


The previous article introduced you to some basic knowledge of LangChain. Friends who have not seen it can click here to take a look. Today, we will introduce LangChain’s first very important component model, Model.
Note that the model mentioned here refers to the model component of LangChain, not the language model similar to OpenAI. The reason why LangChain has model components is because there are too many language models in the industry, except for the company OpenAI In addition to language models, there are many others.
LangChain has three types of model components, namely LLM large language model, Chat Model chat model and text embedding model Text Embedding Models.
As the most basic model component, LLM only supports string input and output, which can meet our needs in most scenarios. We can write Python code directly on Colab([https://colab.research.google.com)
The following is a case, first install the dependencies, and then execute the following code.
pip install openaipip install langchain
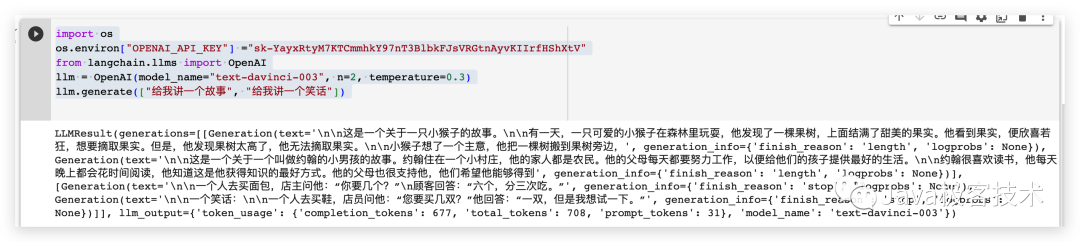
import os# 配置OpenAI 的 API KEYos.environ["OPENAI_API_KEY"] ="sk-xxx"# 从 LangChain 中导入 OpenAI 的模型from langchain.llms import OpenAI# 三个参数分别代表OpenAI 的模型名称,执行的次数和随机性,数值越大越发散llm = OpenAI(model_name="text-davinci-003", n=2, temperature=0.3)llm.generate(["给我讲一个故事", "给我讲一个笑话"])
The running results are as follows
Chat Model is based on the LLM model. It's just that the input and output between Chat Model components are more structured than the LLM model. The types of input and output parameters are Chat Model, not simple strings. Commonly used Chat Model types include the following
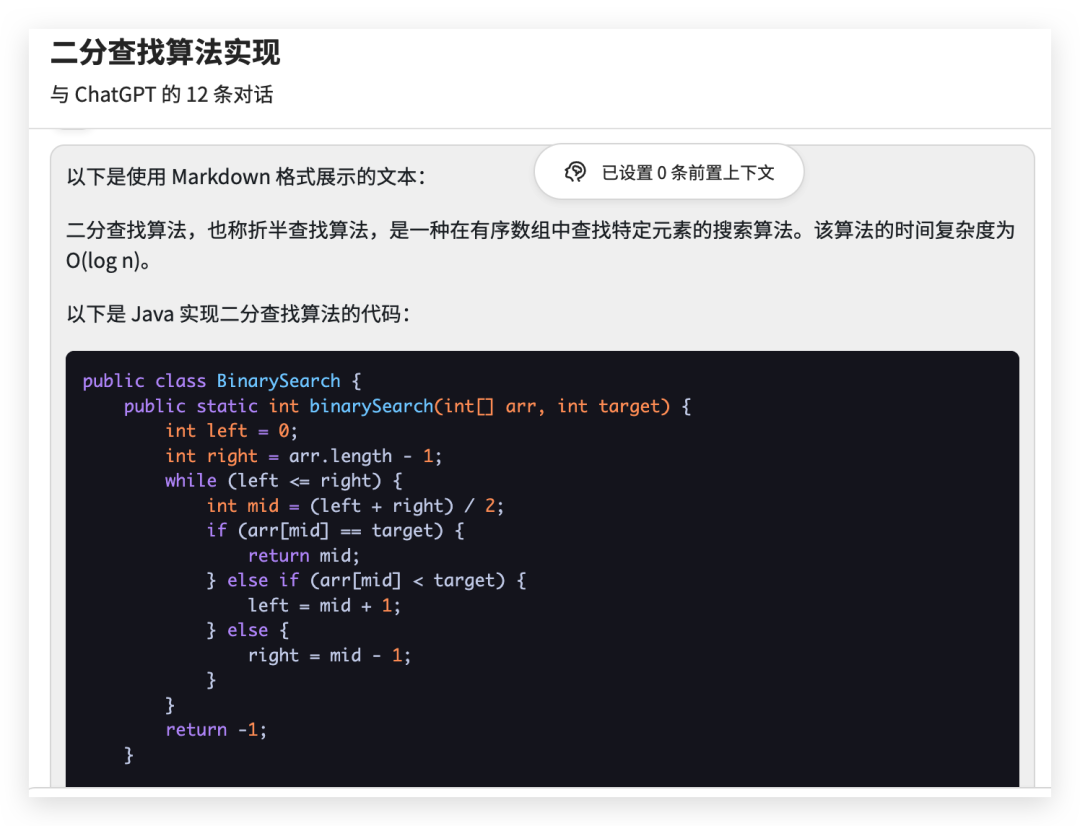
from langchain.chat_models import ChatOpenAIfrom langchain.schema import (AIMessage,HumanMessage,SystemMessage)chat = ChatOpenAI(temperature=0)messages = [SystemMessage(cnotallow="返回的数据markdown 语法进行展示,代码使用代码块包裹"),HumanMessage(cnotallow="用 Java 实现一个二分查找算法")]print(chat(messages))
The generated content string form is as follows
The half search algorithm is a search used to find specific elements in an ordered array Algorithm, also known as binary search algorithm. The time complexity of this algorithm is O(log n). \n\nThe following is the code to implement the binary search algorithm in Java:\n\njava\npublic class BinarySearch {\n public static int binarySearch(int[] arr, int target) {\n int left = 0;\n int right = arr.length - 1;\n while (left <= right) {\n int mid = (left right) / 2;\n if (arr[mid] == target) {\n return mid;\n } else if (arr[mid] < target) {\n left = mid 1;\n } else {\n right = mid - 1;\n }\n }\n return -1;\n }\n \n public static void main(String[] args) {\n int[] arr = {1, 3, 5, 7, 9};\n int target = 5;\n int index = binarySearch(arr, target) ;\n if (index != -1) {\n System.out.println("The subscript of the target element " target " in the array is " index);\n } else {\n System.out.println( "The target element " target " is not in the array");\n }\n }\n}\n\n\nIn the above code, the binarySearch method receives an ordered array and a target element, and returns the target element in the array subscript, if the target element is not in the array, -1 is returned. \n\nIn the binarySearch method, use two pointers left and right to point to the left and right ends of the array respectively, and then continuously narrow