


jieba is an excellent third-party library for Chinese word segmentation. Since each Chinese character in Chinese text is written continuously, we need to use a specific method to obtain each word in it. This method is called word segmentation. Jieba is a very excellent third-party library for Chinese word segmentation in the Python computing ecosystem. You need to install it to use it.
jieba library provides three word segmentation modes, but in fact, to achieve the word segmentation effect, it is enough to master only one function, which is very simple and effective.
To install third-party libraries, you need to use the pip tool and run the installation command on the command line (not IDLE). Note: You need to add the Python directory and the Scripts directory under it to the environment variables.
Use the command pip install jieba to install the third-party library. After installation, it will prompt successfully installed to inform you whether the installation is successful.
Principle of word segmentation: Simply put, the jieba library identifies word segmentation through the Chinese vocabulary library. It first uses a Chinese lexicon to calculate the association probabilities between Chinese characters that form words through the lexicon. Therefore, by calculating the probabilities between Chinese characters, the result of word segmentation can be formed. Of course, in addition to jieba's own Chinese vocabulary library, users can also add custom phrases to it, thereby making jieba's word segmentation closer to the use in certain specific fields.
jieba is a Chinese word segmentation library for python. Here is how to use it.
方式1: pip install jieba 方式2: 先下载 http://pypi.python.org/pypi/jieba/ 然后解压,运行 python setup.py install
Jieba’s three commonly used modes:
Accurate mode, Trying to cut the sentence into the most precise form, suitable for text analysis;
Full mode scans out all the words in the sentence that can be turned into words, which is very fast, but cannot resolve ambiguities ;
Search engine mode, based on the precise mode, re-segments long words to improve the recall rate and is suitable for search engine word segmentation.
You can use the jieba.cut and jieba.cut_for_search methods for word segmentation. The structure returned by both is an iterable generator. , you can use a for loop to get each word (unicode) obtained after word segmentation, or directly use jieba.lcut and jieba.lcut_for_search to return the list.
jieba.Tokenizer(dictionary=DEFAULT_DICT): Use this method to customize the tokenizer and use different dictionaries at the same time. jieba.dt is the default word segmenter, and all global word segmentation related functions are mappings of this word segmenter.
jieba.cut and jieba.lcut The acceptable parameters are as follows:
Strings that require word segmentation (unicode Or UTF-8 string, GBK string)
cut_all: whether to use full mode, the default value is False
HMM: used to control whether to use the HMM model, the default value is True
##jieba.cut_for_search and jieba.lcut_for_search Accepts 2 parameters:
True
# 全匹配
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=True)
print(list(seg_list)) # ['今天', '哪里', '都', '没去', '', '', '在家', '家里', '睡', '了', '一天']
# 精确匹配 默认模式
seg_list = jieba.cut("今天哪里都没去,在家里睡了一天", cut_all=False)
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']
# 精确匹配
seg_list = jieba.cut_for_search("今天哪里都没去,在家里睡了一天")
