


You enter text and let AI generate a video. This idea only appeared in people's imagination before. Now, with the development of technology, this function has been realized.
In recent years, generative artificial intelligence has attracted huge attention in the field of computer vision. With the advent of diffusion models, generating high-quality images from text prompts, i.e., text-to-image synthesis, has become very popular and successful.
Recent research has attempted to successfully extend the text-to-image diffusion model to the task of text-to-video generation and editing by reusing it in the video domain. Although such methods have achieved promising results, most of them require extensive training using large amounts of labeled data, which may be too expensive for many users.
In order to make video generation cheaper, Tune-A-Video proposed by Jay Zhangjie Wu et al. last year introduced a mechanism to apply the Stable Diffusion (SD) model to the video field . Only one video needs to be adjusted, greatly reducing training workload. Although this is much more efficient than previous methods, it still requires optimization. Furthermore, Tune-A-Video's generation capabilities are limited to text-guided video editing applications, and compositing videos from scratch remains beyond its capabilities.
In this article, researchers from Picsart AI Resarch (PAIR), the University of Texas at Austin and other institutions have used zero-shot and no training to achieve a new method of text-to-video synthesis. A step forward in the problem direction of generating videos based on text prompts without any optimization or fine-tuning.

Let’s see how it works. For example, a panda is surfing; a bear is dancing in Times Square:

This research can also generate actions based on the target :

In addition, edge detection can also be performed:

A key concept of the approach proposed in this paper is to modify a pre-trained text-to-image model (such as Stable Diffusion) to enrich it with time-consistent generation. By building on already trained text-to-image models, our approach leverages their excellent image generation quality, enhancing their applicability to the video domain without requiring additional training.
In order to enhance temporal consistency, this paper proposes two innovative modifications: (1) first enrich the latent encoding of the generated frame with motion information to keep the global scene and background temporally consistent; (2) ) then uses a cross-frame attention mechanism to preserve the context, appearance, and identity of foreground objects throughout the sequence. Experiments show that these simple modifications can produce high-quality and temporally consistent videos (shown in Figure 1).

Although other people’s work trained on large-scale video data, our method achieves similar and sometimes better performance (shown in Figures 8 and 9).

#The method in this article is not limited to text-to-video synthesis, but is also suitable for conditional (see Figures 6 and 5) and specialized video generation (see Figure 7), as well as instruction-guided video editing, which can be called It is Video Instruct-Pix2Pix driven by Instruct-Pix2Pix (see Figure 9).


#In this paper, this paper uses the text-to-image synthesis capability of Stable Diffusion (SD) to handle the text-to-video task in zero-shot situations. For the needs of video generation rather than image generation, SD should focus on the operation of underlying code sequences. The naive approach is to independently sample m potential codes from a standard Gaussian distribution, i.e.
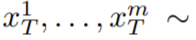 N (0, I) , and apply DDIM Sample to get the corresponding tensor
N (0, I) , and apply DDIM Sample to get the corresponding tensor
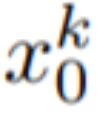
, where k = 1,…,m, then decode to Get the generated video sequence
. However, as shown in the first row of Figure 10, this results in completely random image generation, sharing only the semantics described by without consistency in object appearance or motion. 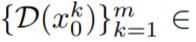
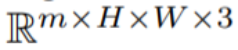

# Introduce motion dynamics between ## to maintain the temporal consistency of the global scene; (ii) Use a cross-frame attention mechanism to preserve the appearance and identity of foreground objects. Each component of the method used in this paper is described in detail below, and an overview of the method can be found in Figure 2 . 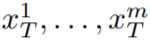
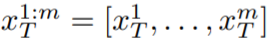
## All applications of Text2Video-Zero show that it successfully generates videos with temporal consistency of global scene and background, foreground The context, appearance, and identity of the object are maintained throughout the sequence.
In the case of text-to-video, it can be observed that it produces high-quality videos that are well aligned with the text prompts (see Figure 3). For example, a panda is drawn to walk naturally on the street. Likewise, using additional edge or pose guidance (see Figure 5, Figure 6, and Figure 7), high-quality videos matching prompts and guidance were generated, showing good temporal consistency and identity preservation.

