


In recent years, great progress has been made in the field of image generation, especially in text-to-image generation: as long as we use text to describe our thoughts, AI can generate novel and realistic images.
But in fact we can go one step further - the step of converting the thoughts in the mind into text can be omitted and controlled directly through brain activity (such as EEG (electroencephalogram) recording) Generative creation of images.
This "thinking-to-image" generation method has broad application prospects. For example, it can greatly improve the efficiency of artistic creation and help people capture fleeting inspiration; it may also be possible to visualize people's dreams at night; it may even be used in psychotherapy to help autistic children and language disorders patient.
Recently, researchers from Tsinghua University Shenzhen International Graduate School, Tencent AI Lab and Pengcheng Laboratory jointly published a research paper on "Thinking to Image", using pre- The powerful generation capabilities of trained text-to-image models (such as Stable Diffusion) generate high-quality images directly from EEG signals.
 Picture
Picture
Paper address: https://arxiv.org/pdf/2306.16934.pdf
Project address: https://github.com/bbaaii/DreamDiffusion
Some recent related research (e.g. MinD-Vis) attempts to reconstruct visual information based on fMRI (functional magnetic resonance imaging signals). They have demonstrated the feasibility of using brain activity to reconstruct high-quality results. However, these methods are still far from the ideal use of brain signals for fast and efficient creation. This is mainly due to two reasons:
First, fMRI equipment is not portable and requires It is operated by professionals, so it is difficult to capture fMRI signals;
Secondly, the cost of fMRI data collection is high, which will greatly hinder the use of this method in actual artistic creation. .
In contrast, EEG is a non-invasive, low-cost method of recording brain electrical activity, and there are now portable commercial products on the market that can obtain EEG signals.
However, there are still two main challenges in realizing the generation of "thoughts to images":
1) EEG signals are generated through non-invasive methods to capture, so it is noisy in nature. In addition, EEG data are limited and individual differences cannot be ignored. So, how to obtain effective and robust semantic representations from EEG signals under so many constraints?
2) Text and image spaces in Stable Diffusion are well aligned due to the use of CLIP and training on a large number of text-image pairs. However, EEG signals have their own characteristics and their space is quite different from text and images. How to align EEG, text and image spaces on limited and noisy EEG - image pairs?
To address the first challenge, this study proposes to use large amounts of EEG data to train EEG representations instead of only rare EEG image pairs. This study uses a masked signal modeling method to predict missing tokens based on contextual clues.
Different from MAE and MinD-Vis, which treat the input as a two-dimensional image and mask spatial information, this study considers the temporal characteristics of the EEG signal and digs deeper into the temporal changes in the human brain semantics. This study randomly blocked a portion of tokens and then reconstructed these blocked tokens in the time domain. In this way, the pre-trained encoder is able to develop a deep understanding of EEG data from different individuals and different brain activities.
For the second challenge, previous solutions usually fine-tune the Stable Diffusion model directly, using a small number of noisy data pairs for training. However, it is difficult to learn accurate alignment between brain signals (e.g., EEG and fMRI) and text space by only fine-tuning SD end-to-end with the final image reconstruction loss. Therefore, the research team proposed using additional CLIP supervision to help achieve alignment of EEG, text, and image spaces.
Specifically, SD itself uses CLIP’s text encoder to generate text embeddings, which is very different from the masked pre-trained EEG embeddings of the previous stage. Leverage CLIP's image encoder to extract rich image embeddings that are well aligned with CLIP's text embeddings. These CLIP image embeddings were then used to further refine the EEG embedding representation. Therefore, the improved EEG feature embeddings can be well aligned with CLIP's image and text embeddings and are more suitable for SD image generation, thereby improving the quality of the generated images.
Based on the above two carefully designed solutions, this study proposes a new method DreamDiffusion. DreamDiffusion generates high-quality and realistic images from electroencephalogram (EEG) signals.
 Picture
Picture
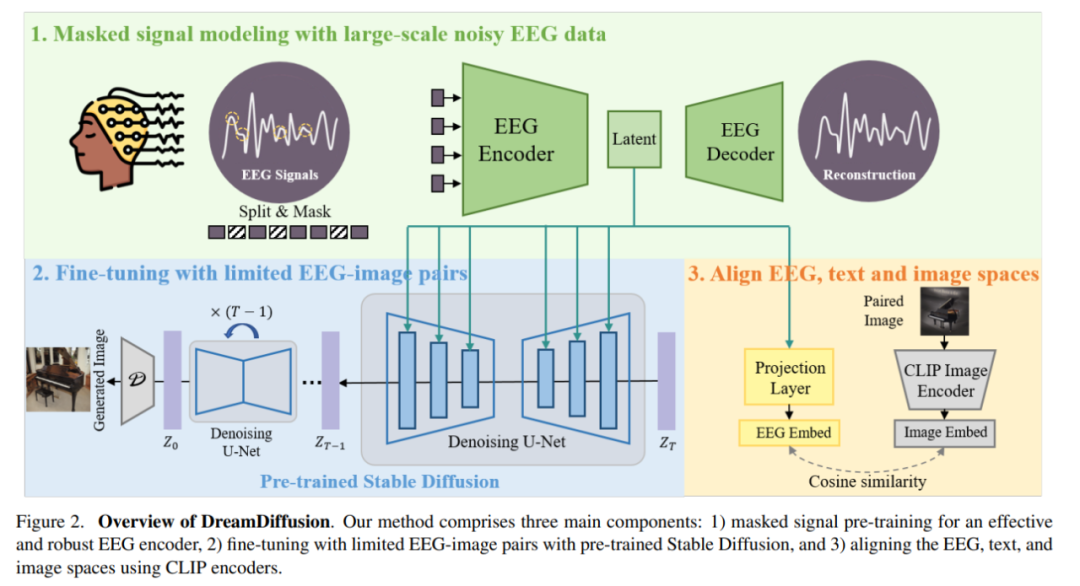
Specifically, DreamDiffusion mainly consists of three parts:
1) Mask signal pre-training to achieve effective and robust EEG encoder;
2) Use pre-trained Stable Diffusion and limited EEG image pairs for fine-tuning;
3) Use the CLIP encoder to align EEG, text and image spaces.
