


In the python virtual machine implemented by cpython, the following is the source code of cpython’s internal list implementation:
typedef struct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number
* currently in use is ob_size.
* Invariants:
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
* list.sort() temporarily sets allocated to -1 to detect mutations.
*
* Items must normally not be NULL, except during construction when
* the list is not yet visible outside the function that builds it.
*/
Py_ssize_t allocated;
} PyListObject;
#define PyObject_VAR_HEAD PyVarObject ob_base;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
typedef struct _object {
_PyObject_HEAD_EXTRA // 这个宏定义为空
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;After expanding the above structure, the structure of PyListObject is roughly as follows:

Now let’s explain the meaning of each field above:
Py_ssize_t, an integer data type.
ob_refcnt represents the number of reference counts of the object. This is very useful for garbage collection. Later we will analyze the garbage collection part of the virtual machine in depth.
ob_type, indicates the data type of this object. In python, sometimes it is necessary to judge the data type of the data. For example, the two keywords of isinstance and type will be used. field.
ob_size, this field indicates how many elements there are in this list.
ob_item, this is a pointer, pointing to the address where the python object data is actually saved. The approximate memory layout between them is as follows:
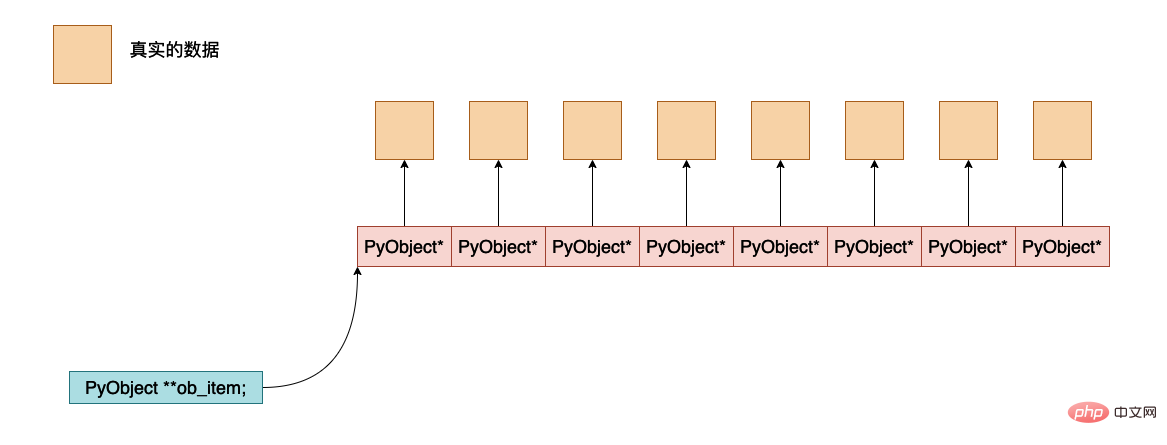
allocated, this indicates how many (PyObject *) are allocated in total during memory allocation. The actual allocated memory space is allocated * sizeof(PyObject *).
The first thing you need to understand is that an array is created for the list inside the python virtual machine. All The released memory spaces created will not be released directly, but the first addresses of these memory spaces will be saved in this array, so that the next time you apply to create a new list, you do not need to apply for memory space again. It is enough to directly reuse the memory that needs to be released before.
/* Empty list reuse scheme to save calls to malloc and free */ #ifndef PyList_MAXFREELIST #define PyList_MAXFREELIST 80 #endif static PyListObject *free_list[PyList_MAXFREELIST]; static int numfree = 0;
free_list, saves the first address of the released memory space.
numfree, how many addresses in free_list can be used currently? In fact, the first numfree addresses in free_list can be used.
