


At the beginning of this month, Meta launched the “Split Everything” model, which shocked the entire CV circle.
# In the past few days, a machine learning model called "Relate-Anything-Model (RAM)" has emerged. It gives the Segment Anything Model (SAM) the ability to identify various visual relationships between different visual concepts.
It is understood that the model was developed by the MMLab team of Nanyang Technological University and students from the VisCom Laboratory of King's College London and Tongji University in their spare time.
Demo address: https://huggingface.co/spaces/mmlab-ntu/ relate-anything-model
Code address: https://github.com/Luodian/RelateAnything
Dataset address: https://github.com/Jingkang50/OpenPSG
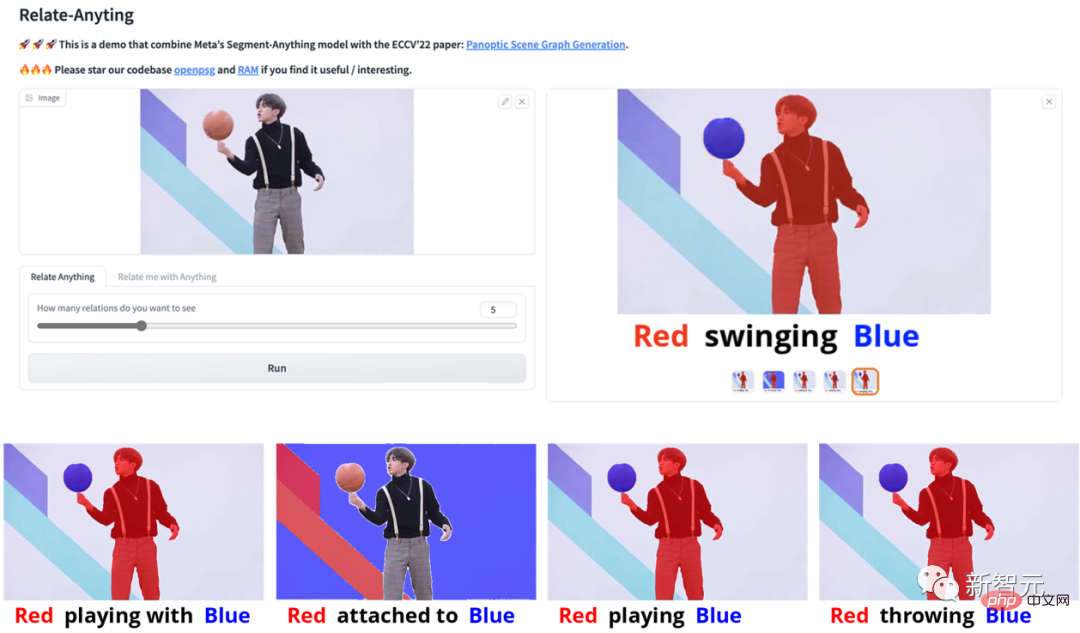
First, let’s Let’s take a look at the application example of “Relate-Anything-Model (RAM)”!
For example, the following image analysis results of the RAM model implementation of playing football, dancing and making friends are very impressive and well displayed. The model has excellent performance and potential for diverse applications.


The RAM model is based on the ECCV'22 SenseHuman Workshop & International Algorithm Example Competition "Panoptic Scene Graph Generation" track Champion program.

##Paper address: https://arxiv.org/abs/2302.02651
The PSG Challenge has a million-dollar prize and received various solutions submitted by 100 teams from around the world, including using advanced image segmentation methods and solving long-tail problems. In addition, the competition also received some innovative methods, such as scene graph-specific data augmentation techniques.
After evaluation, based on considerations such as performance indicators, novelty and significance of the solution, the Xiaohongshu team’s GRNet stood out as the winning method.

