


In the human senses, a picture can blend many experiences together. For example, a beach picture can remind us of the sound of waves, the texture of sand, the breeze blowing on our face, and even inspire Inspiration for a poem. This "binding" property of images provides a large source of supervision for learning visual features by aligning them with any sensory experience associated with them.
Ideally, visual features should be learned by aligning all senses for a single joint embedding space. However, this requires obtaining paired data for all sensory types and combinations from the same set of images, which is obviously not feasible.
Recently, many methods learn image features aligned with text, audio, etc. These methods use a single pair of modalities or at most several visual modalities. The final embedding is limited to the modality pairs used for training. Therefore, video-audio embedding cannot be directly used for image-text tasks and vice versa. A major obstacle in learning true joint embeddings is the lack of large amounts of multimodal data where all modalities are fused together.
Today, Meta AI proposed ImageBind, which learns a single shared representation space by leveraging multiple types of image paired data. This study does not require a data set in which all modalities appear simultaneously with each other. Instead, it takes advantage of the binding properties of the image. As long as the embedding of each modality is aligned with the image embedding, all modalities will be quickly achieved. Align . Meta AI also announced the corresponding code.

 At the same time, the researchers said that ImageBind can be initialized using large-scale visual language models (such as CLIP), thereby leveraging the rich images of these models and text representation. Therefore, ImageBind requires very little training and can be applied to a variety of different modalities and tasks.
At the same time, the researchers said that ImageBind can be initialized using large-scale visual language models (such as CLIP), thereby leveraging the rich images of these models and text representation. Therefore, ImageBind requires very little training and can be applied to a variety of different modalities and tasks.
ImageBind is part of Meta’s commitment to creating multimodal AI systems that learn from all relevant types of data. As the number of modalities increases, ImageBind opens the floodgates for researchers to try to develop new holistic systems, such as combining 3D and IMU sensors to design or experience immersive virtual worlds. It also provides a rich way to explore your memory by using a combination of text, video and images to search for images, videos, audio files or text information.
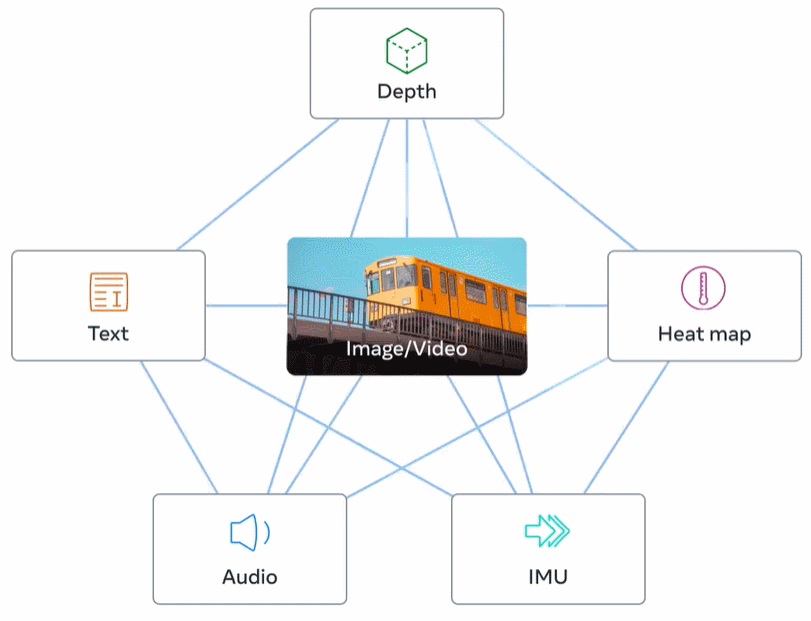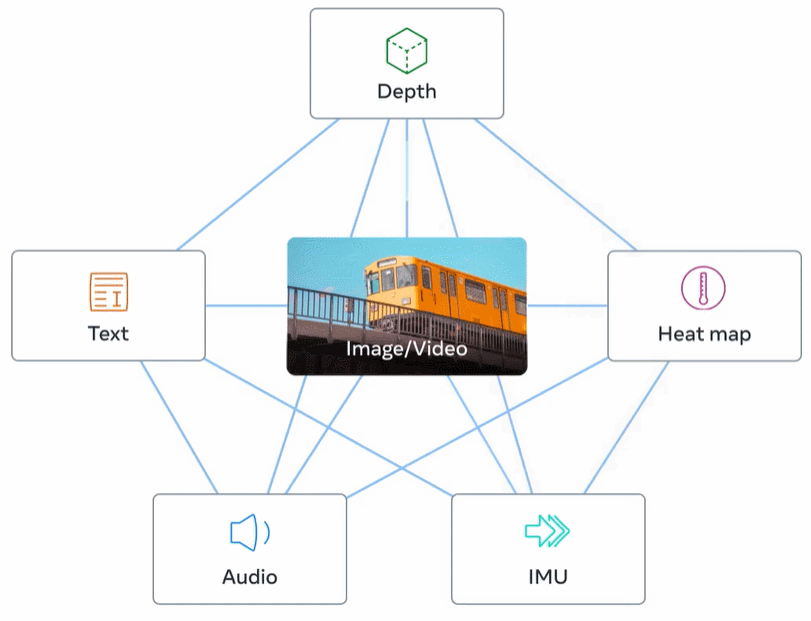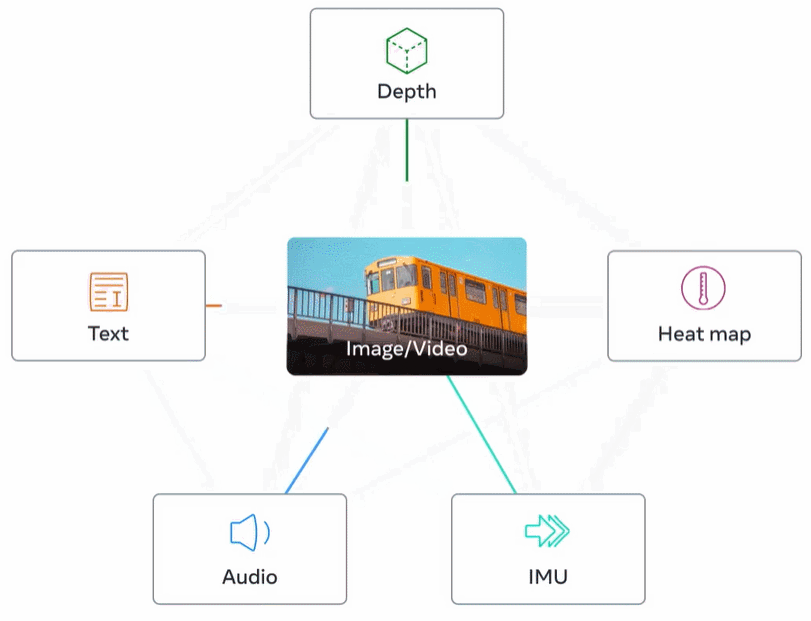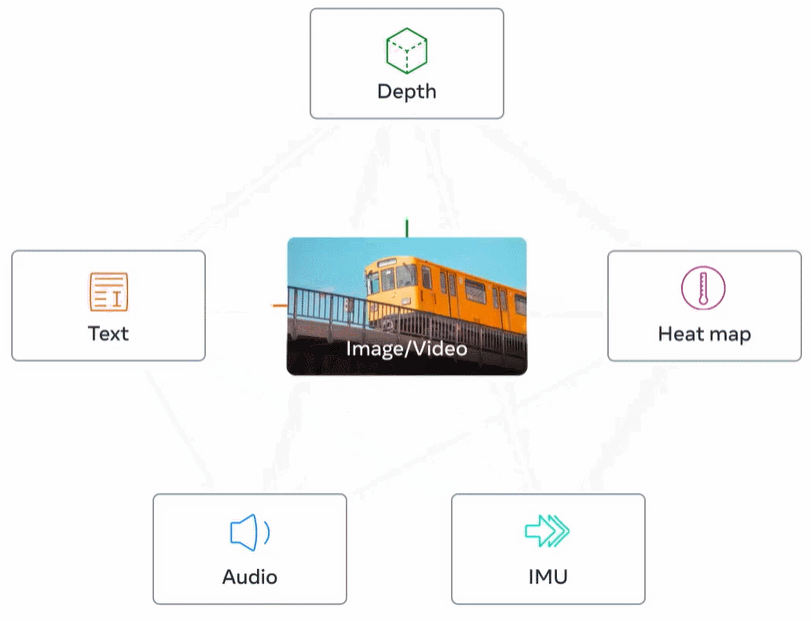
Bind content and images, learn a single embedding space
Ideally, a joint embedding space with different types of data allows the model to learn other modalities while learning visual features. Previously, it was often necessary to collect all possible pairwise data combinations in order for all modalities to learn a joint embedding space.
