


Xi Xiaoyao Science and Technology Talks Original
Author | Xiaoxi, Python
If you are a novice at large models, the first time you see the weird combination of the words GPT, PaLm, and LLaMA will make What do you think? If I go deeper and see weird words like BERT, BART, RoBERTa, and ELMo popping up one after another, I wonder if I, as a novice, will go crazy?
Even a veteran who has been in the small circle of NLP for a long time, with the explosive development speed of large models, may be confused and unable to keep up with this rapidly changing large model. Which martial arts is used by which faction? At this time, you may need to ask for a large model review to help! This large model review "Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond" launched by researchers from Amazon, Texas A&M University and Rice University provides us with a way to build a "family tree" This article has learned about the past, present and future of large models represented by ChatGPT, and based on the tasks, it has built a very comprehensive practical guide for large models, introduced to us the advantages and disadvantages of large models in different tasks, and finally pointed out the Current risks and challenges of the model.
Paper title:
Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
Paper link://m.sbmmt.com/link/ f50fb34f27bd263e6be8ffcf8967ced0
Project homepage://m.sbmmt.com/link/968b15768f3d19770471e9436d97913c
The pursuit of the "source of all evil" of large models should probably start with the article "Attention is All You Need". Based on this article, the machine translation model Transformer composed of multiple groups of Encoder and Decoder proposed by the Google Machine Translation team begins. , the development of large models has generally followed two paths. One path is to abandon the Decoder part and only use the Encoder as a pre-training model for the encoder. Its most famous representative is the Bert family. These models began to try the "unsupervised pre-training" method to better utilize the large-scale natural language data that is easier to obtain than other data, and the "unsupervised" method is Masked Language Model (MLM), through Let Mask remove some words in the sentence, and let the model learn the ability to use context to predict the words removed by Mask. When Bert came out, it was considered a bomb in the field of NLP. At the same time, SOTA was used in many common tasks of natural language processing, such as sentiment analysis, named entity recognition, etc. Except for Bert and ALBert proposed by Google, outstanding representatives of the Bert family In addition, there are Baidu's ERNIE, Meta's RoBERTa, Microsoft's DeBERTa, etc.
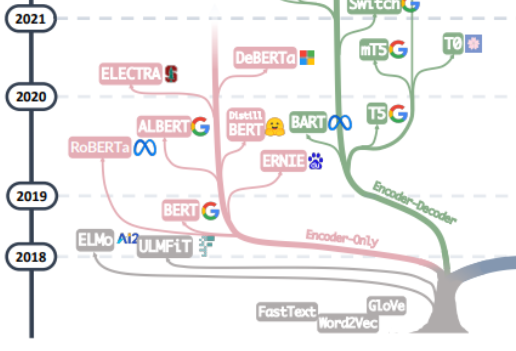
It is a pity that Bert’s approach failed to break through Scale Law, and this point is determined by the main force of the current large model, that is, another path of large model development. The GPT family has truly achieved this by abandoning the Encoder part and based on the Decoder part. The success of the GPT family comes from a researcher's surprising discovery: "Expanding the size of the language model can significantly improve the ability of zero-shot (zero-shot) and small-shot (few-shot) learning." This is consistent with the Bert family based on fine-tuning. There is a big difference, and it is also the source of the magical power of today's large-scale language models. The GPT family is trained based on predicting the next word given the previous word sequence. Therefore, GPT initially appeared only as a text generation model, and the emergence of GPT-3 was a turning point in the fate of the GPT family. GPT-3 was the first It shows people the magical capabilities brought by large models beyond text generation itself, and shows the superiority of these autoregressive language models. Starting from GPT-3, the current ChatGPT, GPT-4, Bard, PaLM, and LLaMA have flourished, bringing about the current era of large models.

From merging the two branches of this family tree, you can see the early days of Word2Vec and FastText, to the early exploration of ELMo and ULFMiT in pre-training models, and then to Bert Hengkong It was a hit, but the GPT family worked quietly until the stunning debut of GPT-3. ChatGPT soared into the sky. In addition to the iteration of technology, we can also see that OpenAI silently adhered to its own technical path and eventually became the undisputed leader of LLMs. See We have seen Google’s significant theoretical contribution to the entire Encoder-Decoder model architecture, Meta’s continued generous participation in large model open source projects, and of course the trend of LLMs gradually moving towards “closed” source since GPT-3. It is very likely that in the future most research will have to become API-Based research.

