


The outbreak of AIGC not only brings computing power challenges, but also places unprecedented demands on the network.
On June 26, Tencent Cloud fully disclosed its self-developed Xingmai high-performance computing network for the first time: Xingmai network has the industry’s highest 3.2T communication bandwidth, which can increase GPU utilization by 40% and save 30%~60%. The model training cost brings 10 times communication performance improvement to large AI models. Tencent Cloud's new generation computing cluster HCC can support a huge computing scale of more than 100,000 cards.
Wang Yachen, Vice President of Tencent Cloud, said: "Xingmai Network is born for large models. The high-performance network services it provides with large bandwidth, high utilization and zero packet loss will help break through the computing power bottleneck and further Release the potential of AI, comprehensively improve the training efficiency of enterprise large models, and accelerate the iterative upgrade and implementation of large model technology on the cloud."
Build a high-performance network dedicated to large models and increase GPU utilization by 40%
The popularity of AIGC has brought about a surge in the number of large AI model parameters from hundreds of millions to trillions. In order to support large-scale training of massive data, a large number of servers form a computing cluster through high-speed networks and are interconnected to complete training tasks together.
On the contrary, the larger the GPU cluster, the greater the additional communication loss. A large cluster does not mean large computing power. The era of AI large models has brought significant challenges to the network, including high bandwidth requirements, high utilization, and information losslessness.
Traditional low-speed network bandwidth cannot satisfy large models with hundreds of billions or trillions of parameters. During the training process, the proportion of communication can be as high as 50%. At the same time, traditional network protocols can easily lead to network congestion, high latency and packet loss, and only 0.1% of network packet loss may lead to 50% loss of computing power, ultimately resulting in a serious waste of computing power resources.
