


In recent years, with the rise of artificial intelligence image generation tools represented by Midjourney and Stable Diffusion, 2D artificial intelligence image generation technology has become an integral part of many designs The auxiliary tools used by engineers in actual projects have been applied in various business scenarios, creating more and more practical value. At the same time, with the rise of the Metaverse, many industries are moving in the direction of creating large-scale 3D virtual worlds, and diverse, high-quality 3D content is becoming increasingly important for industries such as games, robotics, architecture, and social platforms. However, manually creating 3D assets is time-consuming and requires specific artistic and modeling skills. One of the main challenges is the issue of scale - despite the large number of 3D models that can be found on the 3D marketplace, populating a group of characters or buildings that all look different in a game or movie still requires a significant investment of artist time. As a result, the need for content creation tools that can scale in quantity, quality and diversity of 3D content has become increasingly evident
 Picture
Picture
Please look at Figure 1, which is a photo of the metaverse space (source: the movie "Wreck-It Ralph 2")
Thanks to the 2D generative model, realistic quality has been achieved in high-resolution image synthesis ,This progress has also inspired research on 3D content ,generation. Early methods aimed to directly extend 2D CNN generators to 3D voxel grids, but the high memory footprint and computational complexity of 3D convolutions hindered the generation process at high resolutions. As an alternative, other research has explored point cloud, implicit or octree representations. However, these works mainly focus on generating geometry and ignore appearance. Their output representations also need to be post-processed to make them compatible with standard graphics engines
In order to be practical for content production, the ideal 3D generative model should meet the following requirements:
Have The ability to generate shapes with geometric detail and arbitrary topology
Rewritten content: (b) The output should be a textured mesh, which is a common expression used by standard graphics software such as Blender and Maya
It is possible to use 2D images for supervision since they are more general than explicit 3D shapes
To facilitate the content creation process and enable Practical Applications, Generative 3D networks have become an active research area, capable of producing high-quality and diverse 3D assets. Every year, many 3D generative models are published at ICCV, NeurlPS, ICML and other conferences, including the following cutting-edge models
Textured3DGAN is a generative model that is an extension of the convolutional method of generating textured 3D meshes . It is able to learn to generate texture meshes from physical images using GANs under 2D supervision. Compared with previous methods, Textured3DGAN relaxes the requirements for key points in the pose estimation step and generalizes the method to unlabeled image collections and new categories/datasets, such as ImageNet
DIB-R : It is a differentiable renderer based on interpolation, using the PyTorch machine learning framework at the bottom. This renderer has been added to the 3D Deep Learning PyTorch GitHub repository (Kaolin). This method allows the analytical calculation of gradients for all pixels in the image. The core idea is to treat foreground rasterization as a weighted interpolation of local attributes and background rasterization as a distance-based aggregation of global geometry. In this way, it can predict information such as shape, texture, and light from a single image
PolyGen: PolyGen is an autoregressive generative model based on the Transformer architecture for directly modeling meshes. The model predicts the vertices and faces of the mesh in turn. We trained the model using the ShapeNet Core V2 dataset, and the results obtained are very close to the human-constructed mesh model
SurfGen: Adversarial 3D shape synthesis with an explicit surface discriminator. The end-to-end trained model is able to generate high-fidelity 3D shapes with different topologies.
GET3D is a generative model that can generate high-quality 3D textured shapes by learning images. Its core is differentiable surface modeling, differentiable rendering and 2D generative adversarial networks. By training on a collection of 2D images, GET3D can directly generate explicitly textured 3D meshes with complex topology, rich geometric details, and high-fidelity textures
 image
image
The content that needs to be rewritten is: Figure 2 GET3D generation model (Source: GET3D paper official website https://nv-tlabs.github.io/GET3D/)
GET3D is a recently proposed 3D generation model, which demonstrates state-of-the-art performance in unrestricted generation of 3D shapes by using ShapeNet, Turbosquid, and Renderpeople for multiple categories with complex geometries such as chairs, motorcycles, cars, people, and buildings
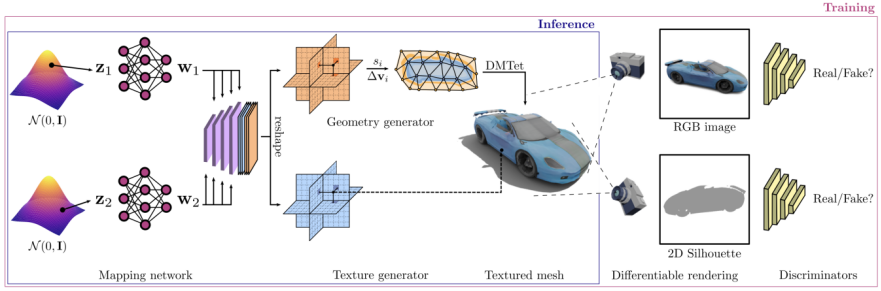 Picture
Picture
The GET3D architecture comes from the GET3D paper official website, Figure 3 shows This architecture
generates a 3D SDF (Directed Distance Field) and a texture field through two latent encodings, and then uses DMTet (Deep Marching Tetrahedra) to extract the 3D surface mesh from the SDF and add it to the surface points The cloud queries the texture field to get the color. The entire process is trained using an adversarial loss defined on 2D images. In particular, RGB images and contours are obtained using a rasterization-based differentiable renderer. Finally, two 2D discriminators are used, each for RGB images and contours, to distinguish whether the input is real or fake. The entire model can be trained end-to-end
GET3D is also very flexible in other aspects and can be easily adapted to other tasks in addition to explicit meshes as output expressions, including:
Geometry and texture separation implementation: A good decoupling is achieved between the geometry and texture of the model, allowing meaningful interpolation of geometry latent codes and texture latent codes
Smooth transitions between generating different categories of shapes When , it can be achieved by performing a random walk in the latent space and generating the corresponding 3D shape
Generating new shapes: You can perturb the local latent code by adding some small noise to generate a look-alike Similar but locally slightly different shapes
Unsupervised material generation: By combining with DIBR, materials are generated in a completely unsupervised manner and produce meaningful view-dependent lighting effects
To Text-guided shape generation: By combining StyleGAN NADA to fine-tune the 3D generator with a directional CLIP loss on computationally rendered 2D images and user-supplied text, users can generate a large number of meaningful shapes with text prompts
 Picture
Picture
Please refer to Figure 4, which shows the process of generating shapes based on text. The source of this figure is the official website of GET3D paper, the URL is https://nv-tlabs.github.io/GET3D/
Although GET3D has been Although the generation model of practical 3D texture shapes has taken an important step, it still has some limitations. In particular, the training process still relies on the knowledge of 2D silhouettes and camera distributions. Therefore, currently GET3D can only be evaluated based on synthetic data. A promising extension is to leverage advances in instance segmentation and camera pose estimation to alleviate this problem and extend GET3D to real-world data. GET3D is currently only trained by category, and will be expanded to multiple categories in the future to better represent the diversity between categories. It is hoped that this research will bring people one step closer to using artificial intelligence to freely create 3D content
The above is the detailed content of An in-depth five-minute technical talk about GET3D's generative models. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