the search range in a while loop until the target element is found or the search range is empty. In each loop, the middle position mid is calculated, and then the target element is compared with the element in the middle position. If they are equal, the subscript of the middle position is returned; if the target element is larger than the element in the middle position, the left pointer is moved to To the right of the middle position; if the target element is smaller than the middle position element, move the right pointer to the left of the middle position. ' additional_kwargs={} example=False
Extract the content in content and display it using markdown syntax like this
Use this model component, You can preset some roles and then customize personalized questions and answers.
from langchain.chat_models import ChatOpenAIfrom langchain.prompts import (ChatPromptTemplate,PromptTemplate,SystemMessagePromptTemplate,AIMessagePromptTemplate,HumanMessagePromptTemplate,)from langchain.schema import (AIMessage,HumanMessage,SystemMessage)system_template="你是一个把{input_language}翻译成{output_language}的助手"system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)human_template="{text}"human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])messages = chat_prompt.format_prompt(input_language="英语", output_language="汉语", text="I love programming.")print(messages)chat = ChatOpenAI(temperature=0)print(chat(messages.to_messages()))output
messages=[SystemMessage(cnotallow='You are an assistant that translates English into Chinese', additional_kwargs= {}), HumanMessage(cnotallow='I love programming.', additional_kwargs={}, example=False)] cnotallow='I love programming.' example=False, additional_kwargs={}
文本嵌入模型组件相对比较难理解,这个组件接收的是一个字符串,返回的是一个浮点数的列表。在 NLP 领域中 Embedding 是一个很常用的技术,Embedding 是将高维特征压缩成低维特征的一种方法,常用于自然语言处理任务中,如文本分类、机器翻译、推荐系统等。它将文本中的离散数据如单词、短语、句子等,映射为实数向量,以更好地进行神经网络处理和学习。通过 Embedding,文本数据可以被更好地表示和理解,提高了模型的表现力和泛化能力。
from langchain.embeddings import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()text = "hello world"query_result = embeddings.embed_query(text)doc_result = embeddings.embed_documents([text])print(query_result)print(doc_result)
output
[-0.01491016335785389, 0.0013780705630779266, -0.018519161269068718, -0.031111136078834534, -0.02430146001279354, 0.007488010451197624,0.011340680532157421, 此处省略 .......
今天给大家介绍了一下 LangChain 的模型组件,有了模型组件我们就可以更加方便的跟各种 LLMs 进行交互了。
官方文档:https://python.langchain.com/en/latest/modules/models.html
The above is the detailed content of Java programmers learn LangChain from scratch—model components. For more information, please follow other related articles on the PHP Chinese website!
 How to turn off real-time protection in Windows Security Center
How to turn off real-time protection in Windows Security Center
 How to modify the text on the picture
How to modify the text on the picture
 What is the difference between wechat and WeChat?
What is the difference between wechat and WeChat?
 How to solve parse error
How to solve parse error
 How to download nvidia control panel
How to download nvidia control panel
 Advantages of plc control system
Advantages of plc control system
 Connected but unable to access the internet
Connected but unable to access the internet
 ajax tutorial
ajax tutorial








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



