


The field of image generation seems to be changing again.
Just now, OpenAI open sourced a consistency model that is faster and better than the diffusion model:
You can generate high-quality images without adversarial training!
As soon as this blockbuster news was released, it immediately detonated the academic circle.

Although the paper itself was released in a low-key manner in March, at that time it was generally believed that it was just a cutting-edge research of OpenAI and the details would not really be made public.

Unexpectedly, an open source came directly this time. Some netizens immediately started testing the effect and found that it only takes about 3.5 seconds to generate about 64 256×256 images:
Game over!

This is the image effect generated by this netizen, it looks pretty good:

Also Netizens joked: This time OpenAI is finally open!

It is worth mentioning that the first author of the paper, OpenAI scientist Song Yang, is a Tsinghua alumnus. At the age of 16, he entered Tsinghua’s basic mathematics and science class through the Leadership Program.
Let’s take a look at what kind of research OpenAI has open sourced this time.
As an image generation AI, the biggest feature of the Consistency Model is that it is fast and good.
Compared with the diffusion model, it has two main advantages:
First, it can directly generate high-quality image samples without adversarial training.
Secondly, compared to the diffusion model which may require hundreds or even thousands of iterations, the consistency model only needs one or two steps to handle a variety of image tasks - including coloring, Denoising, super-scoring, etc., can all be done in a few steps without requiring explicit training for these tasks. (Of course, if few-sample learning is performed, the generation effect will be better)
 So how does the consistency model achieve this effect?
So how does the consistency model achieve this effect?
From a principle point of view, the birth of the consistency model is related to the ODE (ordinary differential equation) generation diffusion model.
As can be seen in the figure, ODE will first convert the image data into noise step by step, and then perform a reverse solution to learn to generate images from the noise.
In this process, the authors tried to map any point on the ODE trajectory (such as Xt, Xt and Xr) to its origin (such as X0) for generative modeling.
Subsequently, this mapped model was named the consistency model because their outputs are all at the same point on the same trajectory:
 Based on this The idea is that the consistency model no longer needs to go through long iterations to generate a relatively high-quality image, but can be generated in one step.
Based on this The idea is that the consistency model no longer needs to go through long iterations to generate a relatively high-quality image, but can be generated in one step.
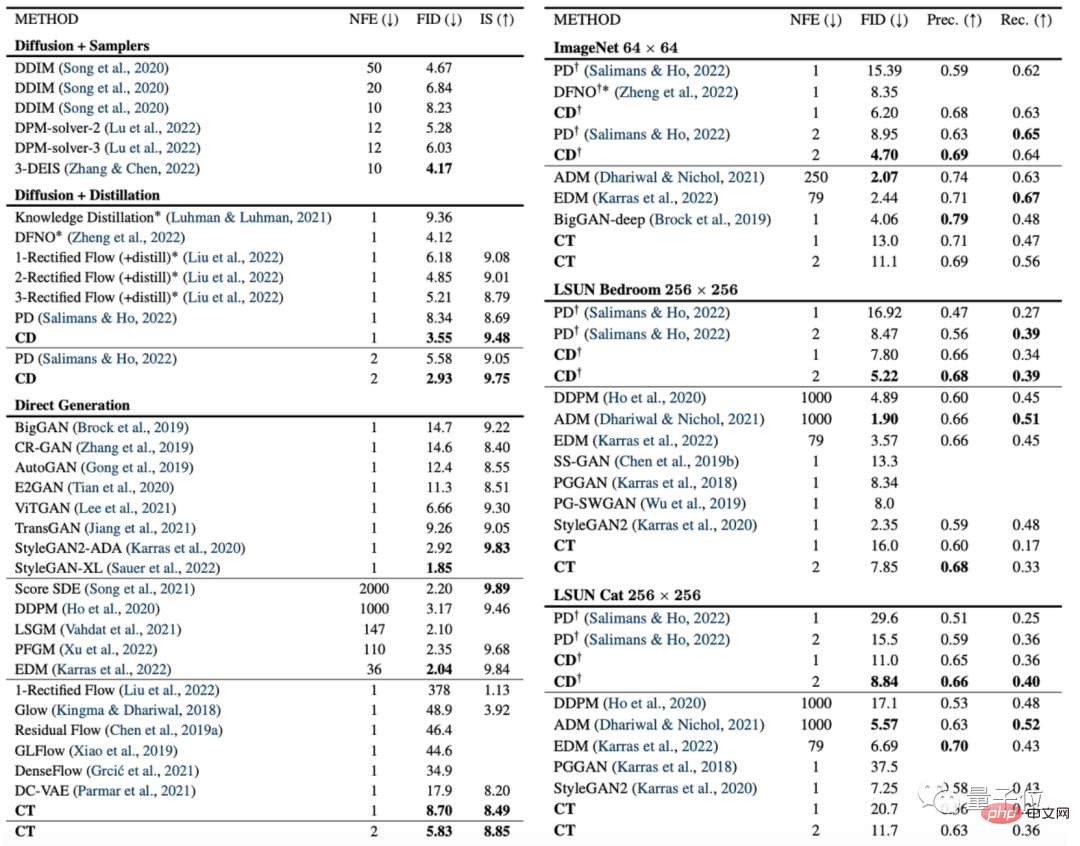
The following figure is a comparison of the consistency model (CD) and the diffusion model (PD) on the image generation index FID.
Among them, PD is the abbreviation of progressive distillation (progressive distillation), a latest diffusion model method proposed by Stanford and Google Brain last year, and CD (consistency distillation) is the consistency distillation method.
It can be seen that in almost all data sets, the image generation effect of the consistency model is better than that of the diffusion model. The only exception is the 256×256 room data set:
 In addition, the authors also compared diffusion models, consistency models, GAN and other models on various other data sets:
In addition, the authors also compared diffusion models, consistency models, GAN and other models on various other data sets:
However, some netizens mentioned that the images generated by the open source AI consistency model are still too small:
It’s sad that this open source The images generated by the version are still too small. It would be very exciting if an open source version that generates larger images could be provided.
# Some netizens also speculated that OpenAI may not have been trained yet. But maybe after training, we may not be able to get the code (manual dog head).
But regarding the significance of this work, TechCrunch said:
If you have a bunch of GPUs, then use the diffusion model to iterate more than 1,500 times in a minute or two, and the effect of generating images will certainly be extremely good. OK
But if you want to generate images in real time on your mobile phone or during a chat conversation, then obviously the diffusion model is not the best choice.
The consistency model is the next important move of OpenAI.
I hope OpenAI will open source a wave of image generation AI with higher resolution~
Song Yang is the first author of the paper and is currently a research scientist at OpenAI.

