


In the current rapidly developing Internet era, various types of data are constantly emerging. Among them, table data is the most commonly used. Tables are a kind of general structured data. We can design SQL queries according to needs. Statements to obtain the knowledge in the table, but often require higher design costs and learning costs. At this time, the Text-to-SQL parsing task is particularly important. According to different dialogue scenarios, it is also divided into single-round Text-to-SQL parsing and multi-round Text-to-SQL parsing. This article mainly studies the more difficult and closer Multiple rounds of Text-to-SQL parsing tasks for real-world applications.
Recently, Alibaba DAMO Academy and the Shenzhen Institute of Advanced Technology of the Chinese Academy of Sciences proposed a SQL query statement-oriented pre-training model STAR for multiple rounds of Text-to-SQL semantic parsing. As of now, STAR has occupied the first place on the SParC and CoSQL lists for 10 consecutive months. The research paper has been accepted by EMNLP 2022 Findings, an international conference in the field of natural language processing.

STAR is a novel and effective multi-turn dialogue table knowledge pre-training language model. This model mainly uses two pre-training objectives to track complex contextual semantics and database patterns in multi-turn dialogues. State tracing is modeled with the goal of enhancing the encoding representation of natural language queries and database schemas in conversation flows.
The research was evaluated on SParC and CoSQL, the authoritative lists of conversational semantic parsing. Under fair downstream model comparison, STAR compared with the previous best multi-round table preprocessing For the training model SCoRe, QM/IM improved by 4.6%/3.3% on the SParC data set, and QM/IM significantly improved by 7.4%/8.5% on the CoSQL data set. In particular, CoSQL has more contextual changes than the SParC dataset, which verifies the effectiveness of the pre-training task proposed in this study.
In order to enable users to interact with the database through natural language dialogue even if they are not familiar with SQL syntax, multiple rounds of Text-to-SQL parsing The task came into being, which acts as a bridge between the user and the database, converting natural language questions within the interaction into executable SQL query statements.
Pre-trained models have shined on various NLP tasks in recent years. However, due to the inherent differences between tables and natural languages, ordinary pre-trained language models (such as BERT, RoBERTa) cannot achieve optimal performance on this task, so the pre-trained tabular model (TaLM) [1-5] came into being. Generally, pretrained tabular models (TaLM) need to deal with two core issues, including how to model complex dependencies (references, intent offsets) between contextual queries and how to effectively utilize historically generated SQL results. In response to the above two core problems, the existing pre-trained table model has the following defects:
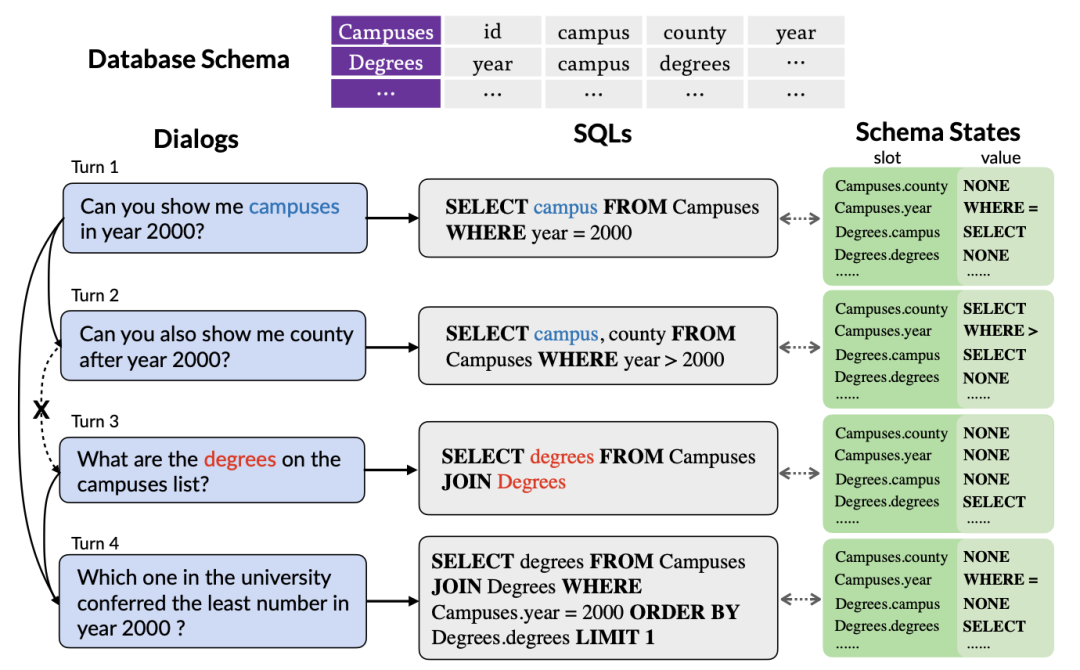
Figure 1. A context Dependent multi-round Text-to-SQL parsing example.