ImageBind circumvents this conundrum by leveraging recent large-scale visual language models. It extends the zero-shot capabilities of recent large-scale visual language models to new modalities that are relevant to images. Natural pairings, such as video-audio and image-depth data, to learn a joint embedding space. For the other four modalities (audio, depth, thermal imaging, and IMU readings), the researchers used naturally paired self-supervised data.
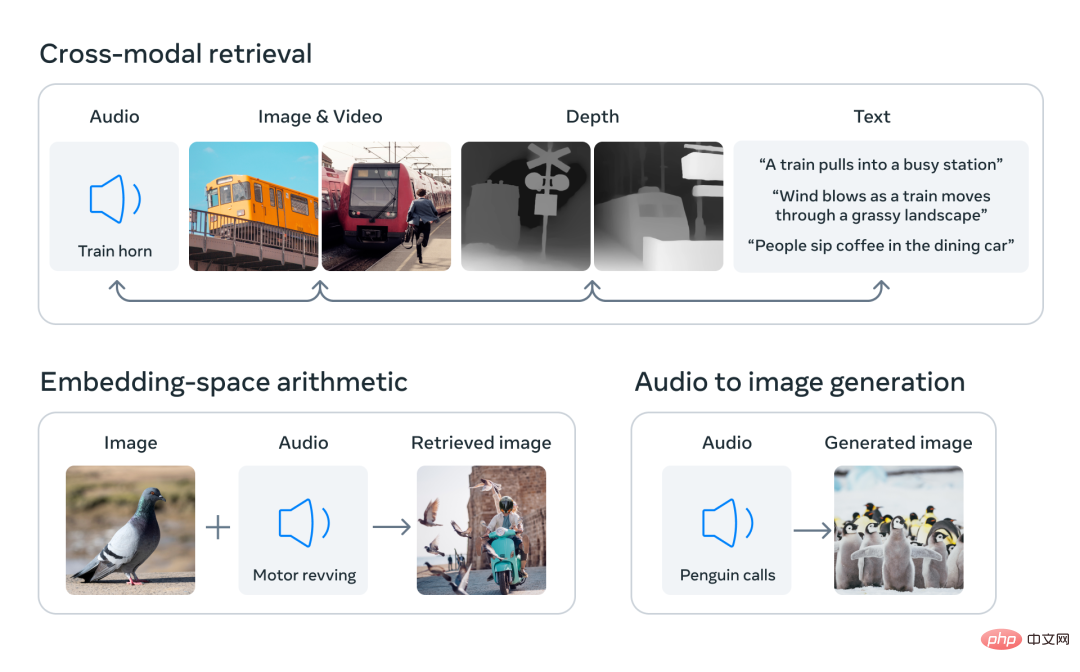
By aligning the embeddings of the six modalities into a common space, ImageBind can cross-modally retrieve different types of content that are not observed simultaneously, add embeddings of different modalities to naturally combine their semantics, and use Meta AI's audio embeddings with pre-trained DALLE-2 decoders (designed Used with CLIP text embedding) to implement audio-to-image generation.
There are a large number of images appearing together with text on the Internet, so training image-text models has been widely studied. ImageBind takes advantage of the binding properties of images that can be connected to various modalities, such as connecting text to images using network data, or connecting motion to video using video data captured in a wearable camera with an IMU sensor. .
