


The voice world in which AI participates is really magical. It can not only change one person's voice to that of any other person, but also exchange voices with animals.
We know that the goal of speech conversion is to convert the source speech into the target speech while keeping the content unchanged. Recent any-to-any speech conversion methods improve naturalness and speaker similarity, but at the expense of greatly increased complexity. This means that training and inference become more expensive, making improvements difficult to evaluate and establish.
The question is, does high-quality speech conversion require complexity? In a recent paper from the University of Stellenbosch in South Africa, several researchers explored this issue.

The research highlights are: They introduced K nearest neighbor speech conversion ( kNN-VC), a simple and powerful any-to-any speech conversion method. Instead of training an explicit transformation model, K-nearest neighbor regression is simply used.
Specifically, the researchers first used a self-supervised speech representation model to extract the feature sequence of the source utterance and the reference utterance, and then replaced each frame of the source representation with one in the reference. nearest neighbor to convert to the target speaker, and finally use a neural vocoder to synthesize the converted features to obtain the converted speech.
From the results, despite its simplicity, KNN-VC achieves comparable or even improved intelligibility in both subjective and objective evaluations compared to several baseline speech conversion systems Similarity to the speaker.
Let’s appreciate the effect of KNN-VC voice conversion. Looking first at human voice conversion, KNN-VC is applied to source and target speakers unseen in the LibriSpeech dataset.
Source voice00:11
##Synthetic voice 100:11
Synthetic Speech 200:11
KNN-VC also supports cross-language speech conversion, such as Spanish to German, German to Japanese, Chinese to Spanish.
Source Chinese00:08
Destination Spanish00:05
Synthetic Speech 300:08
What’s even more amazing is that KNN-VC can also combine human voices with dogs Bark swap.
Source Dog Barking00:09
Source Human Voice00:05
Synthetic Voice 400:08
##Synthetic Voice 500:05We next look at how KNN-VC runs and compares it with other jixian methods.
Method Overview and Experimental Results
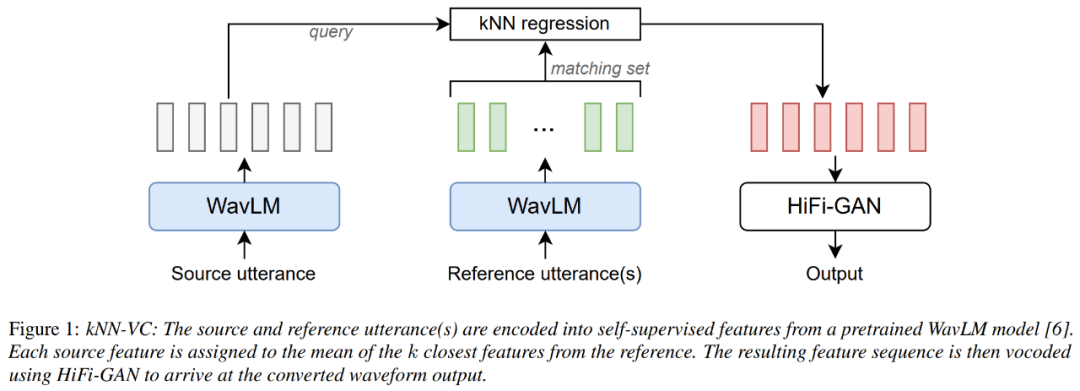
The encoder uses WavLM, the converter uses K nearest neighbor regression, and the vocoder uses HiFiGAN. The only component that requires training is the vocoder.
For the WavLM encoder, the researcher only used the pre-trained WavLM-Large model and did not do any training on it in the article. For the kNN transformation model, kNN is non-parametric and does not require any training. For the HiFiGAN vocoder, the original HiFiGAN author's repo was used to vocode the WavLM features, becoming the only part that required training.
Picture
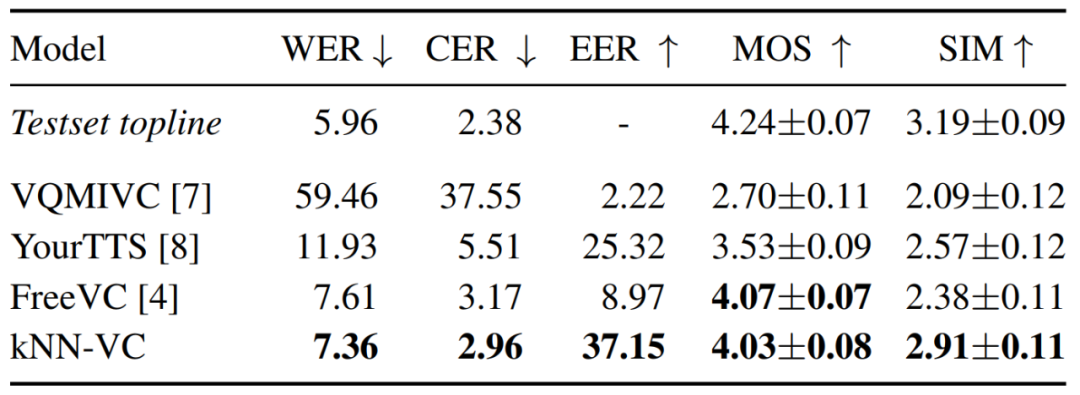
 In the experiment, the researchers first compared KNN-VC with other baseline methods, using the maximum available Target data (approximately 8 minutes of audio per speaker) to test the speech conversion system.
