


It is reported that GPT-4 will be released this week, and multi-modality will become one of its highlights. The current large language model is becoming a universal interface for understanding various modalities and can give reply texts based on different modal information. However, the content generated by the large language model is only limited to text. On the other hand, the current diffusion models DALL・E 2, Imagen, Stable Diffusion, etc. have set off a revolution in visual creation, but these models only support a single cross-modal function from text to image, and are still far from a universal generative model. distance. The multi-modal large model will be able to open up the capabilities of various modalities and realize conversion between any modalities, which is considered to be the future development direction of universal generative models.
The TSAIL team led by Professor Zhu Jun from the Department of Computer Science at Tsinghua University recently published a paper "One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale", which was the first to publish the multi-modal Some exploratory work on generative models has enabled mutual transformation between arbitrary modes.

##Paper link: https://ml.cs. tsinghua.edu.cn/diffusion/unidiffuser.pdf
##Open source code: https://github.com/thu-ml/unidiffuser
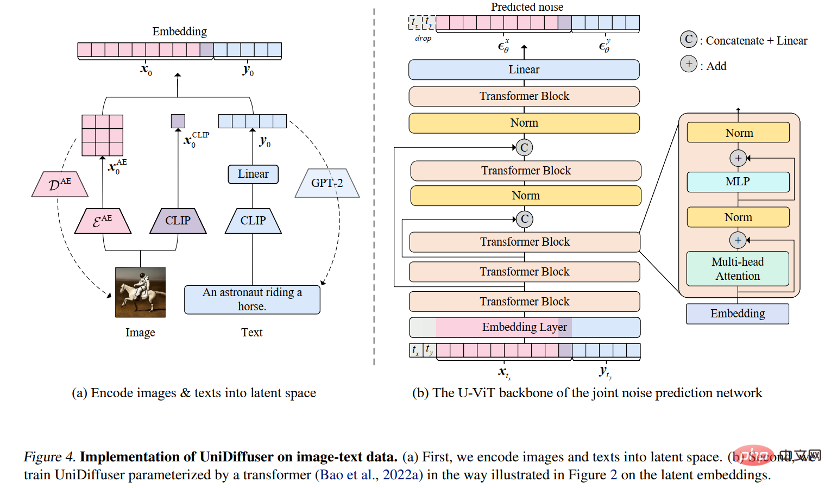
This paper proposes a probabilistic modeling framework UniDiffuser designed for multi-modality, and adopts the transformer-based network architecture U-ViT proposed by the team to use open source large-scale graphic and text data A model with one billion parameters was trained on LAION-5B, enabling an underlying model to complete a variety of generation tasks with high quality (Figure 1). To put it simply, in addition to one-way text generation, it can also realize multiple functions such as image generation, image and text joint generation, unconditional image and text generation, image and text rewriting, etc., which greatly improves the production efficiency of text and image content, and further improves the generation of text and graphics. The application imagination of formula model.The first author of this paper, Bao Fan, is currently a doctoral student. He was the previous proposer of Analytic-DPM. He won the outstanding paper award of ICLR 2022 (currently the only one) for his outstanding work in diffusion models. award-winning papers independently completed by mainland units).
In addition, Machine Heart has previously reported on the DPM-Solver fast algorithm proposed by the TSAIL team, which is still the fastest generation algorithm for diffusion models. The multi-modal large model is a concentrated display of the team's long-term in-depth accumulation of algorithms and principles of deep probabilistic models. Collaborators on this work include Li Chongxuan from Renmin University’s Hillhouse School of Artificial Intelligence, Cao Yue from Beijing Zhiyuan Research Institute, and others.

Effect Display
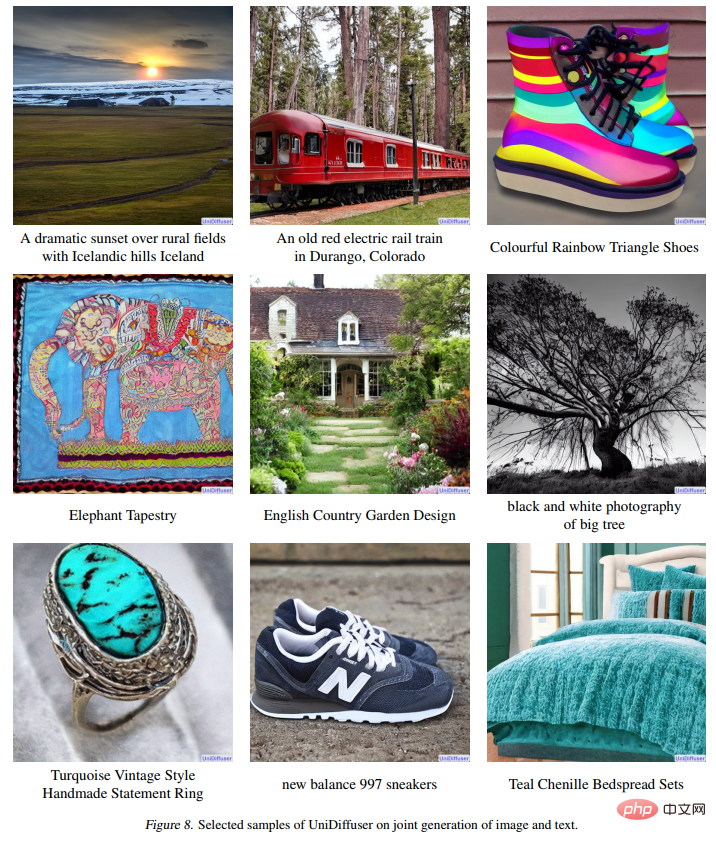
Figure 8 below shows the effect of UniDiffuser in jointly generating images and text:



The following figure 12 shows the effect of UniDiffuser on image rewriting:

The following figure 15 shows that UniDiffuser can jump back and forth between the two modes of graphics and text:

As shown in Figure 16 below UniDiffuser can interpolate two real images:
The research team divided the design of a general generative model into two sub-problems:
Probabilistic modeling framework
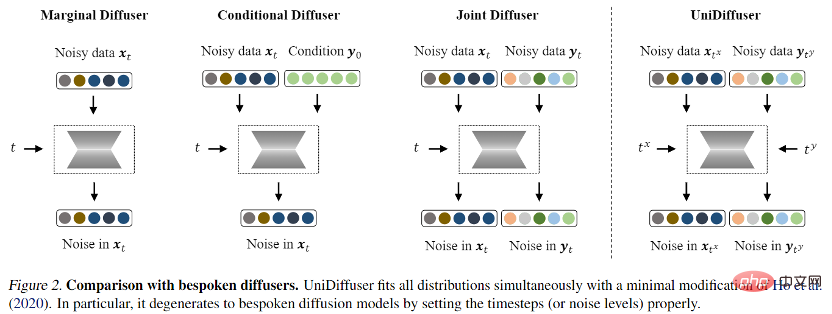
For the probabilistic modeling framework, the research team proposed UniDiffuser, a A probabilistic modeling framework for diffusion models. UniDiffuser can explicitly model all distributions in multimodal data, including marginal distributions, conditional distributions, and joint distributions. The research team found that diffusion model learning about different distributions can be unified into one perspective: first add a certain size of noise to the data of the two modalities, and then predict the noise on the data of the two modalities. The amount of noise on the two modal data determines the specific distribution. For example, setting the noise size of the text to 0 corresponds to the conditional distribution of the Vincentian diagram; setting the noise size of the text to the maximum value corresponds to the distribution of unconditional image generation; setting the noise size of the image and text to the same value corresponds to the distribution of the unconditional image generation. Joint distribution of images and texts. According to this unified perspective, UniDiffuser only needs to make slight modifications to the training algorithm of the original diffusion model to learn all the above distributions at the same time - as shown in the figure below, UniDiffuser adds noise to all modes at the same time instead of a single mode, input The noise magnitude corresponding to all modes, and the predicted noise on all modes.
Taking bimodal mode as an example, the final training objective function is as follows:
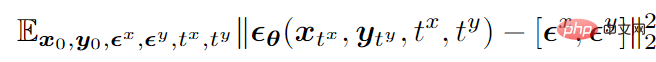

## represents data ,


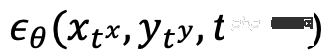
After training, UniDiffuser is able to achieve unconditional, conditional and joint generation by setting the appropriate time for the two modalities to the noise prediction network. For example, setting the time of the text to 0 can achieve text-to-image generation; setting the time of the text to the maximum value can achieve unconditional image generation; setting the time of the image and text to the same value can achieve joint generation of images and texts. The training and sampling algorithms of UniDiffuser are listed below. It can be seen that these algorithms have only made minor changes compared to the original diffusion model and are easy to implement. 
In addition, because UniDiffuser models both conditional distribution and unconditional distribution, UniDiffuser naturally supports classifier-free guidance . Figure 3 below shows the effect of UniDiffuser's conditional generation and joint generation under different guidance scales:

Network Architecture
#In view of the network architecture, the research team proposed to use a transformer-based architecture to parameterize the noise prediction network. Specifically, the research team adopted the recently proposed U-ViT architecture. U-ViT treats all inputs as tokens and adds U-shaped connections between transformer blocks. The research team also adopted the Stable Diffusion strategy to convert data of different modalities into latent space and then model the diffusion model. It is worth noting that the U-ViT architecture also comes from this research team and has been open sourced at https://github.com/baofff/U-ViT.
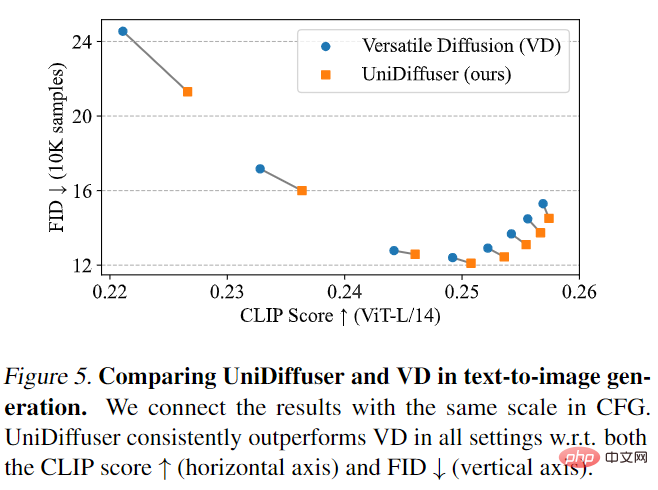
UniDiffuser was first compared with Versatile Diffusion. Versatile Diffusion is a past multi-modal diffusion model based on a multi-task framework. First, UniDiffuser and Versatile Diffusion were compared on text-to-image effects. As shown in Figure 5 below, UniDiffuser is better than Versatile Diffusion in both CLIP Score and FID metrics under different classifier-free guidance scales.
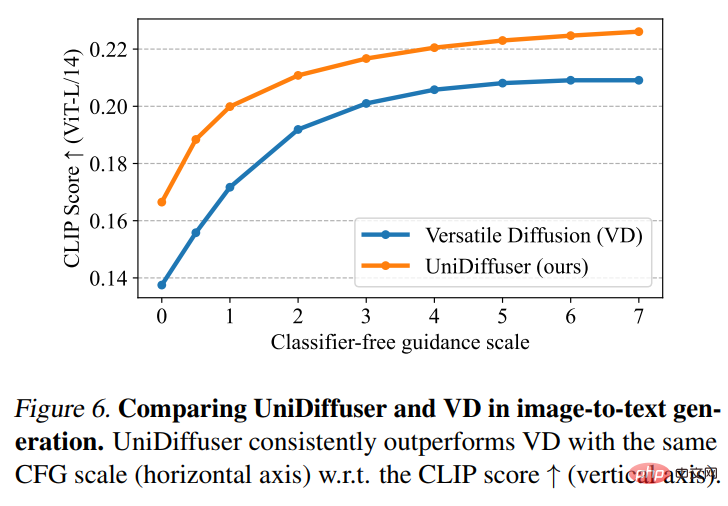
Then UniDiffuser and Versatile Diffusion performed a picture-to-text comparison. As shown in Figure 6 below, UniDiffuser has a better CLIP Score on image-to-text.
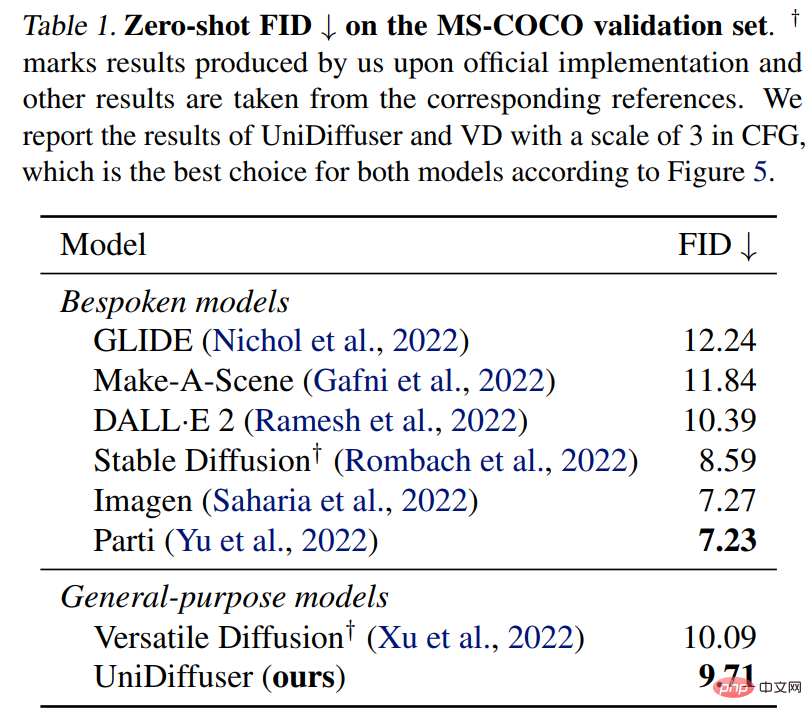
## UniDiffuser also performs a zero-shot FID comparison on MS-COCO against a dedicated text-to-graph model. As shown in Table 1 below, UniDiffuser can achieve comparable results to dedicated text-to-graph models.
The above is the detailed content of Zhu Jun's team open sourced the first large-scale multi-modal diffusion model based on Transformer at Tsinghua University, and it was completely completed after text and image rewriting.. For more information, please follow other related articles on the PHP Chinese website!
 Introduction to the framework used by vscode
Introduction to the framework used by vscode
 what is server
what is server
 script error
script error
 What is the difference between 4g and 5g mobile phones?
What is the difference between 4g and 5g mobile phones?
 Introduction to the function of converting uppercase to lowercase in Python
Introduction to the function of converting uppercase to lowercase in Python
 The function of intermediate relay
The function of intermediate relay
 How to locate someone else's cell phone location
How to locate someone else's cell phone location
 What does full-width and half-width mean?
What does full-width and half-width mean?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