#When he was 14 years old, he was selected into the "Tsinghua University New Centenary Leadership Program" with unanimous votes from 17 judges. In the college entrance examination the following year, he became the top scorer in science in Lianyungang City and was successfully admitted to Tsinghua University.
In 2016, Song Yang graduated from Tsinghua University’s basic mathematics and physics class, and then went to Stanford for further study. In 2022, Song Yang received a PhD in computer science from Stanford and then joined OpenAI.
During his doctoral period, his first paper "Score-Based Generative Modeling through Stochastic Differential Equations" also won the ICLR 2021 Outstanding Paper Award.

According to information on his personal homepage, starting from January 2024, Song Yang will officially join the Department of Electronics and Department of Computational Mathematical Sciences at the California Institute of Technology as an assistant professor.
Project address:
//m.sbmmt.com/link/4845b84d63ea5fa8df6268b8d1616a8f
Paper address:
//m.sbmmt.com/link/5f25fbe144e4a81a1b0080b6c1032778
Reference link:
[1]https://twitter.com/alfredplpl/status/1646217811898011648
[2]https://twitter.com/_akhaliq/status/1646168119658831874
The above is the detailed content of OpenAI's new generation model is an open source explosion! Faster and stronger than Diffusion, a work by Tsinghua alumnus Song Yang. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