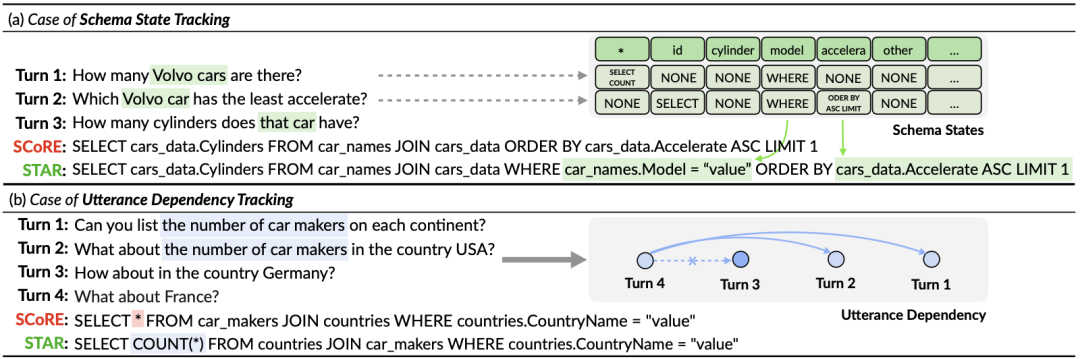
First, existing table pre-training models only explore the contextual information of natural language queries, without considering the interactions contained in historical SQL query statements. State information, which often summarizes the user's intent in a more accurate and compact form. Therefore, modeling and tracking historical SQL information can better capture the intent of the current round of queries, thereby generating corresponding SQL query statements more accurately. As shown in Figure 1, since the table name "Compuses" is mentioned in the first round of SQL query, the table is likely to be selected again in the second round of SQL query, so it is particularly important to track the status of the table name "Compuses" important.
Second, because the user may ignore entities mentioned in the conversation history or introduce some references, resulting in a lack of dialogue information in the current round, multi-round Text-to-SQL parsing tasks need to effectively model contextual information In order to better parse the current round of natural language dialogue. As shown in Figure 1, the second round of dialogue omitted the “campuses in year 2000” mentioned in the first round of dialogue. However, most existing pre-trained table models do not consider contextual information, but model each round of natural language dialogue separately. Although SCoRe [1] models context switch information by predicting context switch labels between two adjacent rounds of dialogue, it ignores more complex context information and cannot track dependency information between long-distance dialogues. For example, in Figure 1, due to context switching between the second and third rounds of dialogue, SCoRe cannot capture the long-distance dependency information between the first and fourth rounds of dialogue.
Inspired by the conversation state tracking task in multi-turn dialogues, this research proposes a method to track the schema state of context SQL based on the schema state tracking pre-training target; for multi-turn dialogue The problem of complex semantic dependencies between questions in dialogues. This research proposes a dialogue dependency tracking method to capture the complex semantic dependencies between multiple rounds of dialogues, and proposes a weight-based contrastive learning method to better model positive examples between dialogues. and negative relationship.
This study first gives the symbols and problem definitions involved in multiple rounds of Text-to-SQL parsing tasks. 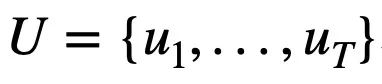 represents T rounds of natural language queries, and multiple rounds of Text-to-SQL dialogue interactions of the query, where
represents T rounds of natural language queries, and multiple rounds of Text-to-SQL dialogue interactions of the query, where 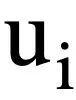 represents the i-th round of natural language questions, and each round of natural language Conversation
represents the i-th round of natural language questions, and each round of natural language Conversation 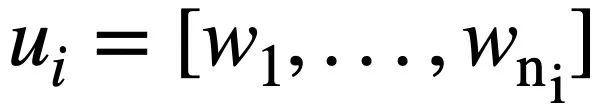 contains
contains 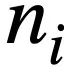 tokens. In addition, there is an interactive database s, which contains N tables
tokens. In addition, there is an interactive database s, which contains N tables 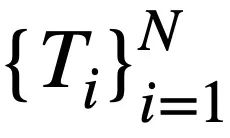 , and all tables contain m table names and column names,
, and all tables contain m table names and column names, 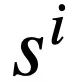 represents the database schema The ith table name or column name in s. Assuming that the current round is the t-th round, the purpose of the Text-to-SQL parsing task is to based on the current round of natural language query
represents the database schema The ith table name or column name in s. Assuming that the current round is the t-th round, the purpose of the Text-to-SQL parsing task is to based on the current round of natural language query 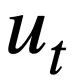 , historical query
, historical query  , database schema s and The SQL query statement
, database schema s and The SQL query statement 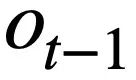 predicted in the previous round generates the SQL query statement
predicted in the previous round generates the SQL query statement 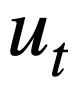 corresponding to the natural language query
corresponding to the natural language query 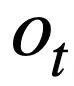 in the current round.
in the current round.