In the case of Video Instruct-Pix2Pix (see Figure 1), the generated video High fidelity relative to the input video while strictly following instructions.
Comparison with Baseline
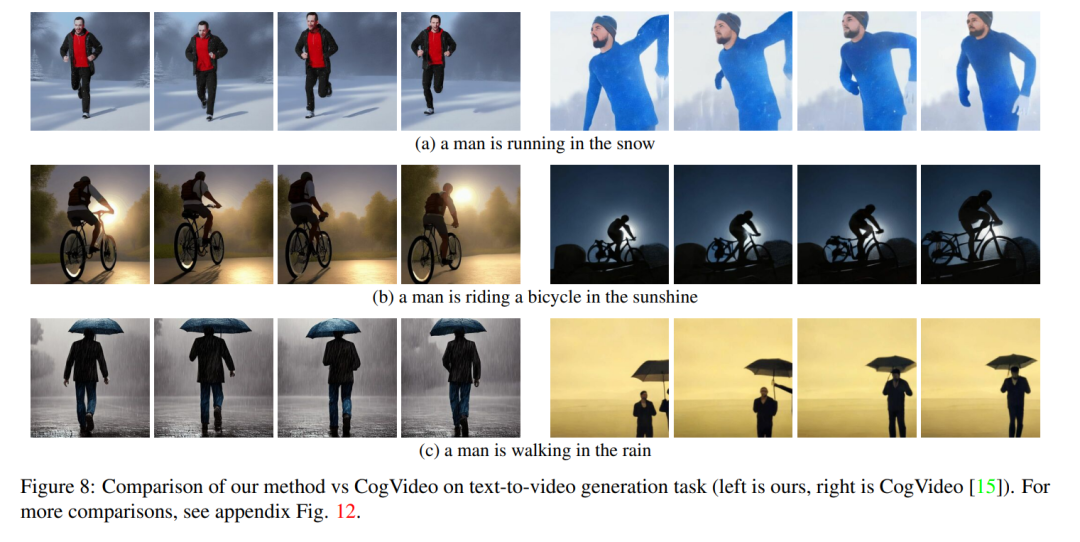
This paper compares its method with two publicly available baselines: CogVideo and Tune -A-Video. Since CogVideo is a text-to-video method, this article compares it with it in a plain text-guided video synthesis scenario; using Video Instruct-Pix2Pix for comparison with Tune-A-Video.
For quantitative comparison, this article uses the CLIP score to evaluate the model. The CLIP score represents the degree of video text alignment. By randomly obtaining 25 videos generated by CogVideo, and synthesizing the corresponding videos using the same tips according to the method in this article. The CLIP scores of our method and CogVideo are 31.19 and 29.63 respectively. Therefore, our method is slightly better than CogVideo, although the latter has 9.4 billion parameters and requires large-scale training on videos.
Figure 8 shows several results of the method proposed in this paper and provides a qualitative comparison with CogVideo. Both methods show good temporal consistency throughout the sequence, preserving the identity of the object as well as its context. Our method shows better text-video alignment capabilities. For example, our method correctly generates a video of a person riding a bicycle in the sun in Figure 8 (b), while CogVideo sets the background to moonlight. Also in Figure 8 (a), our method correctly shows a person running in the snow, while the snow and the running person are not clearly visible in the video generated by CogVideo.
Video Qualitative results for Instruct-Pix2Pix and visual comparison with per-frame Instruct-Pix2Pix and Tune-AVideo are shown in Figure 9. While Instruct-Pix2Pix shows good editing performance per frame, it lacks temporal consistency. This is especially noticeable in videos depicting skiers, where the snow and sky are drawn using different styles and colors. These issues were solved using the Video Instruct-Pix2Pix method, resulting in temporally consistent video editing throughout the sequence.
Although Tune-A-Video creates time-consistent video generation, compared with this article's method, it is less consistent with instruction guidance, difficult to create local edits, and Details of the input sequence are lost. This becomes apparent when looking at the edit of the dancer's video depicted in Figure 9 , left. Compared to Tune-A-Video, our method paints the entire outfit brighter while better preserving the background, such as the wall behind the dancer remaining almost unchanged. Tune-A-Video paints a heavily deformed wall. In addition, our method is more faithful to the input details. For example, compared to Tune-A-Video, Video Instruction-Pix2Pix draws dancers using the provided poses (Figure 9 left) and displays all skiers appearing in the input video. (As shown in the last frame on the right side of Figure 9). All the above mentioned weaknesses of Tune-A-Video can also be observed in Figures 23, 24.


The above is the detailed content of Generating videos is so easy, just give a hint, and you can also try it online. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