print(list(seg_list)) # ['今天', '哪里', '都', '没', '去', ',', '在', '家里', '睡', '了', '一天']Usage: jieba.load_userdict(dict_path)
University coursesThe following compares the differences between exact matching, full matching and using a custom dictionary:Deep learning
import jieba
test_sent = """
数学是一门基础性的大学课程,深度学习是基于数学的,尤其是线性代数课程
"""
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学', '课程', ',', '深度',
# '学习', '是', '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
words = jieba.cut(test_sent, cut_all=True)
print(list(words))
# ['\n', '数学', '是', '一门', '基础', '基础性', '的', '大学', '课程', '', '', '深度',
# '学习', '是', '基于', '数学', '的', '', '', '尤其', '是', '线性', '线性代数', '代数', '课程', '\n']
jieba.load_userdict("userdict.txt")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其', '是', '线性代数', '课程', '\n']
jieba.add_word("尤其是")
jieba.add_word("线性代数课程")
words = jieba.cut(test_sent)
print(list(words))
# ['\n', '数学', '是', '一门', '基础性', '的', '大学课程', ',', '深度学习', '是',
# '基于', '数学', '的', ',', '尤其是', '线性代数课程', '\n']也可以使用 jieba.analyse.TFIDF(idf_path=None) 新建 TFIDF 实例,idf_path 为 IDF 频率文件。
基于 TF-IDF 算法和TextRank算法的关键词抽取:
import jieba.analyse file = "sanguo.txt" topK = 12 content = open(file, 'rb').read() # 使用tf-idf算法提取关键词 tags = jieba.analyse.extract_tags(content, topK=topK) print(tags) # ['玄德', '程远志', '张角', '云长', '张飞', '黄巾', '封谞', '刘焉', '邓茂', '邹靖', '姓名', '招军'] # 使用textrank算法提取关键词 tags2 = jieba.analyse.textrank(content, topK=topK) # withWeight=True:将权重值一起返回 tags = jieba.analyse.extract_tags(content, topK=topK, withWeight=True) print(tags) # [('玄德', 0.1038549799467099), ('程远志', 0.07787459004363208), ('张角', 0.0722532891360849), # ('云长', 0.07048801593691037), ('张飞', 0.060972692853113214), ('黄巾', 0.058227157790330185), # ('封谞', 0.0563904127495283), ('刘焉', 0.05470798376886792), ('邓茂', 0.04917692565566038), # ('邹靖', 0.04427258239705188), ('姓名', 0.04219704283997642), ('招军', 0.04182041076757075)]
上面的代码是读取文件,提取出现频率最高的前12个词。
词性标注主要是标记文本分词后每个词的词性,使用例子如下:
import jieba
import jieba.posseg as pseg
# 默认模式
seg_list = pseg.cut("今天哪里都没去,在家里睡了一天")
for word, flag in seg_list:
print(word + " " + flag)
"""
使用 jieba 默认模式的输出结果是:
我 r
Prefix dict has been built successfully.
今天 t
吃 v
早饭 n
了 ul
"""
# paddle 模式
words = pseg.cut("我今天吃早饭了",use_paddle=True)
"""
使用 paddle 模式的输出结果是:
我 r
今天 TIME
吃 v
早饭 n
了 xc
"""paddle模式的词性对照表如下:
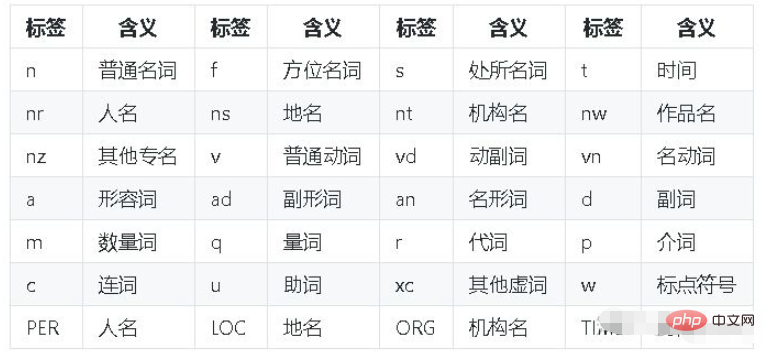
jieba分词有三种模式:精确模式、全模式和搜索引擎模式。
简单说,精确模式就是把一段文本精确的切分成若干个中文单词,若干个中文单词之间经过组合就精确的还原为之前的文本,其中不存在冗余单词。精确模式是最常用的分词模式。
进一步jieba又提供了全模式,全模式是把一段中文文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式或者有不同的角度来切分变成不同的词语,那么jieba在全模式下把这样的不同的组合都挖掘出来,所以如果用全模式来进行分词,分词的信息组合起来并不是精确的原有文本,会有很多的冗余。
而搜索引擎模式更加智能,它是在精确模式的基础上对长词进行再次切分,将长的词语变成更短的词语,进而适合搜索引擎对短词语的索引和搜索,在一些特定场合用的比较多。
jieba.lcut(s)
精确模式,能够对一个字符串精确地返回分词结果,而分词的结果使用列表形式来组织。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家")
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 2.489 seconds.
Prefix dict has been built successfully.
['中国', '是', '一个', '伟大', '的', '国家']jieba.lcut(s,cut_all=True)
全模式,能够返回一个列表类型的分词结果,但结果存在冗余。例如:
>>> import jieba
>>> jieba.lcut("中国是一个伟大的国家",cut_all=True)
['中国', '国是', '一个', '伟大', '的', '国家']jieba.lcut_for_search(s)
搜索引擎模式,能够返回一个列表类型的分词结果,也存在冗余。例如:
>>> import jieba
>>> jieba.lcut_for_search("中华人民共和国是伟大的")
['中华', '华人', '人民', '共和', '共和国', '中华人民共和国', '是', '伟大', '的']jieba.add_word(w)
向分词词库添加新词w
最重要的就是jieba.lcut(s)函数,完成精确的中文分词。
The above is the detailed content of How to use jieba library in Python?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