The code to create a linked list is as follows (some codes have been deleted for simplicity and only the core part is retained):
PyObject *
PyList_New(Py_ssize_t size)
{
PyListObject *op;
size_t nbytes;
/* Check for overflow without an actual overflow,
* which can cause compiler to optimise out */
if ((size_t)size > PY_SIZE_MAX / sizeof(PyObject *))
return PyErr_NoMemory();
nbytes = size * sizeof(PyObject *);
// 如果 numfree 不等于 0 那么说明现在 free_list 有之前使用被释放的内存空间直接使用这部分即可
if (numfree) {
numfree--;
op = free_list[numfree]; // 将对应的首地址返回
_Py_NewReference((PyObject *)op); // 这条语句的含义是将 op 这个对象的 reference count 设置成 1
} else {
// 如果没有空闲的内存空间 那么就需要申请内存空间 这个函数也会对对象的 reference count 进行初始化 设置成 1
op = PyObject_GC_New(PyListObject, &PyList_Type);
if (op == NULL)
return NULL;
}
/* 下面是申请列表对象当中的 ob_item 申请内存空间,上面只是给列表本身申请内存空间,但是列表当中有许多元素
保存这些元素也是需要内存空间的 下面便是给这些对象申请内存空间
*/
if (size <= 0)
op->ob_item = NULL;
else {
op->ob_item = (PyObject **) PyMem_MALLOC(nbytes);
// 如果申请内存空间失败 则报错
if (op->ob_item == NULL) {
Py_DECREF(op);
return PyErr_NoMemory();
}
// 对元素进行初始化操作 全部赋值成 0
memset(op->ob_item, 0, nbytes);
}
// Py_SIZE 是一个宏
Py_SIZE(op) = size; // 这条语句会被展开成 (PyVarObject*)(ob))->ob_size = size
// 分配数组的元素个数是 size
op->allocated = size;
// 下面这条语句对于垃圾回收比较重要 主要作用就是将这个列表对象加入到垃圾回收的链表当中
// 后面如果这个对象的 reference count 变成 0 或者其他情况 就可以进行垃圾回收了
_PyObject_GC_TRACK(op);
return (PyObject *) op;
}In cpython, the bytecode for creating a linked list is BUILD_LIST, we can find the execution steps corresponding to the corresponding bytecode in the file ceval.c:
TARGET(BUILD_LIST) {
PyObject *list = PyList_New(oparg);
if (list == NULL)
goto error;
while (--oparg >= 0) {
PyObject *item = POP();
PyList_SET_ITEM(list, oparg, item);
}
PUSH(list);
DISPATCH();
}From the above explanation steps corresponding to the BUILD_LIST bytecode, we can know that when interpreting and executing the bytecode BUILD_LIST The function PyList_New is indeed called to create a new list.
static PyObject *
// 这个函数的传入参数是列表本身 self 需要 append 的元素为 v
// 也就是将对象 v 加入到列表 self 当中
listappend(PyListObject *self, PyObject *v)
{
if (app1(self, v) == 0)
Py_RETURN_NONE;
return NULL;
}
static int
app1(PyListObject *self, PyObject *v)
{
// PyList_GET_SIZE(self) 展开之后为 ((PyVarObject*)(self))->ob_size
Py_ssize_t n = PyList_GET_SIZE(self);
assert (v != NULL);
// 如果元素的个数已经等于允许的最大的元素个数 就报错
if (n == PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError,
"cannot add more objects to list");
return -1;
}
// 下面的函数 list_resize 会保存 ob_item 指向的位置能够容纳最少 n+1 个元素(PyObject *)
// 如果容量不够就会进行扩容操作
if (list_resize(self, n+1) == -1)
return -1;
// 将对象 v 的 reference count 加一 因为列表当中使用了一次这个对象 所以对象的引用计数需要进行加一操作
Py_INCREF(v);
PyList_SET_ITEM(self, n, v); // 宏展开之后 ((PyListObject *)(op))->ob_item[i] = v
return 0;
}static int
list_resize(PyListObject *self, Py_ssize_t newsize)
{
PyObject **items;
size_t new_allocated;
Py_ssize_t allocated = self->allocated;
/* Bypass realloc() when a previous overallocation is large enough
to accommodate the newsize. If the newsize falls lower than half
the allocated size, then proceed with the realloc() to shrink the list.
*/
// 如果列表已经分配的元素个数大于需求个数 newsize 的就直接返回不需要进行扩容
if (allocated >= newsize && newsize >= (allocated >> 1)) {
assert(self->ob_item != NULL || newsize == 0);
Py_SIZE(self) = newsize;
return 0;
}
/* This over-allocates proportional to the list size, making room
* for additional growth. The over-allocation is mild, but is
* enough to give linear-time amortized behavior over a long
* sequence of appends() in the presence of a poorly-performing
* system realloc().
