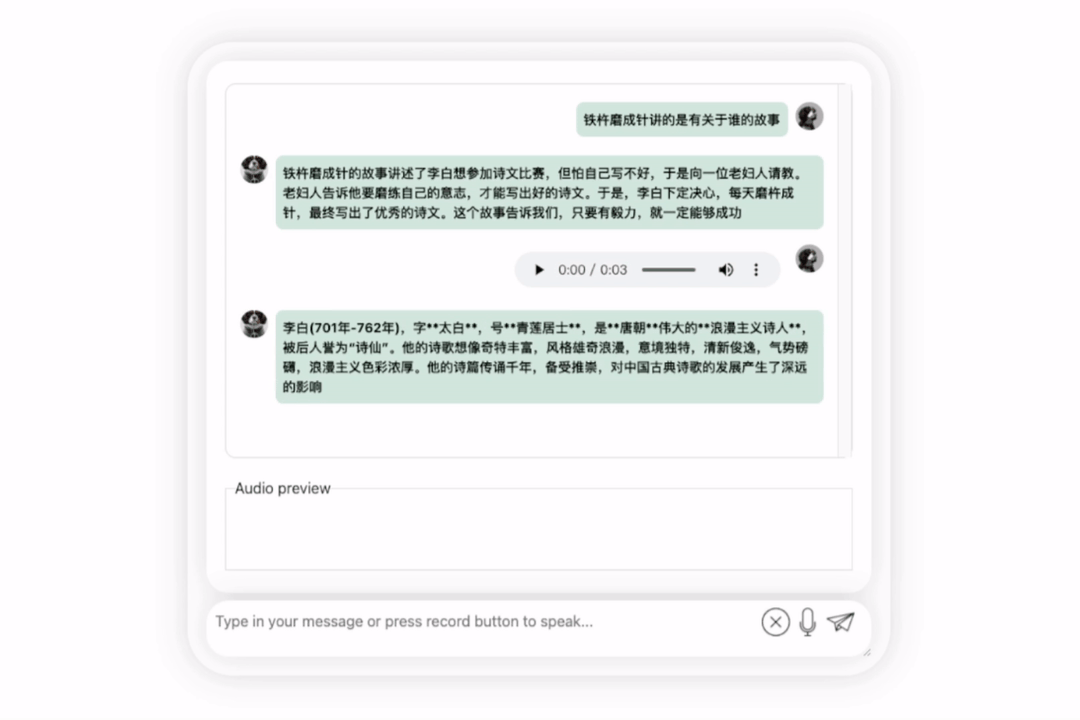
First of all, let us have a cultural collision between Chinese and English and evaluate Li Bai in English:
 Picture
Picture
It’s okay, correct Li Bai's dynasty was mentioned. If you can’t read English, it’s no problem to have it translated directly into Chinese:
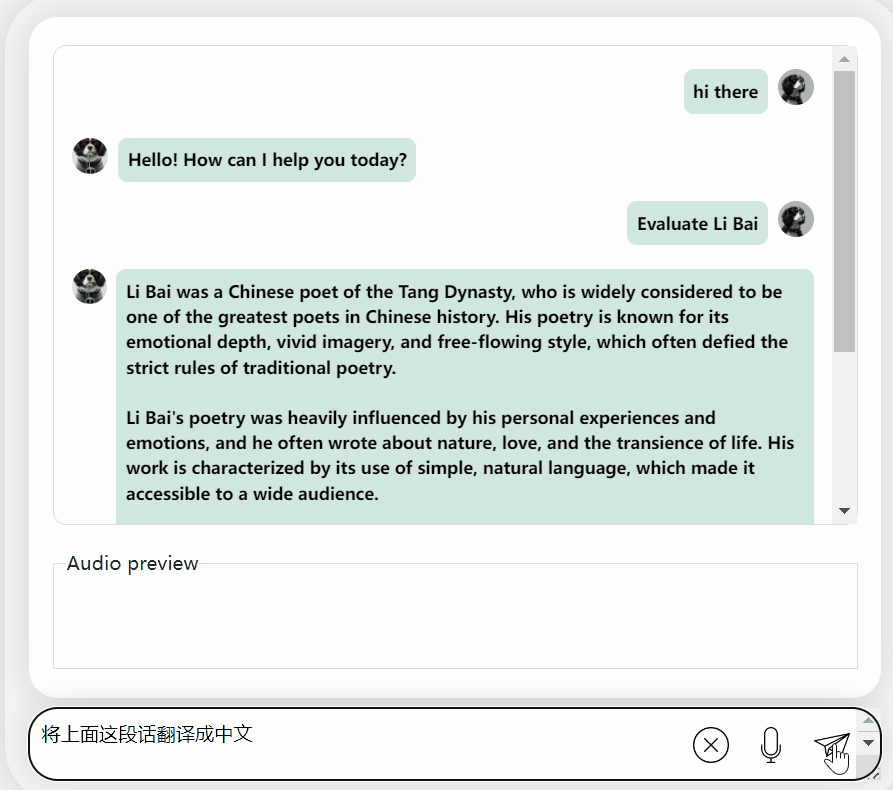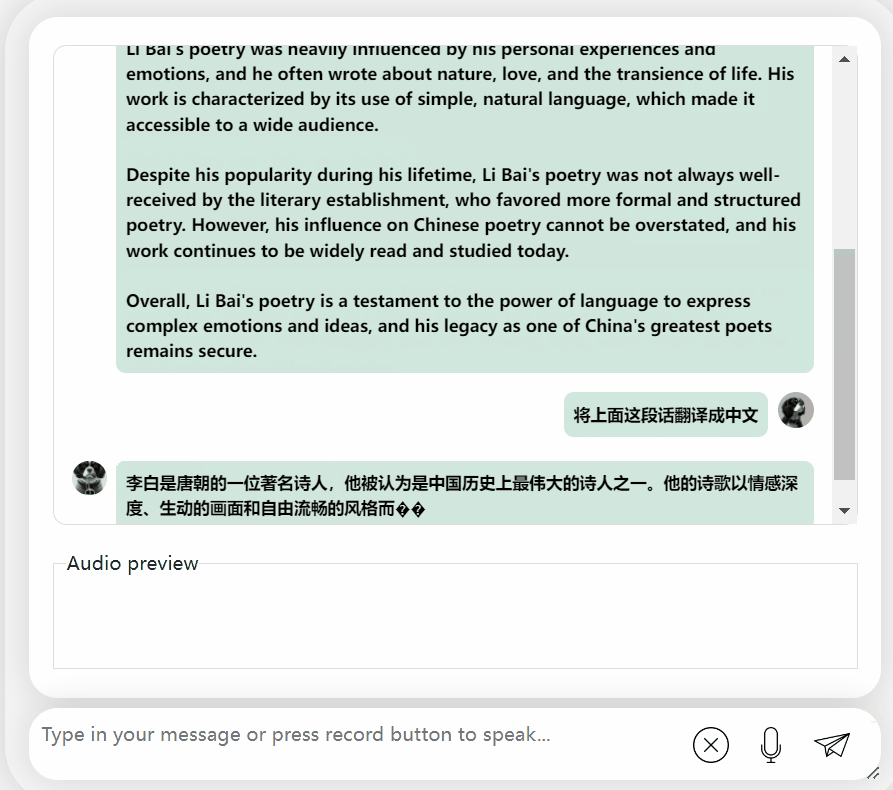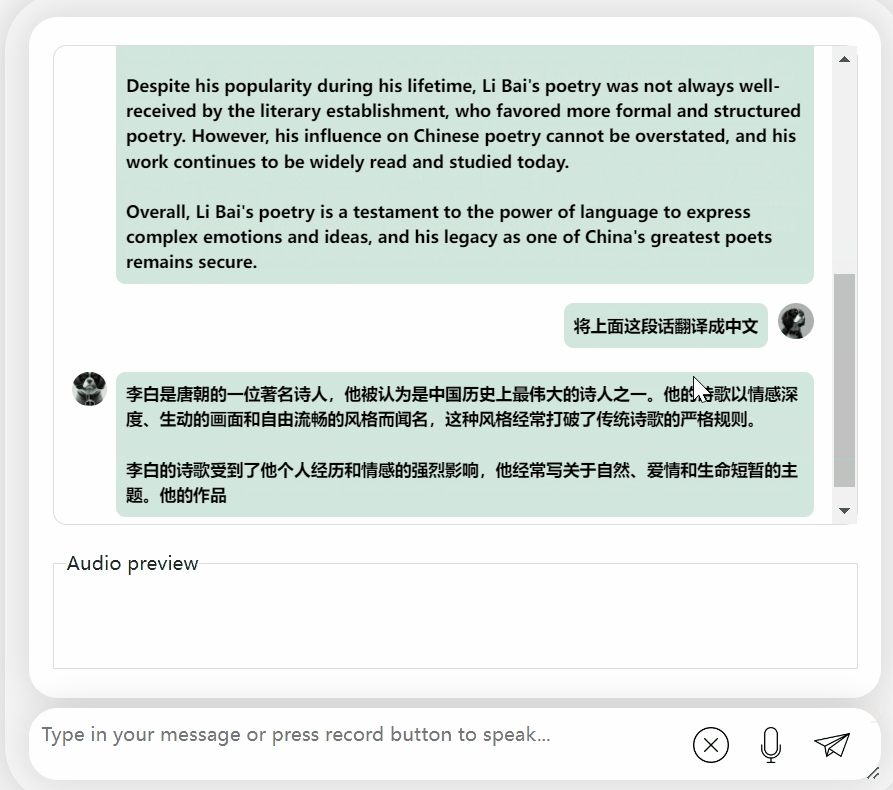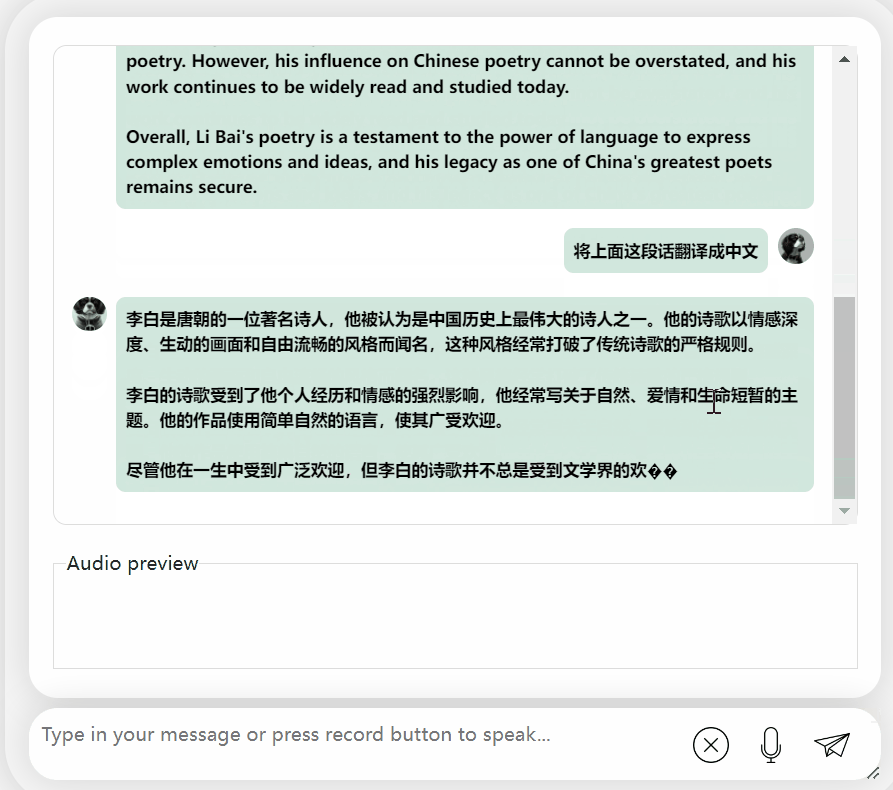 Picture
Picture
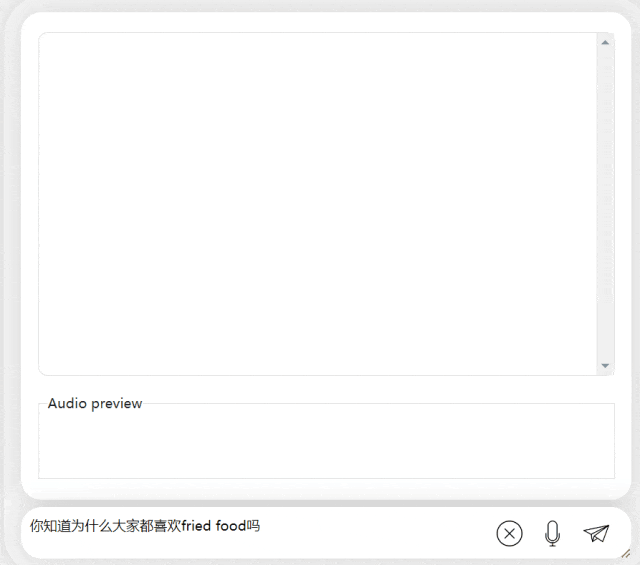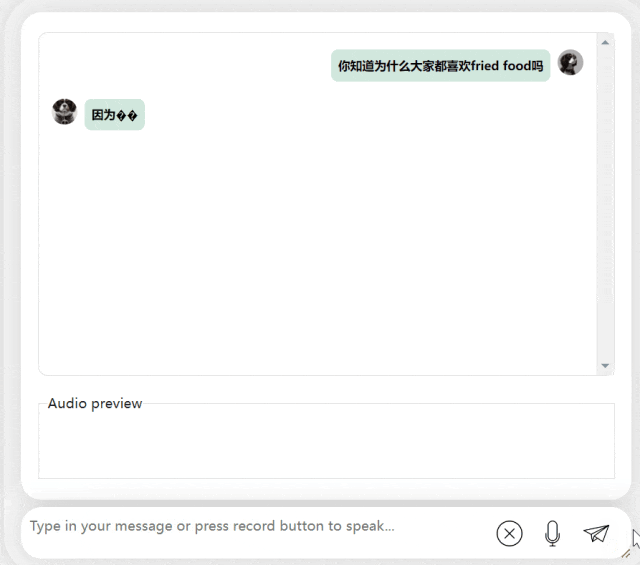