Before introducing the solution, we first introduce two classic PSG baseline methods, one of which is a two-stage method and the other is a single-stage method.
For the two-stage baseline method, as shown in Figure a, in the first stage, the pre-trained panoramic segmentation model Panoptic FPN is used to extract features, segmentation and classification predictions from the image. The features of each individual object are then fed to a classic scene graph generator such as IMP for scene graph generation adapted to the PSG task in the second stage. This two-stage approach allows the classic SGG method to be adapted to the PSG task with minimal modifications. As shown in Figure b, the single-stage baseline method PSGTR first uses CNN to extract image features, and then uses a transformer encoder-decoder similar to DETR to learn directly Triple representation. The Hungarian matcher is used to compare the predicted triples with the ground truth triples. Then, the optimization objective is to maximize the cost of matcher computation, and the total loss is calculated using cross-entropy DICE/F-1 loss for labeling and segmentation. 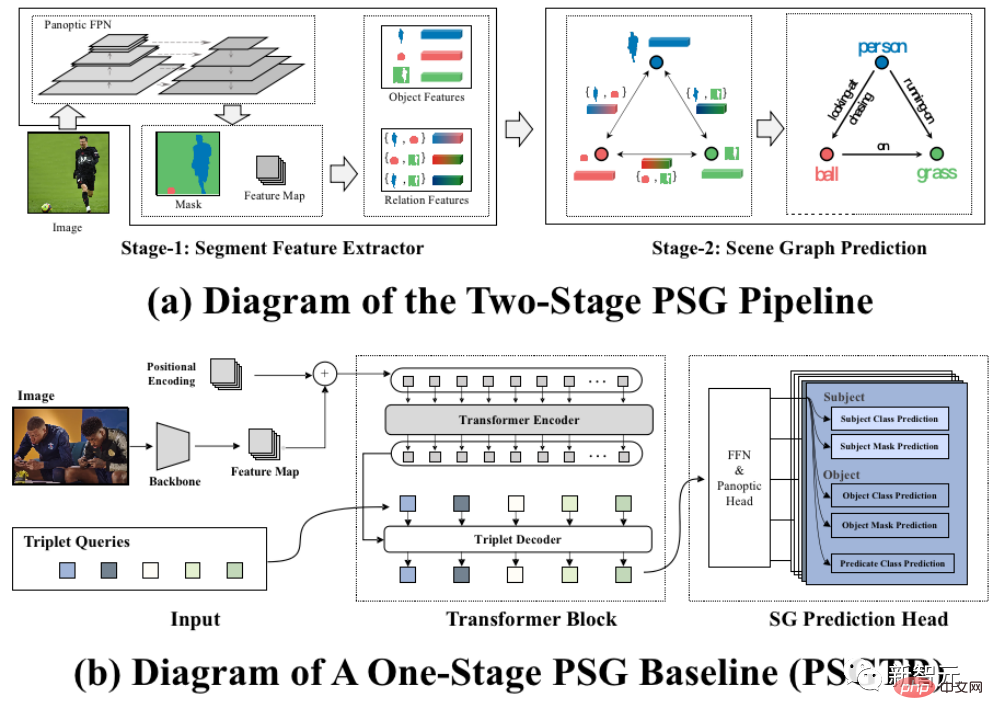
In the design process of the RAM model, The author refers to the two-stage structural paradigm of PSG champion scheme GRNet. Although the research in the original PSG article shows that single-stage models currently perform better than two-stage models, however, single-stage models often cannot achieve as good segmentation performance as two-stage models.
After observing different model structures, it is speculated that the excellent performance of the single-stage model in predicting relational triples may be due to direct supervision from the image feature map Signals are good for capturing relationships.
Based on this observation, the design of RAM, like GRNet, aims to find a trade-off between the two modes, by focusing on the two-stage paradigm and giving it a similar This is achieved by the ability to obtain global context in a single-stage paradigm.
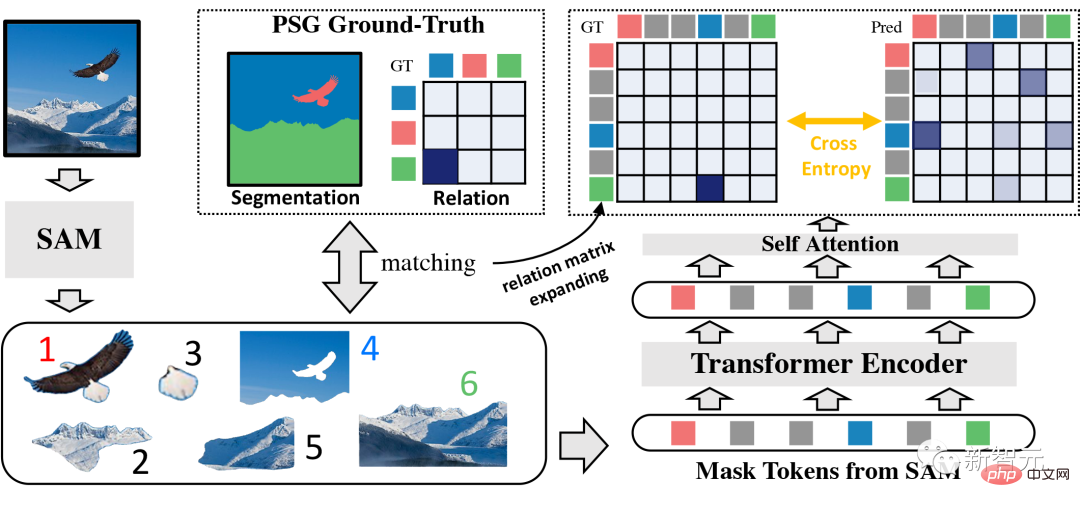
Specifically, Segment Anything Model (SAM) is first used as a feature extractor to identify and segment objects in the image, and the specific objects from the SAM segmenter are The object's intermediate feature map is fused with its corresponding segmentation to obtain object-level features.
Subsequently, the Transformer is used as a global context module, and the obtained object-level features are input into it after linear mapping. Through the cross-attention mechanism in the Transformer encoder, the output object features collect more global information from other objects.
#Finally, for each object-level feature output by the Transformer, the self-attention mechanism is used to further enrich the contextual information and complete the interaction between each object.
Please note that a category embedding is also added here to indicate the category of the object, and from this we get predictions of pairs of objects and their relationships. .
RAM Relation ClassificationDuring the training process, for each relationship category, a relationship binary classification task needs to be performed to determine the object pairs whether there is a relationship between them.