* The growth pattern is: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88, ...
*/
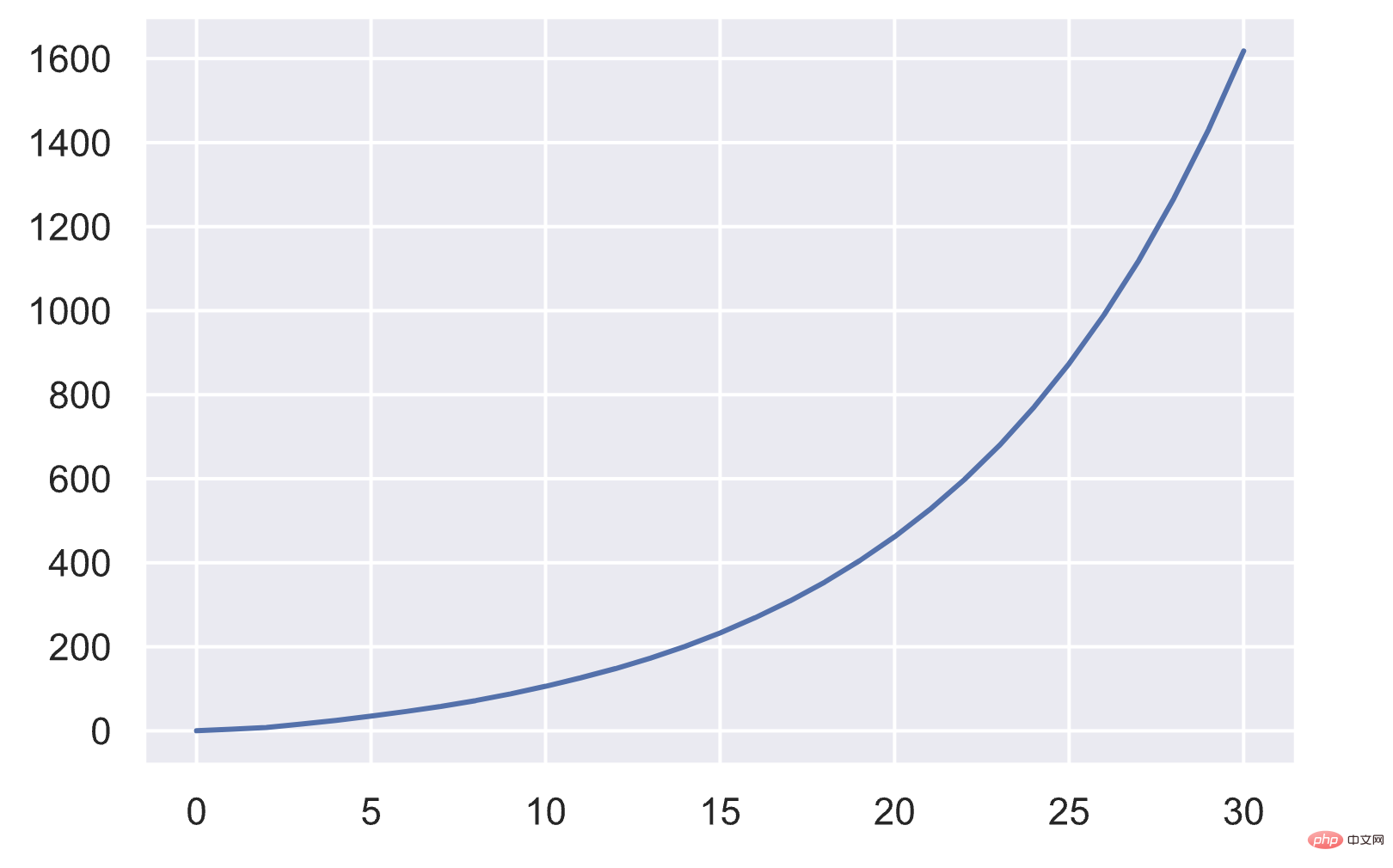
// 这是核心的数组大小扩容机制 new_allocated 表示新增的数组大小
new_allocated = (newsize >> 3) + (newsize < 9 ? 3 : 6);
/* check for integer overflow */
if (new_allocated > PY_SIZE_MAX - newsize) {
PyErr_NoMemory();
return -1;
} else {
new_allocated += newsize;
}
if (newsize == 0)
new_allocated = 0;
items = self->ob_item;
if (new_allocated <= (PY_SIZE_MAX / sizeof(PyObject *)))
// PyMem_RESIZE 这是一个宏定义 会申请 new_allocated 个数元素并且将原来数组的元素拷贝到新的数组当中
PyMem_RESIZE(items, PyObject *, new_allocated);
else
items = NULL;
// 如果没有申请到内存 那么报错
if (items == NULL) {
PyErr_NoMemory();
return -1;
}
// 更新列表当中的元素数据
self->ob_item = items;
Py_SIZE(self) = newsize;
self->allocated = new_allocated;
return 0;
}Under the above expansion mechanism, the size of the array changes roughly as follows:
newsize&asymp ;size⋅(size 1)1/8
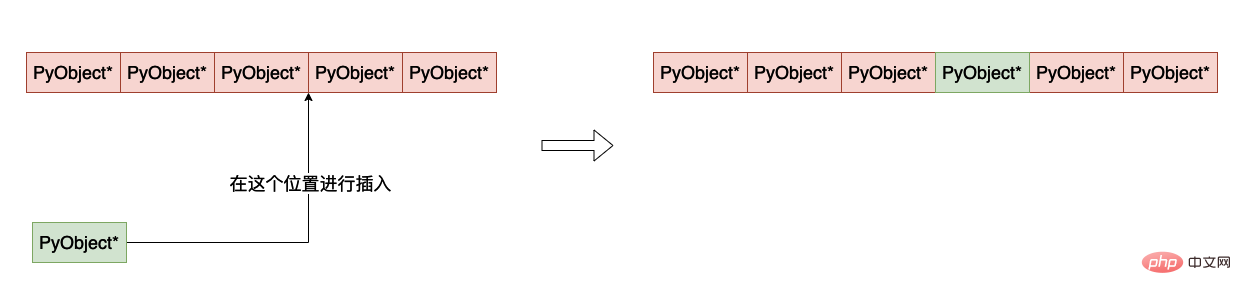
Inserting a data into the list is relatively simple, you only need to set the insertion position Just move it back one position with the elements behind it. The whole process is as follows:
The implementation of the list insertion function in cpython is as follows:
The parameter op indicates which linked list to insert elements into.
The parameter where indicates where in the linked list to insert the element.
Parameter newitem represents the newly inserted element.
int
PyList_Insert(PyObject *op, Py_ssize_t where, PyObject *newitem)
{
// 检查是否是列表类型
if (!PyList_Check(op)) {
PyErr_BadInternalCall();
return -1;
}
// 如果是列表类型则进行插入操作
return ins1((PyListObject *)op, where, newitem);
}
static int
ins1(PyListObject *self, Py_ssize_t where, PyObject *v)
{
Py_ssize_t i, n = Py_SIZE(self);
PyObject **items;
if (v == NULL) {
PyErr_BadInternalCall();
return -1;
}
// 如果列表的元素个数超过限制 则进行报错
if (n == PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError,
"cannot add more objects to list");
return -1;
}
// 确保列表能够容纳 n + 1 个元素
if (list_resize(self, n+1) == -1)
return -1;
// 这里是 python 的一个小 trick 就是下标能够有负数的原理
if (where < 0) {
where += n;
if (where < 0)
where = 0;
}
if (where > n)
where = n;
items = self->ob_item;
// 从后往前进行元素的拷贝操作,也就是将插入位置及其之后的元素往后移动一个位置
for (i = n; --i >= where; )
items[i+1] = items[i];
// 因为链表应用的对象,因此对象的 reference count 需要进行加一操作
Py_INCREF(v);
// 在列表当中保存对象 v
items[where] = v;
return 0;
}For the array ob_item, deleting an element requires moving the elements behind this element forward, so the whole process is as follows Display:

static PyObject *
listremove(PyListObject *self, PyObject *v)
{
Py_ssize_t i;
// 编译数组 ob_item 查找和对象 v 相等的元素并且将其删除
for (i = 0; i < Py_SIZE(self); i++) {
int cmp = PyObject_RichCompareBool(self->ob_item[i], v, Py_EQ);
if (cmp > 0) {
if (list_ass_slice(self, i, i+1,
(PyObject *)NULL) == 0)
Py_RETURN_NONE;
return NULL;
}
else if (cmp < 0)
return NULL;
}
// 如果没有找到这个元素就进行报错处理 在下面有一个例子重新编译 python 解释器 将这个错误内容修改的例子
PyErr_SetString(PyExc_ValueError, "list.remove(x): x not in list");
return NULL;
}The content of the executed python program is:
data = [] data.remove(1)
The following is the entire modification content and error result:
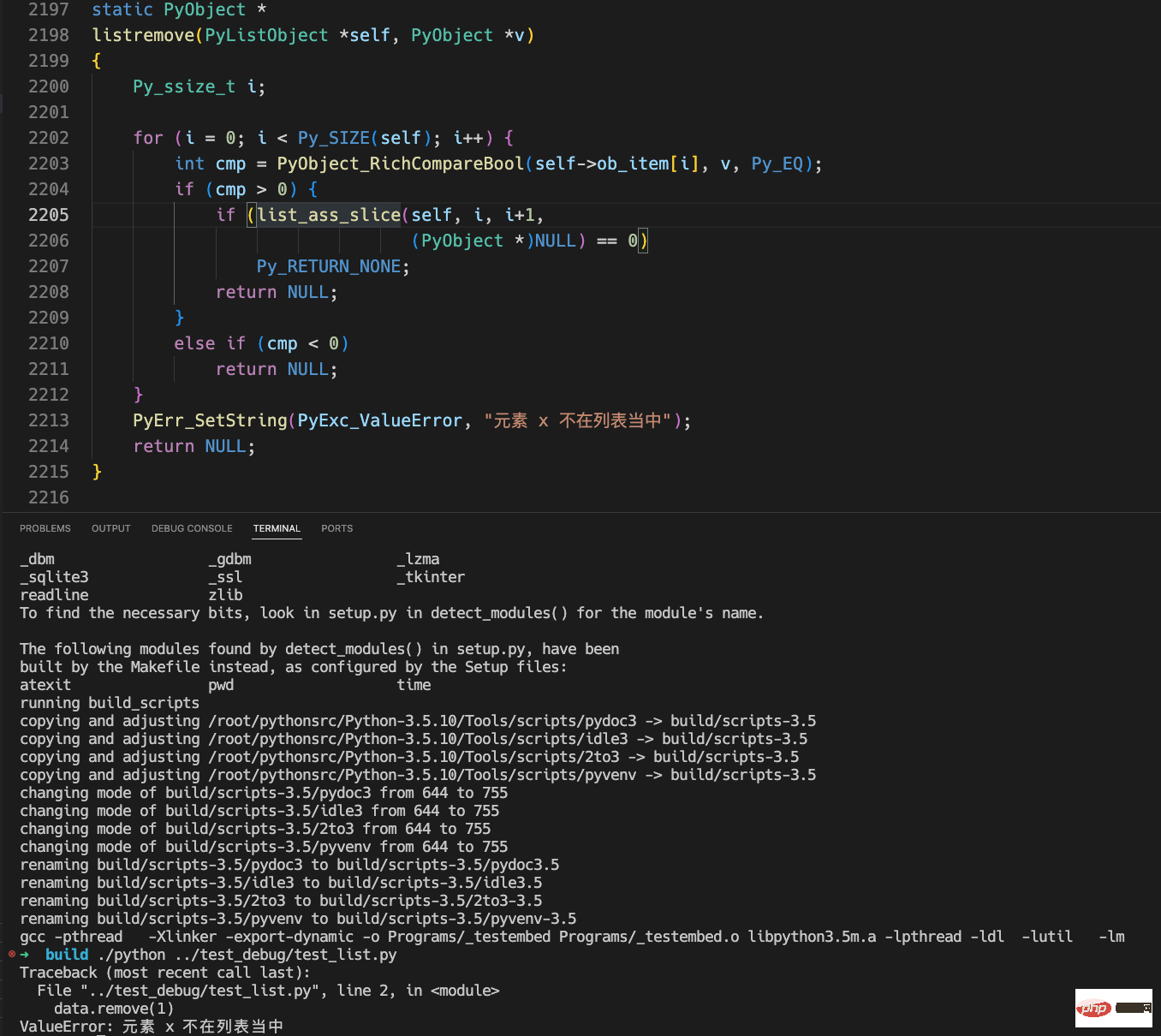
What we can see from the above results is that the error message we modified is printed correctly.