As shown in Figure 2, this study proposes a multi-round table pre-training framework based on SQL guidance, which makes full use of the structured information of historical SQL to enrich the dialogue representation. Thus, complex contextual information can be modeled more effectively.
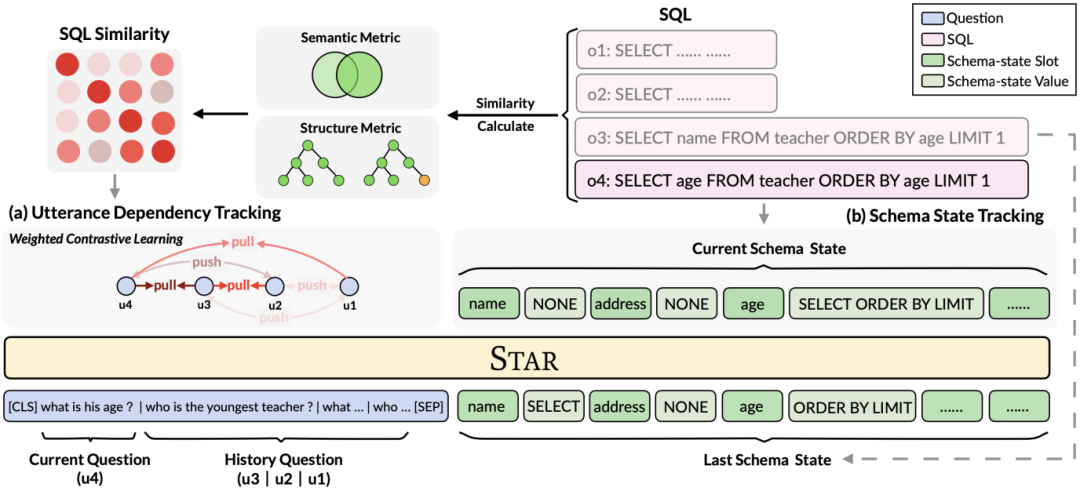
Figure 2. Model framework of STAR.
# Specifically, this research proposes table pre-training goals based on schema status tracking and dialogue dependency tracking, respectively, for SQL query statements in multiple rounds of interactions. and tracking the intent of natural language questions. (1) In a multi-turn dialogue situation, the SQL query of the current dialogue depends on the contextual SQL information. Therefore, inspired by the task of dialogue state tracking in multi-turn dialogues, this research proposes a Schema State Tracking (Schema State Tracking, SST)'s table pre-training objective tracks the schema state of context-sensitive SQL query statements (or user requests) in a self-supervised manner. (2) For the problem of complex semantic dependencies between natural language questions in multi-turn dialogues, a table pre-training goal based on Utterance Dependency Tracking (UDT) is proposed, and a weight-based contrastive learning method is used to learn better Feature representation for natural language queries. The following describes the two table pre-training goals in detail.
