


The index is a special file that contains reference pointers to all records in the data table. You can create an index on one or more columns in the table and specify the type of index. Each type of index has its own data structure implementation.
The relationship between tables, data, and indexes in the database is similar to the relationship between books, book content, and book catalogs on the bookshelf. The role of the index is similar to the book catalog. , can be used to quickly locate and retrieve data. Indexes can greatly improve database performance.
To consider creating an index on a certain column or columns of a database table, you need to consider the following points:
Data The volume is large, and conditional queries are often performed on these columns.
The frequency of insertion operations and modification operations on these columns in this database table is low.
Indexes will take up additional disk space.
Divided from the index storage structure: BTree index, Hash index, FULLTEXT full-text index, RTree index
Divided from the application level: ordinary index, unique index, primary key index, composite index
Divided from the index key value type, primary key index, auxiliary index (secondary index Index)
Divided from the logical relationship between data storage and index key values: clustered index (clustered index) non-clustered index (non-clustered index)
Divided from the number of index columns: single column index, compound index

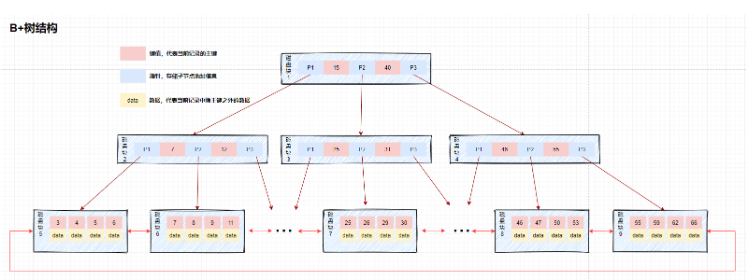
Difference:
The data is saved in different locations: B-tree is saved in leaf nodes, B-tree is saved in all nodes
Reflects the advantages of B-tree: Nodes do not store data, so one node can store more keys. It can make the tree shorter, so the number of IO operations is fewer. Query performance is stable: each query traverses from the root node to the leaf node, the query path length is the same, that is, each query is equally efficient, and the time complexity is fixed at O(log(n))
leaf node Pointing: The adjacent leaf nodes of the B-tree are connected through pointers. The B-tree does not
reflects the advantages of the B-tree: all leaf nodes form an ordered linked list, which facilitates range search
-- 在创建表的时候,直接在字段名后指定 primary key create table user1(id int primary key, name varchar(30)); -- 在创建表的最后,指定某列或某几列为主键索引 create table user2(id int, name varchar(30), primary key(id)); -- 创建表以后再添加主键 create table user3(id int, name varchar(30)); alter table user3 add primary key(id);
Characteristics of primary key index:
There can be at most one primary key index in a table, and of course it can be made to match the primary key
The primary key index is highly efficient (the primary key cannot be repeated)
The column used to create the primary key index cannot be null and cannot be repeated
The columns of the primary key index are basically int
-- 在表定义时,在某列后直接指定unique唯一属性。 create table user4(id int primary key, name varchar(30) unique); -- 创建表时,在表的后面指定某列或某几列为unique create table user5(id int primary key, name varchar(30), unique(name)); -- 创建表以后再添加unique create table user6(id int primary key, name varchar(30)); alter table user6 add unique(name);
Features of unique index:
A table can have multiple unique indexes
High query efficiency
If a unique index is created on a certain column , it must be ensured that this column cannot have duplicate data
If not null is specified on a unique index, it is equivalent to the primary key index
--在表的定义最后,指定某列为索引 create table user8(id int primary key, name varchar(20), email varchar(30), index(name) ); --创建完表以后指定某列为普通索引 create table user9(id int primary key, name varchar(20), email varchar(30)); alter table user9 add index(name); -- 创建一个索引名为 idx_name 的索引 create table user10(id int primary key, name varchar(20), email varchar(30)); create index idx_name on user10(name);
Features of ordinary indexes:
There can be multiple ordinary indexes in a table. Ordinary indexes are more commonly used in actual development
If a column needs to be indexed, but the column has duplicate values, then we should use a normal index
show keys from table name
##mysql> show keys from goods\G************ 1. row * **********
Table: goods <= Table name
Non_unique: 0 <= 0 represents a unique index
Key_name: PRIMARY <= Primary key index
Seq_in_index: 1
Column_name: goods_id <= Which column is the index in?
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE < = Index in the form of a binary tree
Comment:
1 row in set (0.00 sec)
mysql> alter table user10 drop index idx_name;
mysql> drop index name on user8
The above is the detailed content of What is the indexing principle and optimization strategy of MySQL database?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