In the final analysis, does the magical ability of large models come from GPT? I think the answer is no. Almost every leap in capabilities of the GPT family has made important improvements in the quantity, quality, and diversity of pre-training data. The training data of the large model includes books, articles, website information, code information, etc. The purpose of inputting these data into the large model is to fully and accurately reflect the "human being" by telling the large model words, grammar, syntax and Semantic information allows the model to gain the ability to recognize context and generate coherent responses to capture aspects of human knowledge, language, culture, etc.
Generally speaking, in the face of many NLP tasks, we can classify them into zero samples, few samples and multiple samples from the perspective of data annotation information. Undoubtedly, LLMs are the most appropriate method for zero-shot tasks. With almost no exceptions, large models are far ahead of other models on zero-shot tasks. At the same time, few-sample tasks are also very suitable for the application of large models. By displaying "question-answer" pairs for large models, the performance of large models can be enhanced. This approach is also generally called In-Context Learning. Although large models can also cover multi-sample tasks, fine-tuning may still be the best method. Of course, under some constraints such as privacy and computing, large models may still be useful.

At the same time, the fine-tuned model is likely to face the problem of changes in the distribution of training data and test data. Significantly, the fine-tuned model generally performs very well on OOD data. Difference. Correspondingly, LLMs perform much better because they do not have an explicit fitting process. The typical ChatGPT reinforcement learning based on human feedback (RLHF) performs well in most out-of-distribution classification and translation tasks. It also performs well on the medical diagnostic dataset DDXPlus designed for OOD evaluation.
Many times, "Large models are good!" This assertion is followed by the question "How to use large models and when to use them?" "When faced with a specific task, should we choose fine-tuning or start using the large model without thinking? This paper summarizes a practical "decision flow" to help us determine whether to use a large model based on a series of questions such as "whether it is necessary to imitate humans", "whether reasoning capabilities are required", "whether it is multi-tasking".
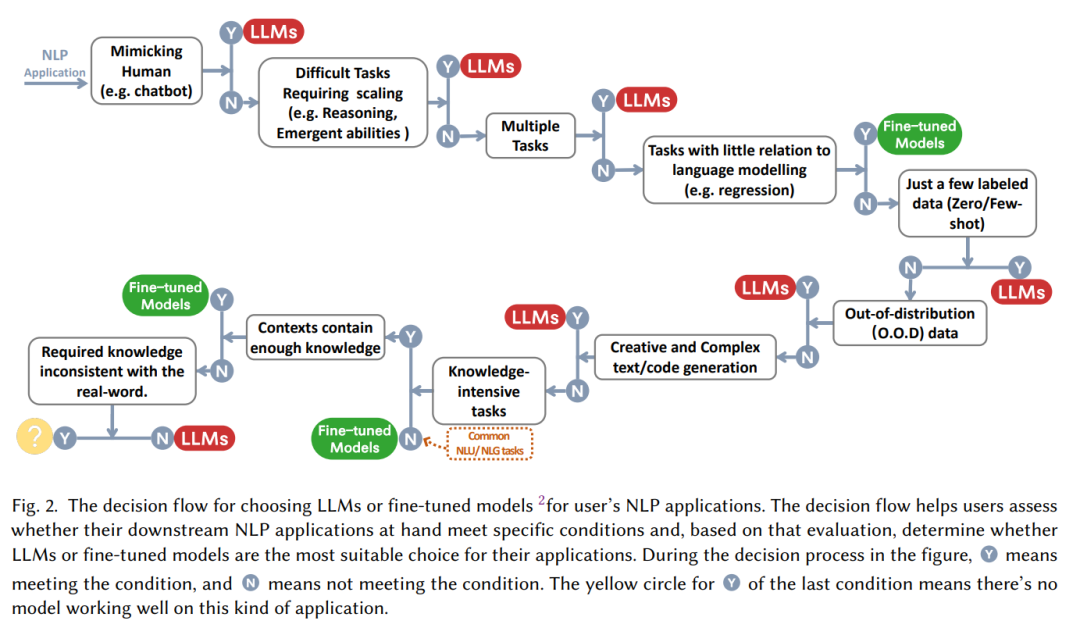
From the perspective of NLP task classification:
currently has a large amount of rich labeled data For many NLP tasks, fine-tuned models may still have a firm hold on the advantage. In most data sets, LLMs are inferior to fine-tuned models. Specifically:
In short, for most traditional natural language understanding tasks, fine-tuned models perform better. Of course, the potential of LLMs is limited by the Prompt project that may not be fully released (in fact, the fine-tuning model has not reached the upper limit). At the same time, in some niche fields, such as Miscellaneous Text Classification, Adversarial NLI and other tasks, LLMs have stronger capabilities. The generalization ability thus leads to better performance, but for now, for maturely labeled data, fine-tuning the model may still be the optimal solution for traditional tasks.