In the experiment, the researchers first compared KNN-VC with other baseline methods, using the maximum available Target data (approximately 8 minutes of audio per speaker) to test the speech conversion system.
For KNN-VC, the researcher uses all target data as the matching set. For the baseline method, they average speaker embeddings for each target utterance.
Table 1 below reports the results for intelligibility, naturalness, and speaker similarity for each model. As can be seen, kNN-VC achieves similar naturalness and clarity to the best baseline FreeVC, but with significantly improved speaker similarity. This also confirms the assertion of this article: high-quality speech conversion does not require increased complexity.
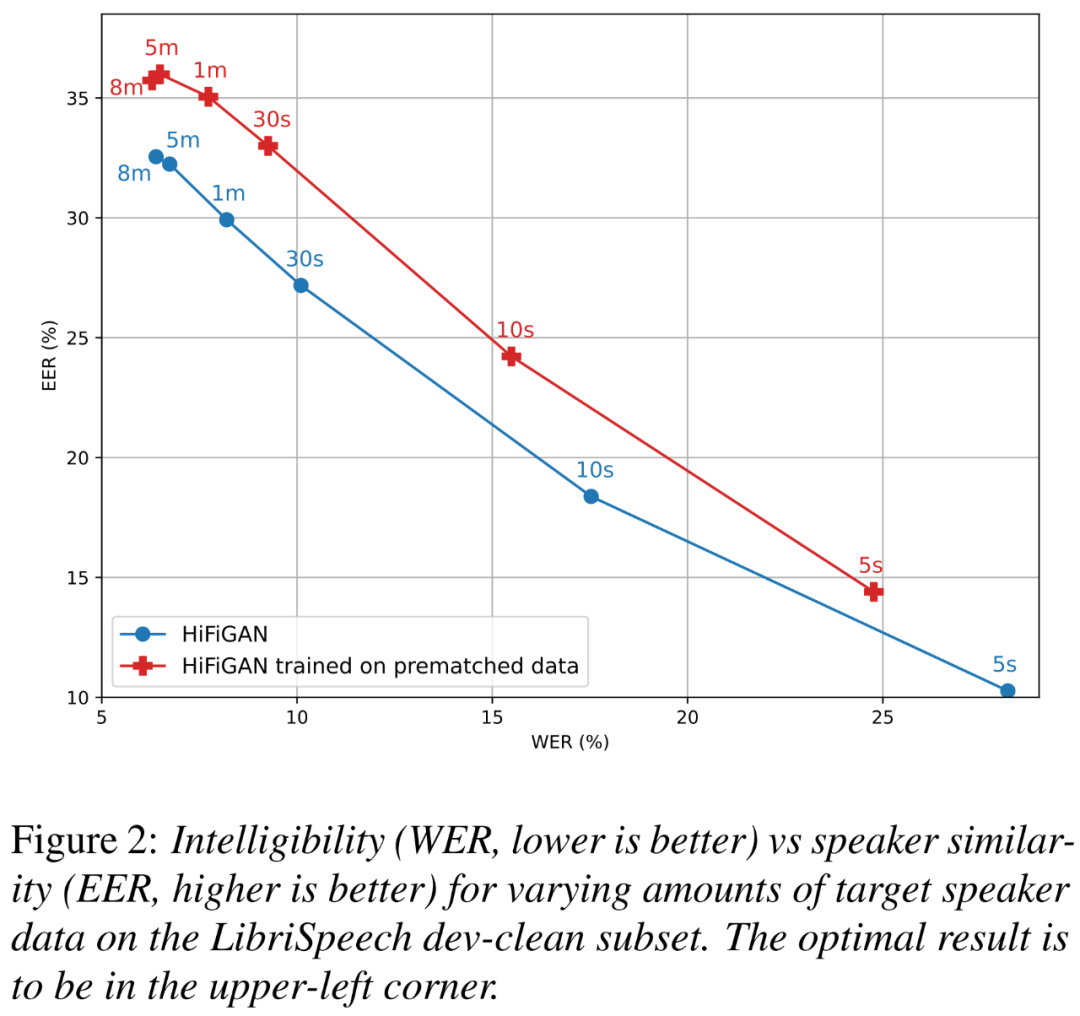
In addition, the researchers wanted to understand how much of the improvement was due to HiFi-GAN trained on pre-matched data, as well as target speaker data How much does size affect intelligibility and speaker similarity.
Figure 2 below shows the relationship between WER (smaller is better) and EER (higher is better) for two HiFi-GAN variants at different target speaker sizes.
 Picture
Picture
For this "only use nearest neighbors" "'s new speech conversion method kNN-VC, some people think that the pre-trained speech model is used in the article, so using "only" is not accurate. But it is undeniable that kNN-VC is still simpler than other models.
The results also demonstrate that kNN-VC is equally effective, if not the best, compared to very complex any-to-any speech conversion methods.
 Picture
Picture
Some people also said that the example of interchange of human voice and dog barking is very interesting.
 picture
picture
The above is the detailed content of How amazing is the simple speech conversion model that supports cross-language, human voice and dog barking interchange, and only uses nearest neighbors?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