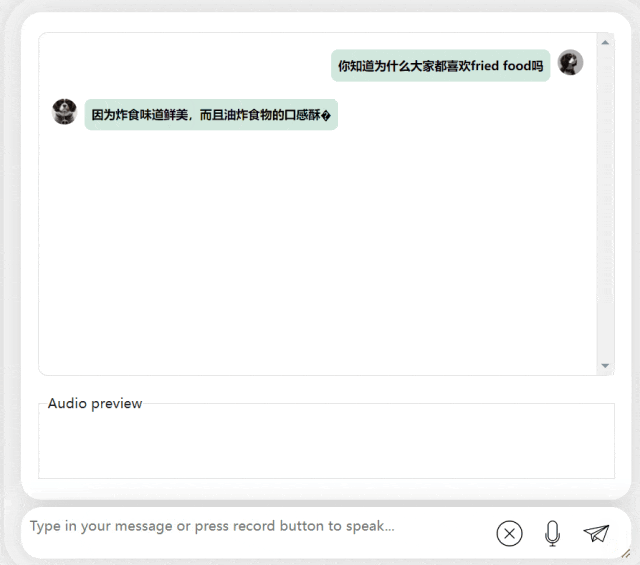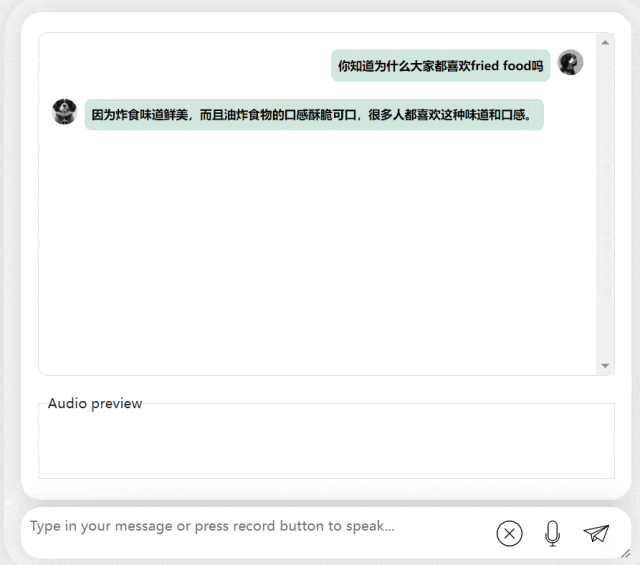
In the next exercise, let’s try Chinese A mixed-English question, adding the word "fried food" to a Chinese sentence. The output effect of the model is also quite good:
 Picture
Picture