Based on comprehensive self-research capabilities, Tencent Cloud has carried out software and hardware upgrades and innovations in switches, communication protocols, communication libraries, and operation systems, and is the first to launch the industry's leading large-model dedicated high-performance network - Xingmai network.
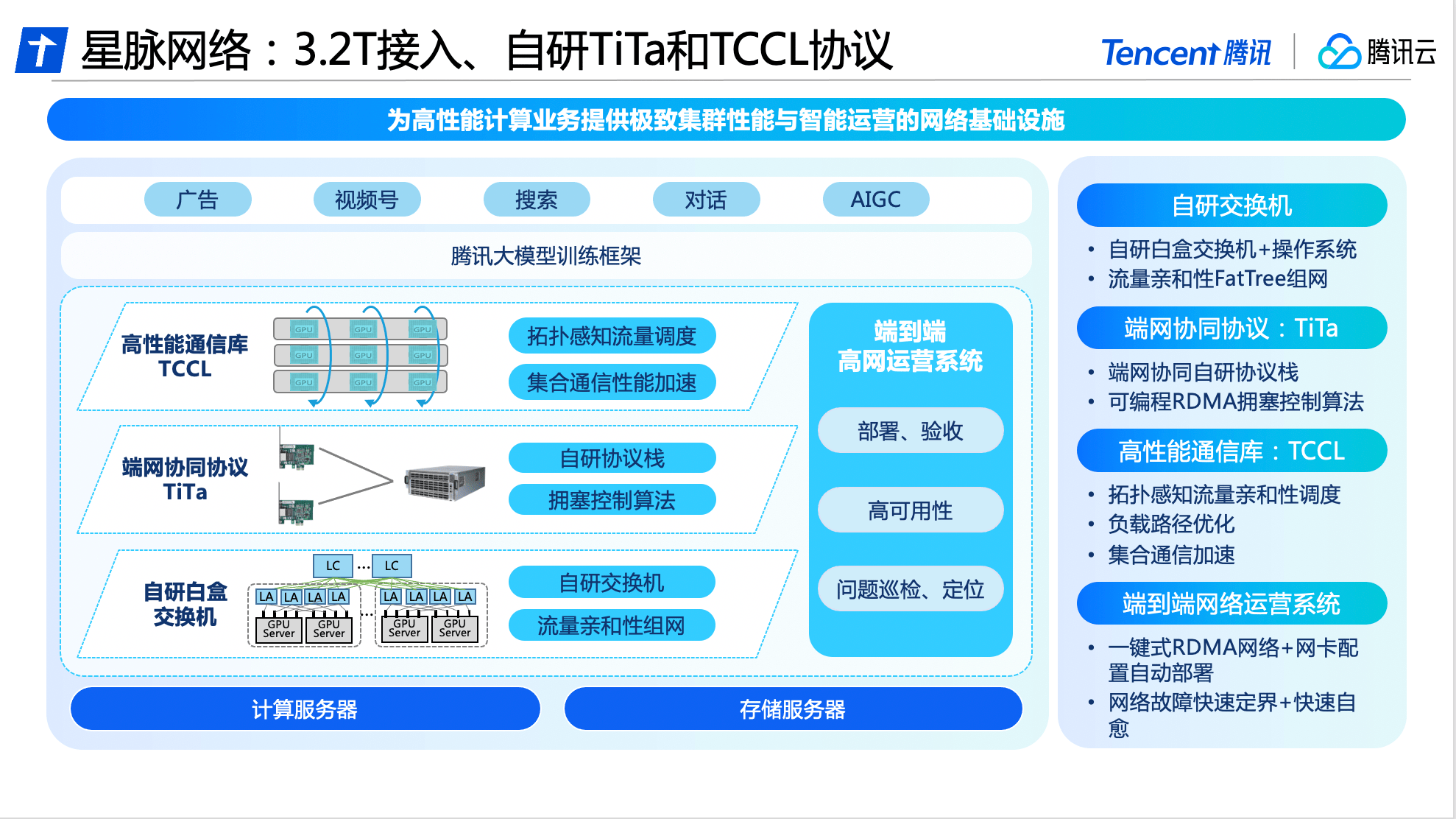
In terms of hardware, Xingmai Network is based on Tencent's network research and development platform and uses all self-developed equipment to build an interconnection base to achieve automated deployment and configuration.
In terms of software, Tencent Cloud’s self-developed TiTa network protocol adopts advanced congestion control and management technology, which can monitor and adjust network congestion in real time, meet the communication needs between a large number of server nodes, and ensure smooth data exchange and delay. Low, achieving zero packet loss under high load, making cluster communication efficiency more than 90%.
In addition, Tencent Cloud also designed a high-performance collective communication library TCCL for Xingmai Network and integrated it into customized solutions, enabling the system to realize microsecond-level network quality perception. By using a dynamic scheduling mechanism to reasonably allocate communication channels, training interruptions due to network problems can be effectively avoided, and communication delays can be reduced by 40%.
The availability of the network also determines the computing stability of the entire cluster. In order to ensure the high availability of Xingmai network, Tencent Cloud has developed an end-to-end full-stack network operation system. Through the end-network three-dimensional monitoring and intelligent positioning system, end-network problems are automatically delimited and analyzed, so that the overall fault troubleshooting time can be shortened. The day level is reduced to the minute level. After improvements, the overall deployment time of the large-scale model training system has been shortened to 4.5 days, ensuring 100% accuracy of the basic configuration.
After three generations of technological evolution, we have deeply cultivated and researched the integration of software and hardware
Behind the all-round upgrade of Xingmai Network is the result of three generations of technological evolution of Tencent’s data center network.