The main function of this function is to count how many elements in the list self are equal to v.
static PyObject *
listcount(PyListObject *self, PyObject *v)
{
Py_ssize_t count = 0;
Py_ssize_t i;
for (i = 0; i < Py_SIZE(self); i++) {
int cmp = PyObject_RichCompareBool(self->ob_item[i], v, Py_EQ);
// 如果相等则将 count 进行加一操作
if (cmp > 0)
count++;
// 如果出现错误就返回 NULL
else if (cmp < 0)
return NULL;
}
// 将一个 Py_ssize_t 的变量变成 python 当中的对象
return PyLong_FromSsize_t(count);
}This is a shallow copy function of the list. It only copies the pointer of the real python object and does not copy the real python object. You can know from the following code The copy of the list is a shallow copy. When b modifies the elements in the list, the elements in the list a also change. If you need to perform a deep copy, you can use the deepcopy function in the copy module.
>>> a = [1, 2, [3, 4]] >>> b = a.copy() >>> b[2][1] = 5 >>> b [1, 2, [3, 5]]
copy 函数对应的源代码(listcopy)如下所示:
static PyObject *
listcopy(PyListObject *self)
{
return list_slice(self, 0, Py_SIZE(self));
}
static PyObject *
list_slice(PyListObject *a, Py_ssize_t ilow, Py_ssize_t ihigh)
{
// Py_SIZE(a) 返回列表 a 当中元素的个数(注意不是数组的长度 allocated)
PyListObject *np;
PyObject **src, **dest;
Py_ssize_t i, len;
if (ilow < 0)
ilow = 0;
else if (ilow > Py_SIZE(a))
ilow = Py_SIZE(a);
if (ihigh < ilow)
ihigh = ilow;
else if (ihigh > Py_SIZE(a))
ihigh = Py_SIZE(a);
len = ihigh - ilow;
np = (PyListObject *) PyList_New(len);
if (np == NULL)
return NULL;
src = a->ob_item + ilow;
dest = np->ob_item;
// 可以看到这里循环拷贝的是指向真实 python 对象的指针 并不是真实的对象
for (i = 0; i < len; i++) {
PyObject *v = src[i];
// 同样的因为并没有创建新的对象,但是这个对象被新的列表使用到啦 因此他的 reference count 需要进行加一操作 Py_INCREF(v) 的作用:将对象 v 的 reference count 加一
Py_INCREF(v);
dest[i] = v;
