


If you use a tree as the index data structure, each time you search for data, one node of the tree will be read from the disk, which is a page. However, each node of the binary tree only stores one piece of data and cannot fill a page. storage space, wouldn’t the extra storage space be wasted? In order to solve this shortcoming of the binary balanced search tree, we should look for a data structure that can store more data in a single node, that is, a multi-way search tree.
1. Complete binary tree height:O(log2N), where 2 is the logarithm, the number of nodes at each level of the tree;
2. The height of the complete M-way search tree:O(logmN), where M is the logarithm, the number of nodes at each level of the tree;
M-way search tree is suitable for Scenarios where the amount of stored data is too large to be loaded into memory at once. Store more data in one layer by increasing the number of nodes per layer and storing more data in each node, thereby reducing the height of the tree and reducing the number of disk accesses during data lookup.
Therefore, if the number of keywords each node contains and the number of nodes per level increase, the height of the tree will decrease. Although the data determination of each node will be more time-consuming, the focus of B-tree is to solve the disk performance bottleneck, so the cost of searching data on a single node can be ignored.
B tree is an M-way search tree. B-tree is mainly used to solve the problem of unbalanced M-way search tree and the height change of the tree. High, which is the same as the performance problem caused by the degeneration of binary trees into linked lists. B-tree ensures the balance of the M-way search tree by controlling and adjusting the nodes of each layer, such as node separation, node merging, splitting parent nodes upward when one layer is full to add new layers, and other operations.
In the B-tree, each node is a disk block (page), and the order or path number M specifies the maximum number of child nodes in the node. Each non-leaf node stores keywords and pointers to subtrees. The specific number is: M-order B-tree, each non-leaf node stores M-1 keywords and M pointers to subtrees. The picture shows a schematic diagram of a 5-order B-tree structure:

First create a user table:
create table user( id int, name varchar, primary key(id) ) ROW_FORMAT=COMPACT;
If we use a B-tree to index user records in the table:
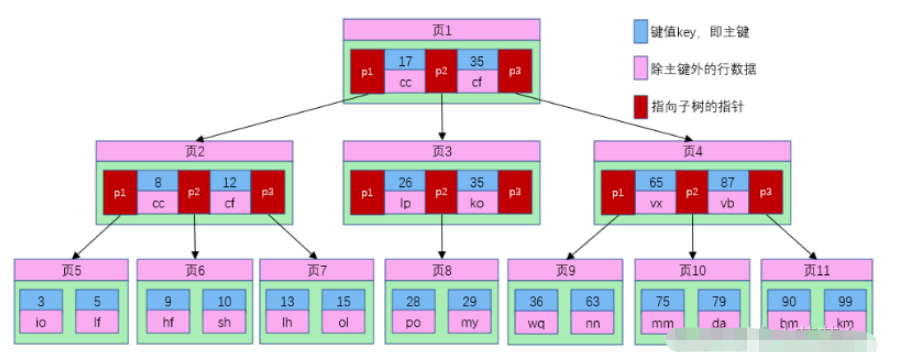
Each node of the B-tree occupies one Disk blocks are also pages. As can be seen from the above figure, compared with the balanced binary tree, each node of the B-tree stores more primary keys and data, and each node has more child nodes. The number of nodes is generally called the order. The B-tree in the above figure is a third-order B-tree, and the height will also be reduced. If we want to find the user information ofid=28, then the search process is as follows:
1. Find page 1 according to the root node and read it into the memory. [Disk I/O operation 1st time]
2. Compare the key value 28 in the interval (17,35) and find the pointer p2 of page 1;
3. Find the page based on the p2 pointer 3. Read into memory. [Disk I/O operation 2nd time]
4. Compare the key value 28 in the interval (26,35) and find the pointer p2 of page 3.
5. Find page 8 according to the p2 pointer and read it into the memory. [Disk I/O operation 3rd time]
6. Find the key value 28 in the key value list on page 8. The user information corresponding to the key value is (28,po);
B-TreeCompared withAVLTree, the number of nodes is reduced, so that the data fetched from the memory every time the disk I/O is used, thereby improving the query efficiency.
B Tree is an optimization based on B-Tree, making it more suitable for implementing external storage index structure. The properties of B-tree:
1. The subtree pointers of non-leaf nodes are the same as the number of keywords;
2. Add a link pointer to all leaf nodes;
3. All keywords are in leaf nodes appears, and the keywords in the linked list happen to be in order;
4. Non-leaf nodes are equivalent to the indexes of leaf nodes, and leaf nodes are equivalent to the data layer that stores (keyword) data;
InnoDB storage engine uses B Tree to implement its index structure.
B-In the tree structure diagram, it can be seen that each node also contains data values in addition to the key value of the data. The storage space of each page is limited. If the data data is large, the number of keys that can be stored in each node (i.e. one page) will be very small. When the amount of stored data is large, it will also lead to B- The depth of Tree is larger, which increases the number of disk I/Os during query, thereby affecting query efficiency. In B Tree, all data record nodes are stored on leaf nodes of the same layer in order of key value. Only key value information is stored on non-leaf nodes. This can greatly increase the number of key values stored in each node. Reduce the height of B Tree.
B Tree has several differences compared to B-Tree:
1. Non-leaf nodes only store key value information and pointers to child node page numbers;
2. There is a link pointer between all leaf nodes;
3. Data records are stored in leaf nodes;

Based on the above figure, let’s take a look at the difference between B-tree and B-tree:
(2) In B-tree, non-leaf Nodes only store key values, while B-tree nodes store both key values and data.
The page size is fixed, and the default page size in InnoDB is 16KB. If data is not stored, more key values will be stored, the order of the corresponding tree will be larger, and the tree will be shorter and fatter. As a result, the number of disk IO times we need to search for data will be reduced again. Data query efficiency will also be faster.
In addition, if one node of our B-tree can store 1000 key values, then the 3-layer B-tree can store 1000×1000×1000=1 billion pieces of data. Generally, the root node is resident in memory (there is no need to read the disk when retrieving the root node for the first time), so generally we only need 2 disk IOs to search for 1 billion data.
(2) All data in the B-tree index are stored in leaf nodes, and the data is arranged in order.
B The pages in the tree are connected through a two-way linked list, and the data in the leaf nodes are connected through a one-way linked list. In this way, all the data in the table can be found. B-trees make range queries, sort queries, group queries, and deduplication queries extremely simple. In B-tree, because the data is scattered in various nodes, it is not easy to achieve this.
The above is the detailed content of What is the difference between B-tree index and B+-tree index in MySQL?. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