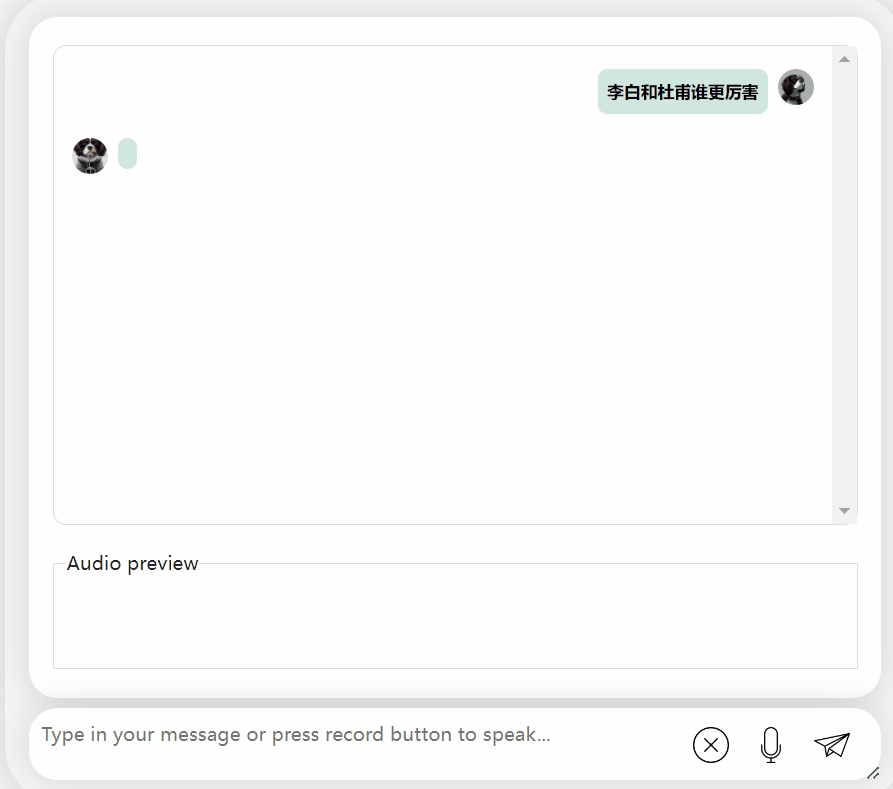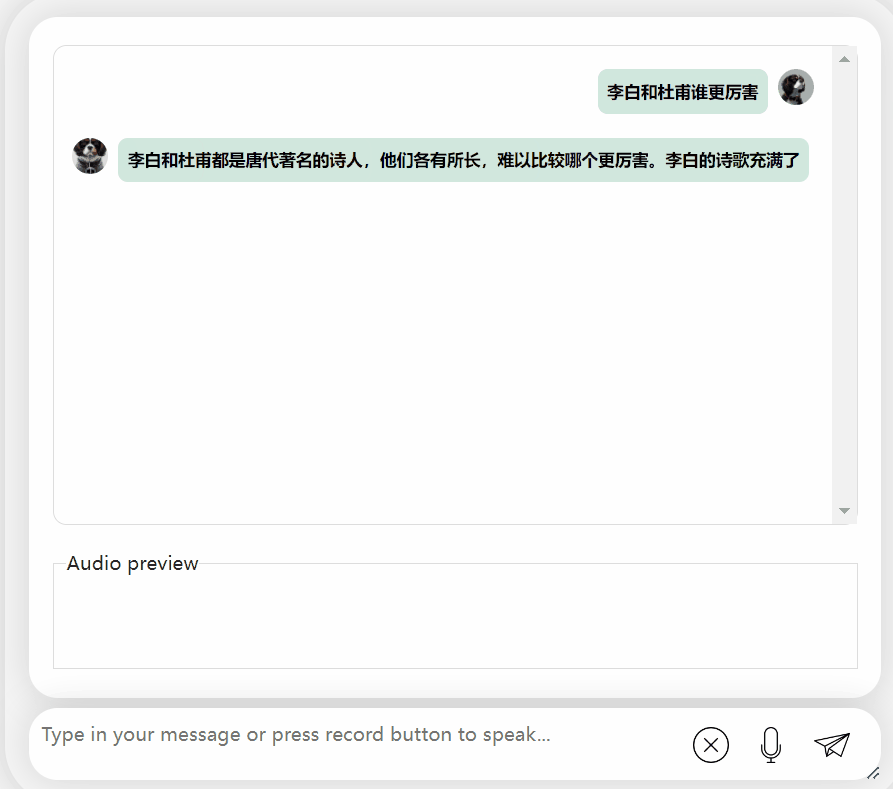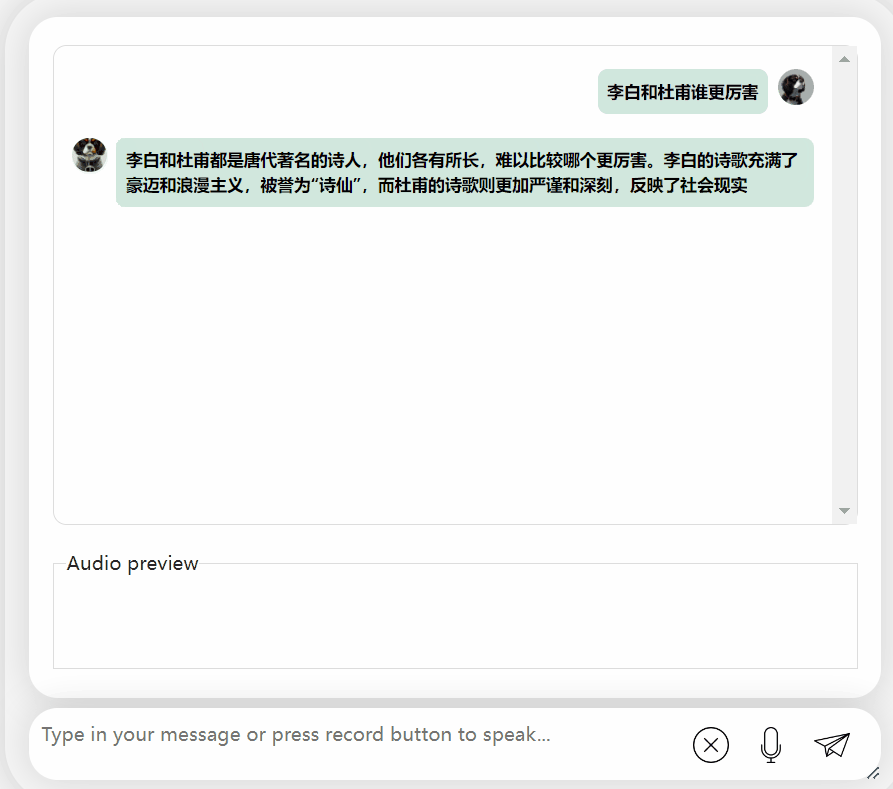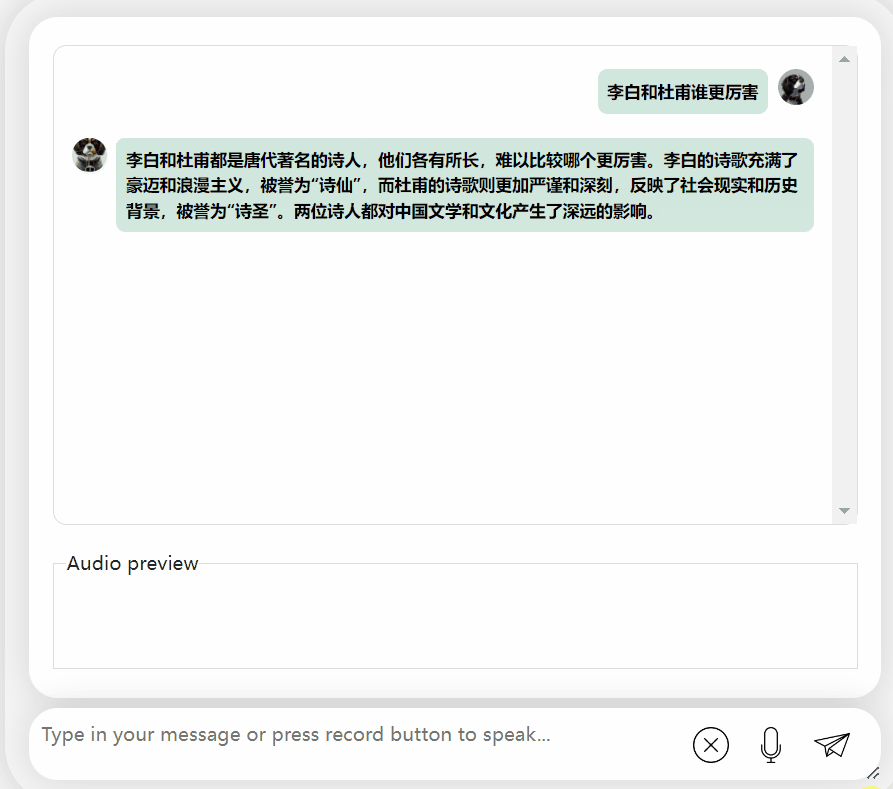
Let us try the model again and let it conduct some evaluations to see which one is better, Li Bai or Du Fu. Awesome
It can be observed that after a period of thinking, this model has given a very objective and neutral evaluation, and it also has the basic knowledge and common sense necessary for large models (manual dog head)
 Picture
Picture
Of course, it can be played not only on computers, but also on mobile phones.