Table pre-training target based on pattern state tracking
This research proposes a table pre-training objective based on schema state tracking, which tracks the schema state (or user request) of context-sensitive SQL query statements in a self-supervised manner, with the purpose of predicting the value of the schema slot. Specifically, the study tracks the interaction state of a Text-to-SQL session in the form of schema state, where the slot is the database schema (i.e., the column names of all tables) and the corresponding slot value is the SQL keyword. Taking the SQL query in Figure 3 as an example, the value of the mode slot "[car_data]" is the SQL keyword "[SELECT]". First, the study converts the predicted SQL query statement 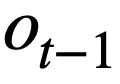 in round t - 1 into the form of a set of pattern states. Since the schema status slots are the column names of all tables in the database, values that do not appear in the schema status corresponding to the SQL query statement
in round t - 1 into the form of a set of pattern states. Since the schema status slots are the column names of all tables in the database, values that do not appear in the schema status corresponding to the SQL query statement 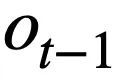 are set to [NONE]. As shown in Figure 3, this study uses m mode states
are set to [NONE]. As shown in Figure 3, this study uses m mode states 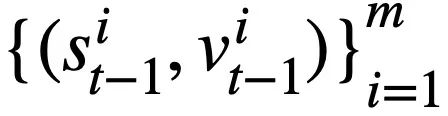 to represent the SQL query statement
to represent the SQL query statement 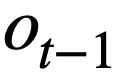 , where
, where 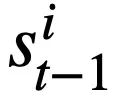 represents the i-th The slot of the mode status,
represents the i-th The slot of the mode status, 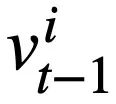 represents the value of the mode status. For the tth round, the goal of pattern state tracking is to find all historical natural language questions
represents the value of the mode status. For the tth round, the goal of pattern state tracking is to find all historical natural language questions 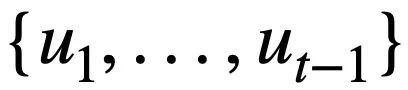 , the current question
, the current question 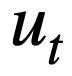 , and the previous round of SQL query statements In the case of
, and the previous round of SQL query statements In the case of 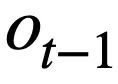 's mode status
's mode status 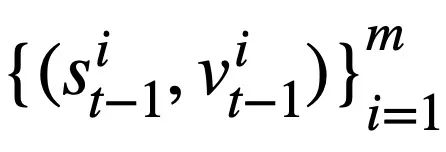 , predict the value of each mode status slot
, predict the value of each mode status slot 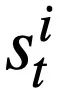 of the t-th round of SQL query statements.
of the t-th round of SQL query statements. 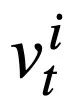 . That is to say, at round t, the input
. That is to say, at round t, the input 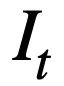 of the pattern state tracking pre-training target is:
of the pattern state tracking pre-training target is:
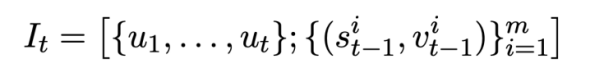
Since each pattern state 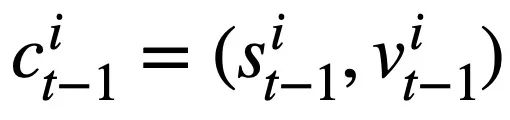 contains multiple words, an attention layer is applied to obtain the representation of
contains multiple words, an attention layer is applied to obtain the representation of 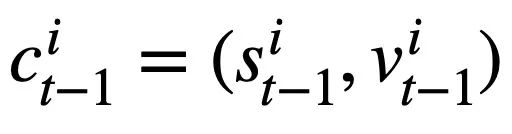 . Specifically, given the output contextualized representation
. Specifically, given the output contextualized representation  ( l is the starting index of
( l is the starting index of 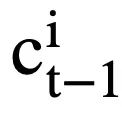 ). For each mode state
). For each mode state 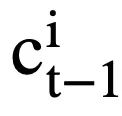 , the attention-aware representation
, the attention-aware representation 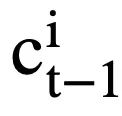 of the mode state
of the mode state 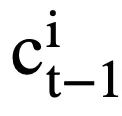 can be calculated as:
can be calculated as:
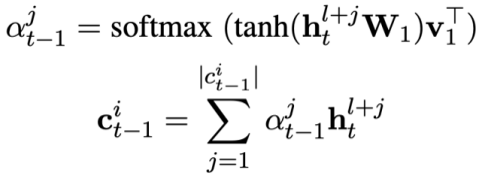
Then predict the mode status of the current problem:
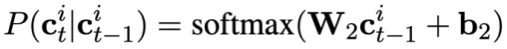
Finally, change the mode status The tracking pre-training loss function can be defined as:
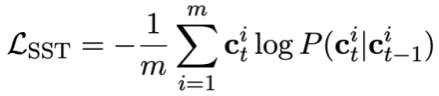
#Table pre-training objective based on dialogue dependency tracking
This study proposes a pre-training objective for utterance dependency tracking, utilizing a weight-based contrastive learning method to capture the complex semantic dependencies between natural language questions in each Text-to-SQL utterance. relation. A key challenge in weight-based contrastive learning is how to construct appropriate positive and negative example labels in a self-supervised manner. Intuitively, negative example pairs can be constructed by selecting natural language questions from different sessions. However, constructing positive question pairs is not trivial because the current questions may not be related to those historical questions where the topic shift occurred, such as the second and third utterances shown in Figure 1 . Therefore, this study treats natural language questions in the same conversation as pairs of positive examples and assigns them different similarity scores. SQL is a highly structured user utterance indication. Therefore, by measuring the similarity between current SQL and historical SQL, we can obtain semantically dependent pseudo-labels of natural language questions to obtain similarity scores for different statement constructions, thereby guiding context construction. mold. This study proposes a method to measure SQL similarity from both semantic and structural perspectives. As shown in Figure 3:

Figure 3. Two methods of calculating SQL statement similarity.
