


DriveLM is a language-based driver project that contains a data set and a model. With DriveLM, we introduce the inference capabilities of large language models in autonomous driving (AD) to make decisions and ensure explainable planning.
In DriveLM’s dataset, we use human-written reasoning logic as connections to facilitate perception, prediction, and planning (P3). In our model, we propose an AD visual language model with mind mapping capabilities to produce better planning results. Currently, we have released a demo version of the dataset, and the complete dataset and model will be released in the future
Project link: https://github.com/OpenDriveLab/DriveLM The content that needs to be rewritten is: Project link: https://github.com/OpenDriveLab/DriveLM
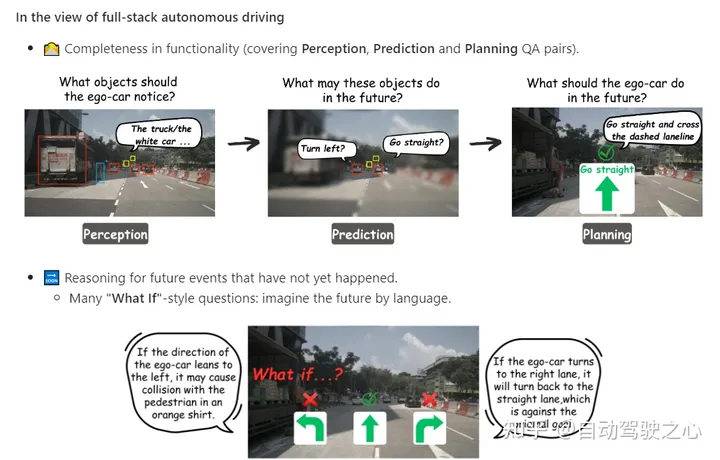

The most exciting aspect of the dataset is that the question answering (QA) in P3 is connected in a graph-style structure, with QA pairs as each node and the relationships of the objects as edges.
Compared to pure language thinking trees or thinking maps, we prefer multi-modality. In the AD domain, we do this because each stage defines the AD task, from raw sensor input to final control action

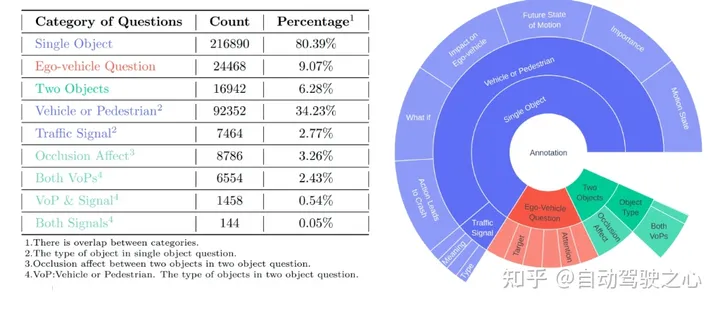
Build our dataset based on the mainstream nuScenes dataset. The core element of DriveLM is frame-based P3 QA. Perception problems require models to recognize objects in a scene. The prediction problem requires the model to predict the future state of important objects in the scene. Planning problems prompt the model to give reasonable planning actions and avoid dangerous actions.
The above is the detailed content of The key step for 'getting on the car' for large models: the world's first language + autonomous driving open source data set is here. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