}
return (PyObject *)np;
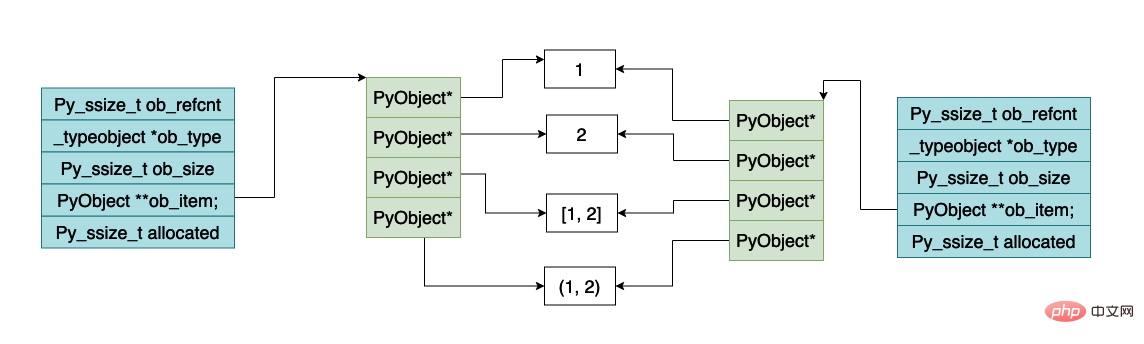
}下图就是使用 a.copy() 浅拷贝的时候,内存的布局的示意图,可以看到列表指向的对象数组发生了变化,但是数组中元素指向的 python 对象并没有发生变化。
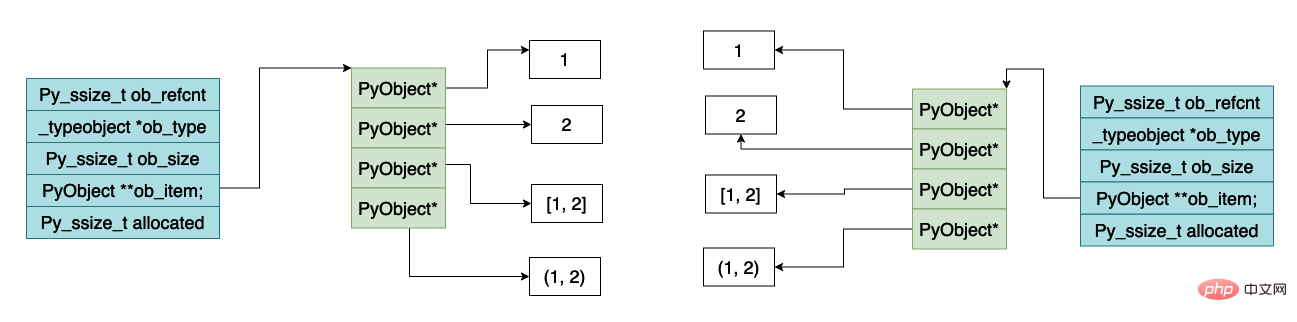
下面是对列表对象进行深拷贝的时候内存的大致示意图,可以看到数组指向的 python 对象也是不一样的。
当我们在使用 list.clear() 的时候会调用下面这个函数。清空列表需要注意的就是将表示列表当中元素个数的 ob_size 字段设置成 0 ,同时将列表当中所有的对象的 reference count 设置进行 -1 操作,这个操作是通过宏 Py_XDECREF 实现的,这个宏还会做另外一件事就是如果这个对象的引用计数变成 0 了,那么就会直接释放他的内存。
static PyObject *
listclear(PyListObject *self)
{
list_clear(self);
Py_RETURN_NONE;
}
static int
list_clear(PyListObject *a)
{
Py_ssize_t i;
PyObject **item = a->ob_item;
if (item != NULL) {
/* Because XDECREF can recursively invoke operations on
this list, we make it empty first. */
i = Py_SIZE(a);
Py_SIZE(a) = 0;
a->ob_item = NULL;
a->allocated = 0;
while (--i >= 0) {
Py_XDECREF(item[i]);
}
PyMem_FREE(item);
}
/* Never fails; the return value can be ignored.
Note that there is no guarantee that the list is actually empty
at this point, because XDECREF may have populated it again! */
return 0;
}在 python 当中如果我们想要反转类表当中的内容的话,就会使用这个函数 reverse 。
>>> a = [i for i in range(10)] >>> a.reverse() >>> a [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
其对应的源程序如下所示:
static PyObject *
listreverse(PyListObject *self)
{
if (Py_SIZE(self) > 1)
reverse_slice(self->ob_item, self->ob_item + Py_SIZE(self));
Py_RETURN_NONE;
}
static void
reverse_slice(PyObject **lo, PyObject **hi)
{
assert(lo && hi);
--hi;
while (lo < hi) {
PyObject *t = *lo;
*lo = *hi;
*hi = t;
++lo;
--hi;
}
}上面的源程序还是比较容易理解的,给 reverse_slice 传递的参数就是保存数据的数组的首尾地址,然后不断的将首尾数据进行交换(其实是交换指针指向的地址)。
The above is the detailed content of What is the implementation principle of lists in the Python virtual machine?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