Semantic-based SQL similarity calculation This research measures the similarity between two SQL query statements by calculating the schema state similarity corresponding to them. semantic similarity between them. Specifically, as shown in Figure 3, this method will obtain the mode status 
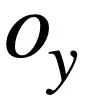 and # of the two SQL query statements
and # of the two SQL query statements 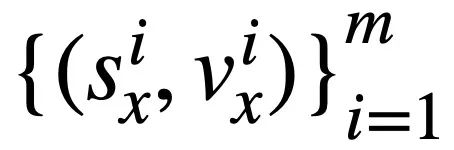 and respectively.
and respectively. 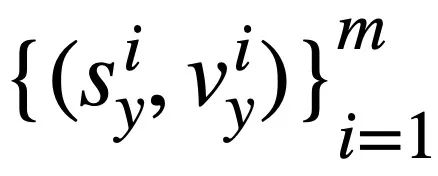 ##. Then, the study uses Jaccard similarity to calculate the semantic similarity between them
##. Then, the study uses Jaccard similarity to calculate the semantic similarity between them 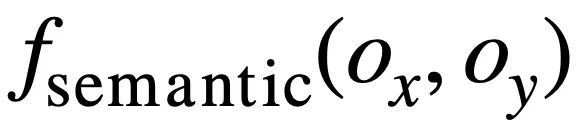 :
:
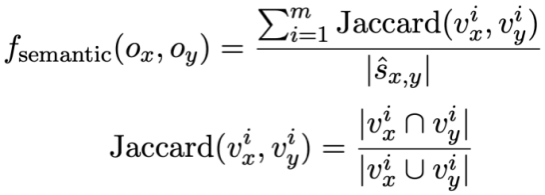
where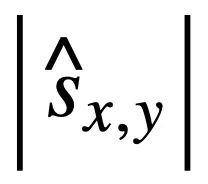 represents the number of non-repeating mode states where the value of the corresponding mode state of
represents the number of non-repeating mode states where the value of the corresponding mode state of  and
and  is not [NONE].
is not [NONE].
Structure-based SQL similarity calculation In order to utilize SQL query Tree structure of statements, this study first parses each SQL query 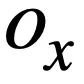 into a SQL tree
into a SQL tree 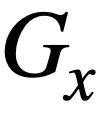 , as shown in Figure 3. Two SQL trees
, as shown in Figure 3. Two SQL trees 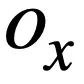 and
and 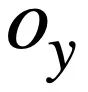 given the SQL query
given the SQL query
and 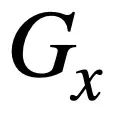
 , this study uses the Weisfeiler-Lehman algorithm to calculate the structural similarity score
, this study uses the Weisfeiler-Lehman algorithm to calculate the structural similarity score 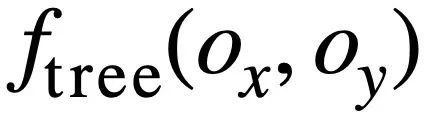 , the formula is as follows:
, the formula is as follows:
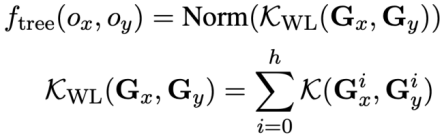
In summary, this study defines the similarity of two SQL query statements 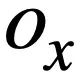 and
and 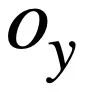 The scores are as follows:
The scores are as follows:
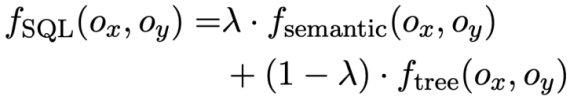
Weight-based contrast loss After getting SQL After similarity, this study uses weighted contrastive learning to bring the representation of semantically similar natural language questions closer in the conversation and to push the representation of semantically dissimilar natural language questions further away. Specifically, first, the study utilizes an attention mechanism to learn the input representation 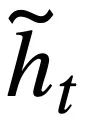 :
:
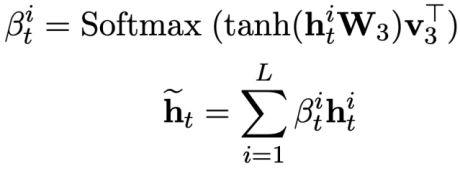
. Then, the study Minimize the weighted contrastive loss function to optimize the overall network:
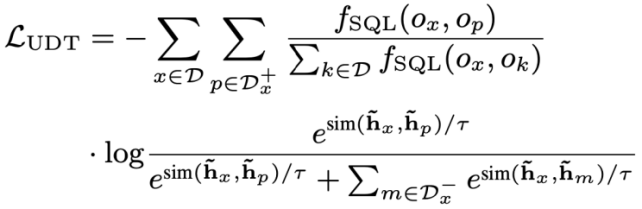
Finally, to learn context-based natural language query and database schema representation, This study also adopts a pre-training objective based on mask semantic modeling, and the loss function is expressed as. Based on the above three training objectives, this study defines a joint loss function based on homoscedasticity:
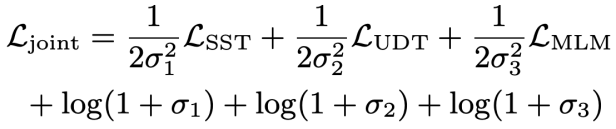
##where, 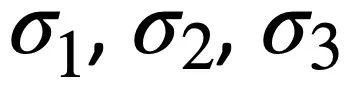 is a trainable parameter.