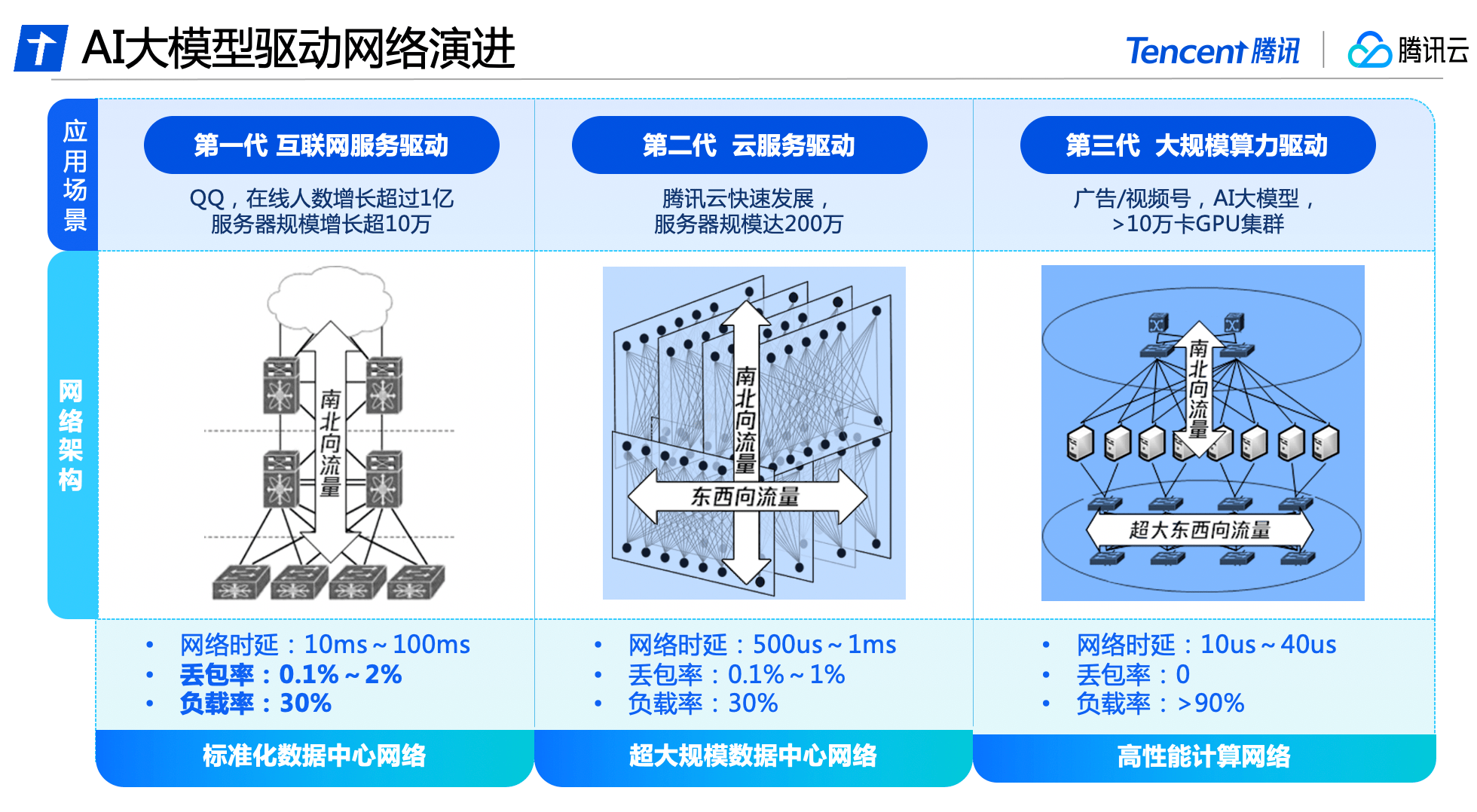
In the early days of Tencent's development, data center network traffic mainly consisted of north-south traffic for users to access data center servers. The network architecture was mainly based on access, aggregation, and egress. At this stage, commercial network equipment was mainly used to build a standardized data center network, supporting the growth of QQ online users by more than 100 million and the scale of servers by more than 100,000.
With the rise of big data and cloud computing, east-west traffic between servers has gradually increased, and cloud tenants have created virtualization and isolation requirements for the network. The data center network architecture has gradually evolved into a cloud network architecture that carries both north-south and east-west traffic. Tencent Cloud has built a fully self-developed network equipment and management system to create an ultra-large-scale data center network with nearly 2 million servers.
Tencent Cloud was the first to launch a high-performance computing network in China to meet the needs of large AI models, and adopted a separation architecture for east-west and north-south traffic. It has built an independent network architecture with ultra-large bandwidth that meets the characteristics of AI training traffic, and cooperates with self-developed software and hardware facilities to achieve independent controllability of the entire system and meet the new needs of super computing power for network performance.
Recently, Tencent Cloud released a new generation of HCC high-performance computing cluster, which is based on the Xingmai high-performance network. It can achieve 3.2T ultra-high interconnection bandwidth, and the computing performance is 3 times higher than the previous generation. It is a large AI model. Training to build a reliable and high-performance network base.
In the future, Tencent Cloud will continue to invest in the research and development of basic technologies to provide strong technical support for the digital and intelligent transformation of all walks of life.
The above is the detailed content of For large AI models, Tencent Cloud fully disclosed its self-developed Xingmai high-performance computing network for the first time. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