First, the researchers used EEG data with a lot of noise, used mask signal modeling, trained the EEG encoder, and extracted contextual knowledge. The resulting EEG encoder is then used to provide conditional features for Stable Diffusion via a cross-attention mechanism.
 Picture
Picture
#In order to enhance the compatibility of EEG features with Stable Diffusion, the researchers further reduced the EEG embedding in the fine-tuning process The distance from CLIP image embeddings further aligns the embedding spaces of EEG, text and images.
Comparison with Brain2Image
Researchers Compare this article's method with Brain2Image. Brain2Image uses traditional generative models, namely variational autoencoders (VAEs) and generative adversarial networks (GANs), for conversion from EEG to images. However, Brain2Image only provides results for a few categories and does not provide a reference implementation.
With this in mind, this study performed a qualitative comparison of several categories presented in the Brain2Image paper (i.e., airplanes, jack-o-lanterns, and pandas). To ensure a fair comparison, the researchers used the same evaluation strategy as described in the Brain2Image paper and show the results generated by the different methods in Figure 5 below.
The first row of the figure below shows the results generated by Brain2Image, and the last row is generated by DreamDiffusion, the method proposed by the researchers. It can be seen that the image quality generated by DreamDiffusion is significantly higher than that generated by Brain2Image, which also verifies the effectiveness of this method.
 Picture
Picture
Ablation experiment
The role of pre-training: In order to prove the effectiveness of large-scale EEG data pre-training, this study used untrained encoders to train multiple models for verification. One of the models was identical to the full model, while the other model had only two EEG coding layers to avoid overfitting the data. During the training process, the two models were trained with/without CLIP supervision, and the results are shown in columns 1 to 4 of the Model in Table 1. It can be seen that the accuracy of the model without pre-training is reduced.
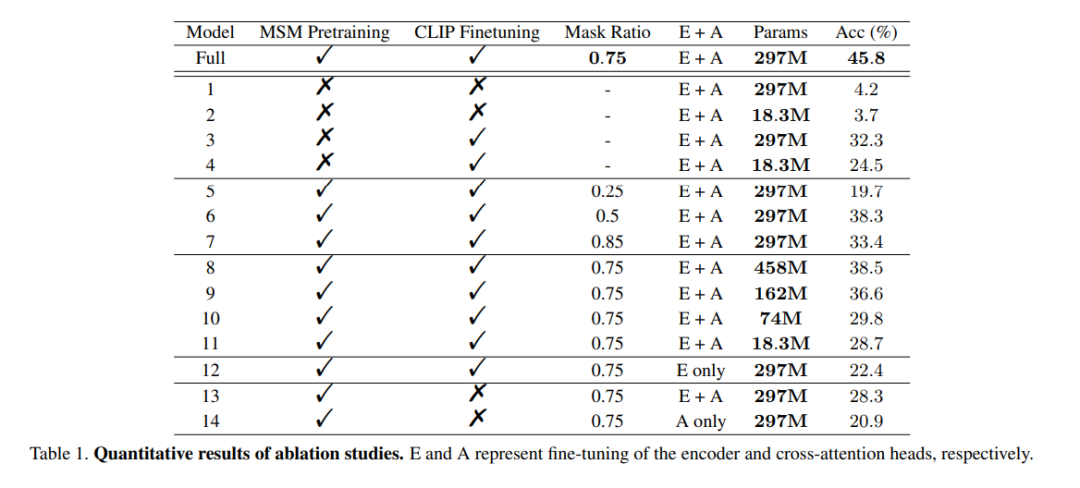
mask ratio: This article also studies the use of EEG data to determine the best MSM pre-training Mask ratio. As shown in columns 5 to 7 of the Model in Table 1, a mask ratio that is too high or too low can adversely affect model performance. The highest overall accuracy is achieved when the mask ratio is 0.75. This finding is crucial because it suggests that, unlike natural language processing, which typically uses low mask ratios, high mask ratios are a better choice when performing MSM on EEG.
CLIP Alignment: One of the keys to this approach is the alignment of the EEG representation to the image via a CLIP encoder. This study conducted experiments to verify the effectiveness of this method, and the results are shown in Table 1. It can be observed that the performance of the model drops significantly when CLIP supervision is not used. In fact, as shown in the lower right corner of Figure 6, using CLIP to align EEG features can still yield reasonable results even without pre-training, which highlights the importance of CLIP supervision in this method.
 picture
picture
The above is the detailed content of The picture in your brain can now be restored in high definition. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