is a trainable parameter.
Dataset This research is authoritative in two conversational semantic parsing The effectiveness of the STAR model was verified using the data sets SParC and CoSQL. Among them, SParC is a cross-domain multi-round Text-to-SQL parsing data set, containing approximately 4,300 multi-round interactions and more than 12,000 natural language question-SQL query statement pairs; CoSQL is a cross-domain conversational Text-to-SQL parsing data set. to-SQL parsing data set, containing approximately 3,000 conversational interactions and more than 10,000 natural language question-SQL query statement pairs. Compared with SParC, CoSQL's conversation context is more semantically relevant, and the syntax of SQL query statements is more complex.
Benchmark Model In terms of baseline model, this study compared the following methods: (1) GAZP [6], by combining a The forward semantic parsing model and a backward dialogue generation model synthesize the training data of natural language dialogue-SQL query statement pairs, and finally select the data with cycle consistency to fit the forward semantic parsing model. (2) EditSQL [7] takes into account the interaction history information and improves the SQL generation quality of the current round of dialogue by predicting SQL query statements at the time before editing. (3) IGSQL [8] proposes a database schema interactive graph encoding model, which uses the historical information of the database schema to capture natural language input historical information, and introduces a gating mechanism in the decoding stage. (4) IST-SQL [9], inspired by the conversation state tracking task, defines two interactive states, schema state and SQL state, and updates the state according to the last predicted SQL query statement in each round. (5) R2SQL [10] proposes a dynamic graph framework to model the complex interactions between dialogues and database schemas in dialogue flows, and enriches the contextual representation of dialogues and database schemas through a dynamic memory decay mechanism. (6) PICARD [11] proposes an incremental semantic parsing to constrain the autoregressive decoding model of the language model. In each decoding step, it searches for legal output sequences by constraining the acceptability of the decoding results. . (7) DELTA [12], first uses a dialogue rewriting model to solve the integrity problem of dialogue context, and then inputs the complete dialogue into a single-round Text-to-SQL semantic parsing model to obtain the final SQL query statement. (8) HIE-SQL [13], from a multi-modal perspective, considers natural language and SQL as two modalities, explores the context dependency information between all historical conversations and the previous predicted SQL query statement, and proposes A bimodal pre-trained model and designed a modal link graph between conversations and SQL query statements.
Overall experimental results As shown in Figure 4, it can be seen from the experimental results that the STAR model has the best performance in SParC The effect on the two data sets of CoSQL and CoSQL is far better than other comparison methods. In terms of pre-training model comparison, the STAR model is far superior to other pre-training models (such as BERT, RoBERTa, GRAPPA, SCoRe). On the CoSQL dev data set, compared with the SCoRE model, the QM score increased by 7.4% and the IM score increased by 7.5%. . In terms of downstream Text-to-SQL model comparison, the LGESQL model using STAR as the base of the pre-trained model is far better than the downstream methods that use other pre-trained language models as the base. For example, the currently best-performing LGESQL model uses GRAPPA as the base. HIE-SQL model.