Compared with natural language understanding, natural language generation may be the stage for large models. The main goal of natural language generation is to create coherent, smooth, and meaningful sequences. It can usually be divided into two categories. One is tasks represented by machine translation and paragraph information summary, and the other is more open natural writing. Tasks such as writing emails, writing news, creating stories, etc. Specifically:
Knowledge-intensive tasks generally refer to tasks that rely strongly on background knowledge, domain-specific expertise, or general world knowledge. Knowledge-intensive tasks are different from simple patterns. Recognition and syntax analysis require "common sense" about our real world and the ability to use it correctly. Specifically:
It is worth noting that in knowledge-intensive tasks, large models are not always effective. Sometimes, large models may be useless or even wrong for real-world knowledge, which is "inconsistent" Knowledge can sometimes make large models perform worse than random guessing. For example, the Redefine Math task requires the model to choose between the original meaning and the redefined meaning. This requires the ability to be exactly opposite to the knowledge learned by large-scale language models. Therefore, the performance of LLMs is even worse than random. guess.
The scalability of LLMs can greatly enhance the ability of pre-trained language models. When the model size increases exponentially, some key capabilities such as reasoning will gradually expand with the parameters. When activated, the arithmetic reasoning and common sense reasoning capabilities of LLMs are extremely powerful visible to the naked eye. In this type of tasks:
In addition to reasoning, as the scale of the model grows, some Emergent Abilities will also appear in the model, such as coincidence operations, logical derivation, concept understanding, etc. However, there is also an interesting phenomenon called the "U-shaped phenomenon", which refers to the phenomenon that as the scale of LLMs increases, the model performance first increases and then begins to decline. The typical representative is the problem of redefining mathematics mentioned above. This Such phenomena call for more in-depth and detailed research on the principles of large models.
Large models will inevitably be part of our work and life for a long time in the future, and for such a "big guy" that is highly interactive with our lives, In addition to performance, efficiency, cost and other issues, the security issue of large-scale language models is almost the top priority among all challenges faced by large models. Machine hallucination is the main problem of large models that currently has no excellent solution. , biased or harmful hallucinations output by large models will have serious consequences for users. At the same time, as the "credibility" of LLMs increases, users may become overly dependent on LLMs and believe that they can provide accurate information. This foreseeable trend increases the security risks of large models.
In addition to misleading information, due to the high quality and low cost of the text generated by LLMs, LLMs may be used as a tool for attacks such as hatred, discrimination, violence, and rumors. LLMs may also be attacked for non-malicious purposes. Attackers provide illegal information or steal privacy. According to reports, Samsung employees accidentally leaked top-secret data such as the source code attributes of the latest program and internal meeting records related to hardware while using ChatGPT to handle work.
In addition, the key to whether large models can be used in sensitive fields, such as health care, finance, law, etc., lies in the issue of the "credibility" of large models. , at present, the robustness of large models with zero samples often decreases. At the same time, LLMs have been shown to be socially biased or discriminatory, with many studies observing significant performance differences between demographic categories such as accent, religion, gender, and race. This can lead to "fairness" issues for large models.
Finally, if we break away from social issues and make a summary, we can also look into the future of large model research. The main challenges currently faced by large models can be classified as follows:
The above is the detailed content of The big model review is here! One article will help you clarify the evolution history of large models of global AI giants. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