#Similar to GRNet, there are some special considerations for relational binary classification tasks. For example, PSG datasets usually contain two objects with multiple relationships, such as "people look at elephants" and "people feed elephants" exist simultaneously. To solve the multi-label problem, the authors convert relationship prediction from a single-label classification problem to a multi-label classification problem.
#Furthermore, since the PSG dataset The pursuit of accuracy and correlation may not be suitable for learning boundary relationships (such as "in" and "stop at" actually exist at the same time). To solve this problem, RAM adopts a self-training strategy that uses self-distilled labels for relationship classification and uses exponential moving average to dynamically update labels.
When calculating the relational binary classification loss, each predicted object must be paired with its corresponding underlying ground truth object. The Hungarian matching algorithm is used for this purpose.
# However, this algorithm is prone to instability, especially in the early training stages when the network accuracy is low. This may lead to different matching results for the same input, leading to inconsistent network optimization directions and making training more difficult.
In RAM, unlike the previous solution, the author can perform complete and detailed segmentation of almost any picture with the help of the powerful SAM model. Therefore, in In the process of matching prediction and GT, RAM naturally designed a new GT matching method: using the PSG data set to train the model.
#For each training image, SAM segments multiple objects, but only a few match the ground truth (GT) mask of PSG. The authors perform simple matching based on their intersection-union (IOU) scores so that (almost) every GT mask is assigned to a SAM mask. Afterwards, the author regenerated the relationship diagram based on the SAM mask, which naturally matched the model's predictions.
In the RAM model, the author uses the Segment Anything Model (SAM) to identify and segment objects in the image, and Extract features of each segmented object. The Transformer module is then used to interact between segmented objects to obtain new features. Finally, after these features are embedded into categories, the prediction results are output through the self-attention mechanism.
During the training process, in particular, the author proposed a new GT matching method and based on this method, calculated the pairing relationship between predictions and GT and classified their mutual relationship. In the supervised learning process of relation classification, the author regards it as a multi-label classification problem and adopts a self-training strategy to learn the boundary relations of labels.
Finally, I hope the RAM model can bring you more inspiration and innovation. If you also want to train a machine learning model that can find relationships, you can follow the work of this team and give feedback and suggestions at any time.

## Project address: https://github.com/Jingkang50/OpenPSG
The above is the detailed content of NTU proposed a new RAM model, using Meta to divide everything to get the relationship, and the singing and dancing sneak attack effect is excellent!. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