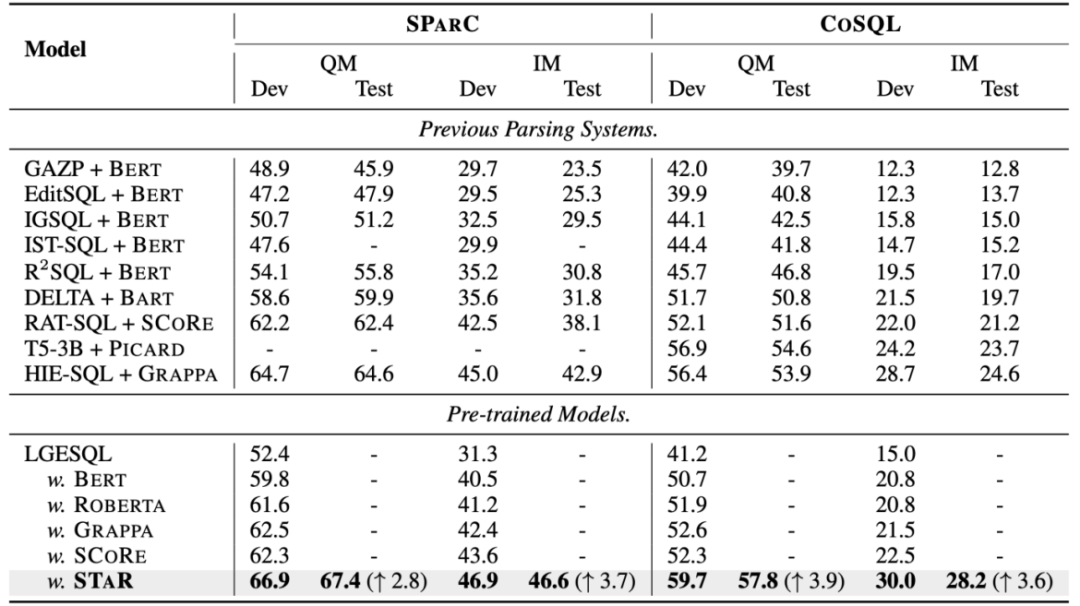
##Figure 4. Experimental results on SParC and CoSQL data sets
Ablation Experiment Results This article also adds a complete ablation experiment to illustrate the effectiveness of each module in the STAR model. The results of the ablation experiment are shown in Figure 5. When the SST or UDT pre-training targets are removed, the effect will drop significantly. However, the experimental results combining all pre-training targets have achieved the best results on all data sets, which illustrates that SST and UDT validity. In addition, this study conducted further experiments on two SQL similarity calculation methods in UDT. As can be seen from Figure 6, both SQL similarity calculation methods can improve the effect of the STAR model, and the combined effect is the best. .
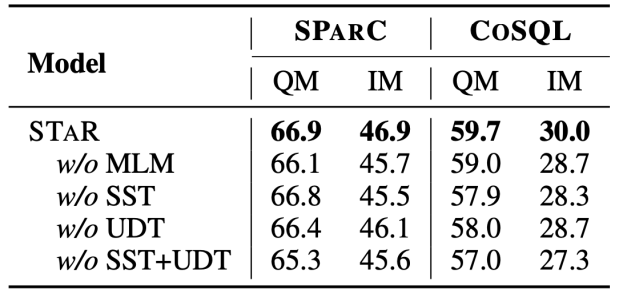
Figure 5. Ablation experiment results for pre-trained targets.
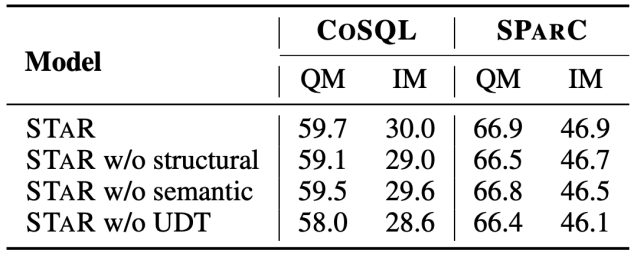
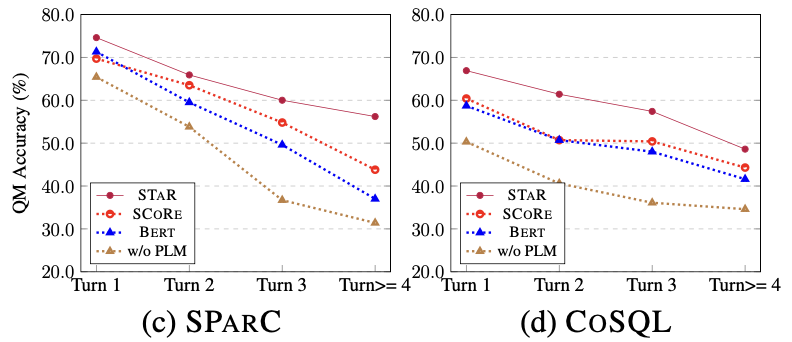
##Figure 6. Similarity calculation for SQL Ablation experimental results of the method. Model effects of samples of different difficulties As shown in Figure 7, from the experimental results of samples of different difficulties on the two data sets of SParC and CoSQL, it can be seen that the STAR model has far better prediction effects for samples of various difficulties. Better than other comparison methods, the effect is remarkable even in the most difficult extra hard samples. Figure 7. Experimental results of samples of different difficulty on SParC and CoSQL data sets. The model effect of different rounds of samples As shown in Figure 8, from The experimental results of different rounds of samples on the two data sets of SParC and CoSQL can be seen that as the number of dialogue rounds increases, the QM index of the baseline model decreases sharply, while the STAR model even in the third and fourth rounds Can show more stable performance. This shows that the STAR model can better track and explore interaction states in the conversation history to help the model better parse the current conversation. Figure 8. Experimental results of different rounds of samples on SParC and CoSQL data sets. Example Analysis In order to evaluate the actual effect of the STAR model, this study uses CoSQL Two samples were selected in the validation set, and the SQL query statements generated by the SCoRe model and the STAR model were compared in Figure 9 . From the first example, we can see that the STAR model can well use the schema state information of historical SQL (for example, [car_names.Model]), thereby correctly generating the SQL query statement for the third round of dialogue, while the SCoRe model cannot Track this mode status