Visual representations learned from large-scale network data can be used as targets for learning different modal features. This allows ImageBind to align the image with any modalities present at the same time, naturally aligning those modalities with each other. Modalities such as heat maps and depth maps that have strong correlation with images are easier to align. Non-visual modalities such as audio and IMU (Inertial Measurement Unit) have weaker correlations. For example, specific sounds such as a baby crying can match various visual backgrounds.
ImageBind demonstrates that image pairing data is sufficient to bind these six modalities together. The model can explain content more fully, allowing different modalities to "talk" to each other and find connections between them without observing them simultaneously. For example, ImageBind can link audio and text without observing them together. This enables other models to "understand" new modalities without requiring any resource-intensive training.
ImageBind's powerful scaling performance enables this model to replace or enhance many artificial intelligence models, enabling them to use other modalities. For example, while Make-A-Scene can generate an image by using a text prompt, ImageBind can upgrade it to generate an image using audio, such as laughter or the sound of rain.
Meta's analysis shows that ImageBind's scaling behavior improves with the strength of the image encoder. In other words, ImageBind's ability to align modalities scales with the power and size of the visual model. This suggests that larger visual models are beneficial for non-visual tasks, such as audio classification, and that the benefits of training such models extend beyond computer vision tasks.
In experiments, Meta used ImageBind’s audio and depth encoders and compared them with previous work on zero-shot retrieval and audio and depth classification tasks.
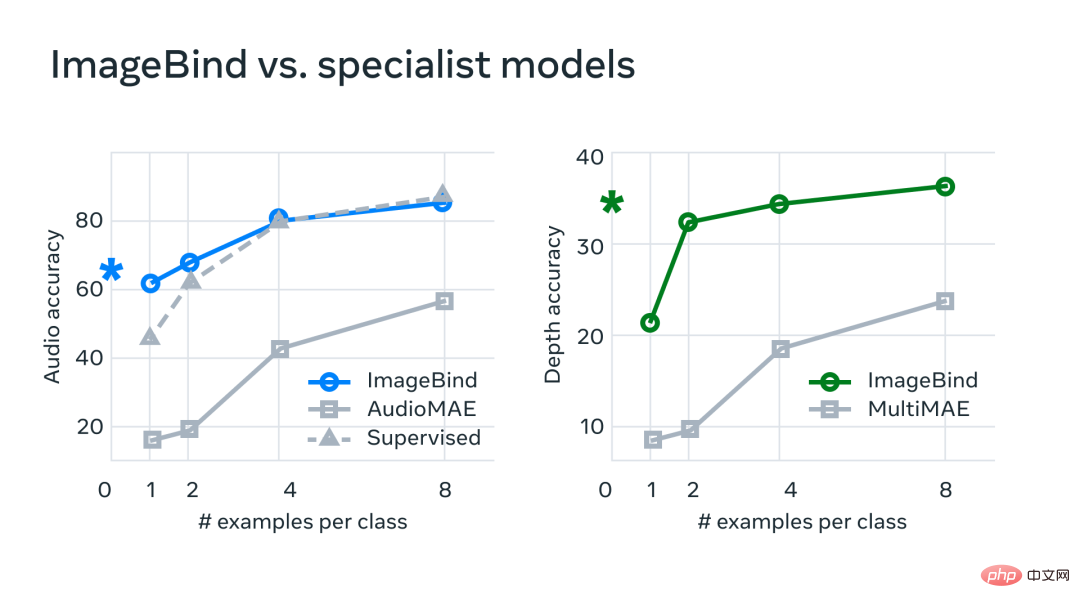
##On benchmarks, ImageBind outperforms experts in audio and depth Model.
Meta found that ImageBind can be used for few-shot audio and deep classification tasks and outperforms previous custom-made methods. For example, ImageBind significantly outperforms Meta's self-supervised AudioMAE model trained on Audioset, and its supervised AudioMAE model fine-tuned on audio classification.
Additionally, ImageBind achieves new SOTA performance on the cross-modal zero-shot recognition task, outperforming even state-of-the-art models trained to recognize concepts in that modality.
The above is the detailed content of Using images to align all modalities, Meta open source multi-sensory AI basic model to achieve great unification. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