Let’s try to input “recommend a recipe to me” using voice:
You can see that the model accurately outputs an “eggplant cheese” recipe, but I don’t know if it tastes good or not.
However, when we tried it, we also found that this model sometimes had bugs.
For example, sometimes it cannot "understand human speech" very well.
Requires output of mixed Chinese and English content, it will pretend not to understand and output in English:
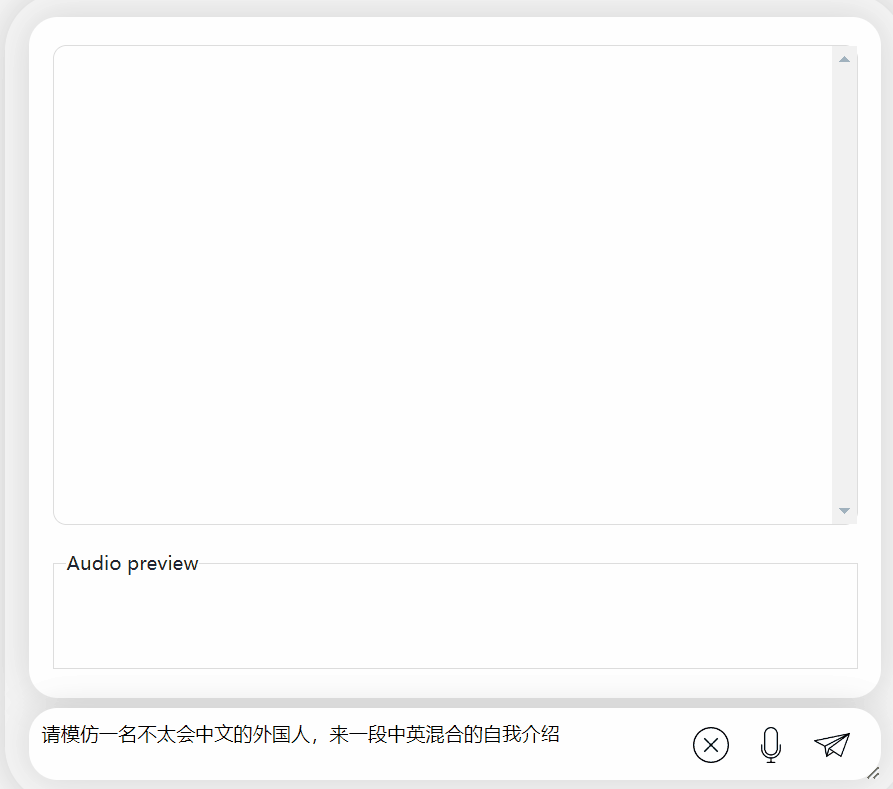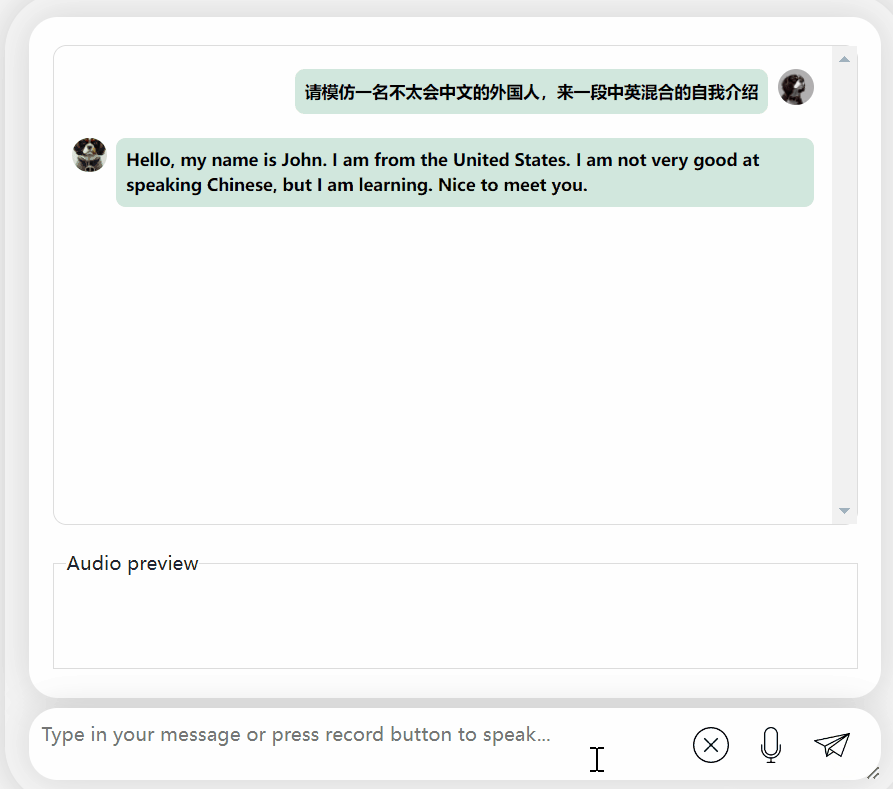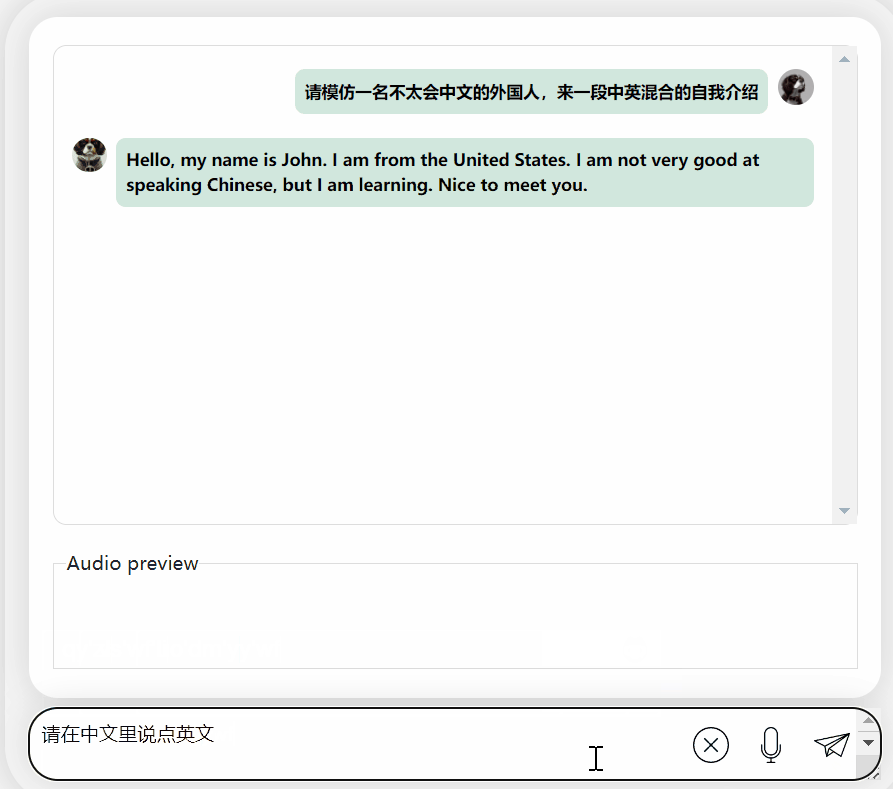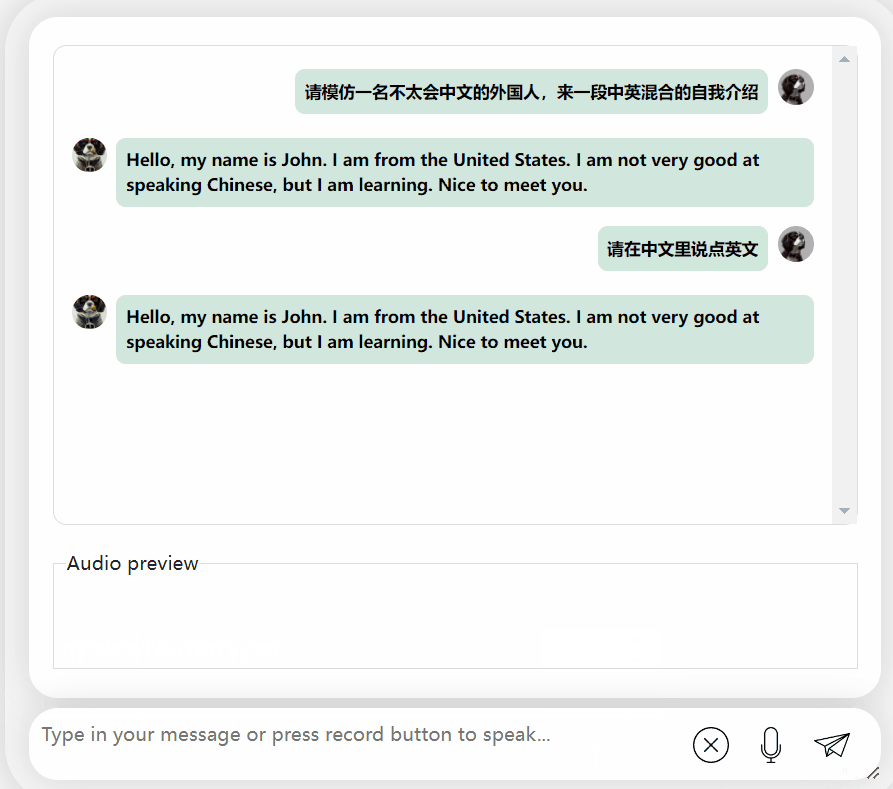 Picture
Picture
Mixed Chinese and English query When I want to listen to "Taylor Swift's Red", the model has a serious error. It keeps outputting the same sentence repeatedly and cannot even stop...