information. In the second example, the STAR model effectively tracks long-term conversational dependencies between the first and fourth rounds of utterances, and by tracking and referencing “the number of” messages in the second round of conversations, in the fourth The SQL keyword [SELECT COUNT (*)] is correctly generated in the round SQL query statement. However, the SCoRe model cannot track this long-term dependency and is interfered by the third round of utterances to generate incorrect SQL query statements. Figure 9. Example analysis. ModelScope model open source community The model trained in this article on the CoSQL data set , has been integrated into the ModelScope model open source community. Readers can directly select the V100 GPU environment in the notebook and use the demo model for multiple rounds of Text-to-SQL semantic parsing tasks through a simple pipeline. In this paper, the research team proposed a novel and effective multi- Wheel table knowledge pre-training model (STAR model). For multi-round Text-to-SQL semantic parsing tasks, the STAR model proposes table pre-training goals based on schema state tracking and dialogue dependency tracking, which respectively track the intent of SQL query statements and natural language questions in multi-round interactions. The STAR model has achieved very good results in two authoritative multi-round semantic parsing lists, occupying the first place on the list for 10 consecutive months. Finally, students who are interested in the SIAT-NLP group of the Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences are welcome to apply for postdoc/doctoral/master/internship positions. Please send your resume to min.yang @siat.ac.cn. 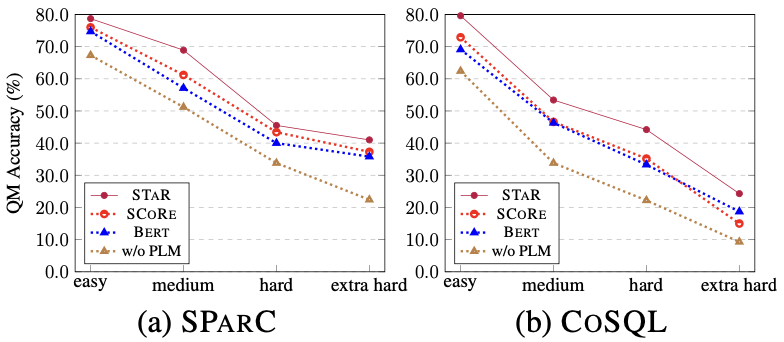
The above is the detailed content of Top of the international authoritative list of conversational semantic parsing SParC and CoSQL, the new multi-round dialogue table knowledge pre-training model STAR interpretation. For more information, please follow other related articles on the PHP Chinese website!
 How much is Snapdragon 8gen2 equivalent to Apple?
How much is Snapdragon 8gen2 equivalent to Apple?
 How to resolve WerFault.exe application error
How to resolve WerFault.exe application error
 absolutelayout
absolutelayout
 Mongodb and mysql are easy to use and recommended
Mongodb and mysql are easy to use and recommended
 number_format usage
number_format usage
 rgb to hexadecimal conversion
rgb to hexadecimal conversion
 How to make charts and data analysis charts in PPT
How to make charts and data analysis charts in PPT
 What are the commonly used third-party libraries in PHP?
What are the commonly used third-party libraries in PHP?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