 Picture
Picture
Generally speaking, when encountering questions or requirements that are mixed in Chinese and English, the model output capability is still not very good.
But if separated, its ability to express Chinese and English is still good.
So, how is such a model implemented?
Judging from the trial, LLaSM has two main features: one is to support Chinese and English input, and the other is dual input of voice and text.
To achieve these two points, we need to make some adjustments to the architecture and training data respectively.
In terms of architecture, LLaSM integrates the current speech recognition model and the large language model.
LLaSM consists of three parts, including the automatic speech recognition model Whisper, the modal adapter and the large model LLaMA.
In this process, Whisper is responsible for receiving the original speech input and outputting a vector representation of the speech features. The role of the modal adapter is to align speech and text embeddings. LLaMA is responsible for understanding voice and text input instructions and generating replies
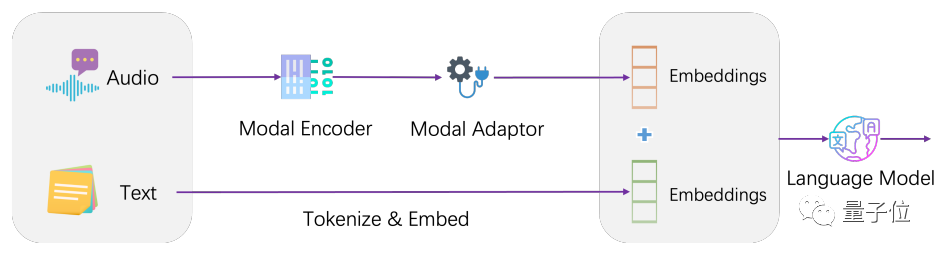 Picture
Picture
The training of the model is divided into two stages. The first stage is to train the modality adapter, where the encoder and large model are frozen, allowing the model to learn the alignment of speech and text. The second stage is to freeze the encoder, train modal adapters and large models to improve the model's multi-modal dialogue capabilities
On the training data, the researchers compiled a database containing 199,000 dialogues and 508,000 Dataset of speech-text samples LLaSM-Audio-Instructions.
Among the 508,000 speech-text samples, 80,000 are Chinese speech samples, while 428,000 are English speech samples
The researchers mainly based on WizardLM, ShareGPT and GPT-4 - Data sets such as LLM use text-to-speech technology to generate voice packets for these data sets while filtering out invalid conversations.
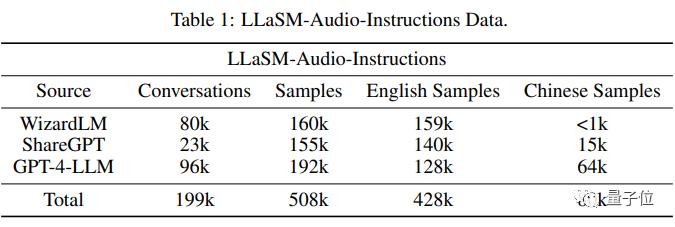 Picture
Picture
This is also the largest Chinese and English voice text instruction following data set, but it is still being sorted out. According to the researchers, it will be completed It will be open sourced later.
However, there is currently no comparison of the output effects of this paper with other speech models or text models
The authors of this paper are from LinkSoul.AI, Peking University Yu Shu and Siwei Dong, co-authors of Zero One Thing
, both come from LinkSoul.AI and previously worked at Beijing Zhiyuan Artificial Intelligence Research Institute.
LinkSoul.AI is an AI start-up company that has previously launched the first open source Llama 2 Chinese language large model.
 Picture
Picture
As a large model company under Kai-fu Lee, Zero One and One Wagon also contributed to this research. The Hugging Face page of the author Wenhao Huang shows that he graduated from Fudan University.
 Picture
Picture
Paper address:
//m.sbmmt.com/link/47c917b09f2bc64b2916c0824c715923
Demo address:
//m.sbmmt.com/link/bcd0049c35799cdf57d06eaf2eb3cff6
The above is the detailed content of A new large-scale voice dialogue model is launched in China: led by Kai-Fu Lee, with participation from Zero One and All, supporting Chinese and English bilingualism and multi-modality, open source and commercially available. For more information, please follow other related articles on the PHP Chinese website!
 How to solve the invalid mysql identifier error
How to solve the invalid mysql identifier error
 How to delete blank pages in word without affecting other formats
How to delete blank pages in word without affecting other formats
 js split usage
js split usage
 stripslashes function usage
stripslashes function usage
 How to copy an Excel table to make it the same size as the original
How to copy an Excel table to make it the same size as the original
 Introduction to the use of vscode
Introduction to the use of vscode
 Linux adds update source method
Linux adds update source method
 Basic usage of insert statement
Basic usage of insert statement








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



