


In 2012, Hinton et al. proposed dropout in their paper "Improving neural networks by preventing co-adaptation of feature detectors". In the same year, the emergence of AlexNet opened a new era of deep learning. AlexNet uses dropout to significantly reduce overfitting and played a key role in its victory in the ILSVRC 2012 competition. Suffice to say, without dropout, the progress we are currently seeing in deep learning might have been delayed by years.
Since the introduction of dropout, it has been widely used as a regularizer to reduce overfitting in neural networks. Dropout deactivates each neuron with probability p, preventing different features from adapting to each other. After applying dropout, the training loss usually increases while the test error decreases, thus closing the model's generalization gap. The development of deep learning continues to introduce new technologies and architectures, but dropout still exists. It continues to play a role in the latest AI achievements, such as AlphaFold protein prediction, DALL-E 2 image generation, etc., demonstrating versatility and effectiveness.
Despite dropout's continued popularity, its intensity (expressed as drop rate p) has been declining over the years. The initial dropout effort used a default drop rate of 0.5. However, in recent years, lower drop rates are often used, such as 0.1. Related examples can be seen in training BERT and ViT. The main driver of this trend is the explosion of available training data, making overfitting increasingly difficult. Combined with other factors, we may quickly end up with more underfitting than overfitting problems.
Recently in a paper "Dropout Reduces Underfitting", researchers from Meta AI, University of California, Berkeley and other institutions demonstrated how to use dropout to solve the underfitting problem.
Paper address: https://arxiv.org/abs/2303.01500
They first passed the gradient norm We examine the training dynamics of dropout using several interesting observations, and then derive a key empirical finding: during the initial stages of training, dropout reduces the gradient variance of the mini-batch and allows the model to update in a more consistent direction. These directions are also more consistent with the gradient directions across the entire dataset, as shown in Figure 1 below.
As a result, the model can more effectively optimize the training loss on the entire training set without being affected by individual mini-batches. In other words, dropout counteracts stochastic gradient descent (SGD) and prevents over-regularization caused by the randomness of sampled mini-batches early in training.
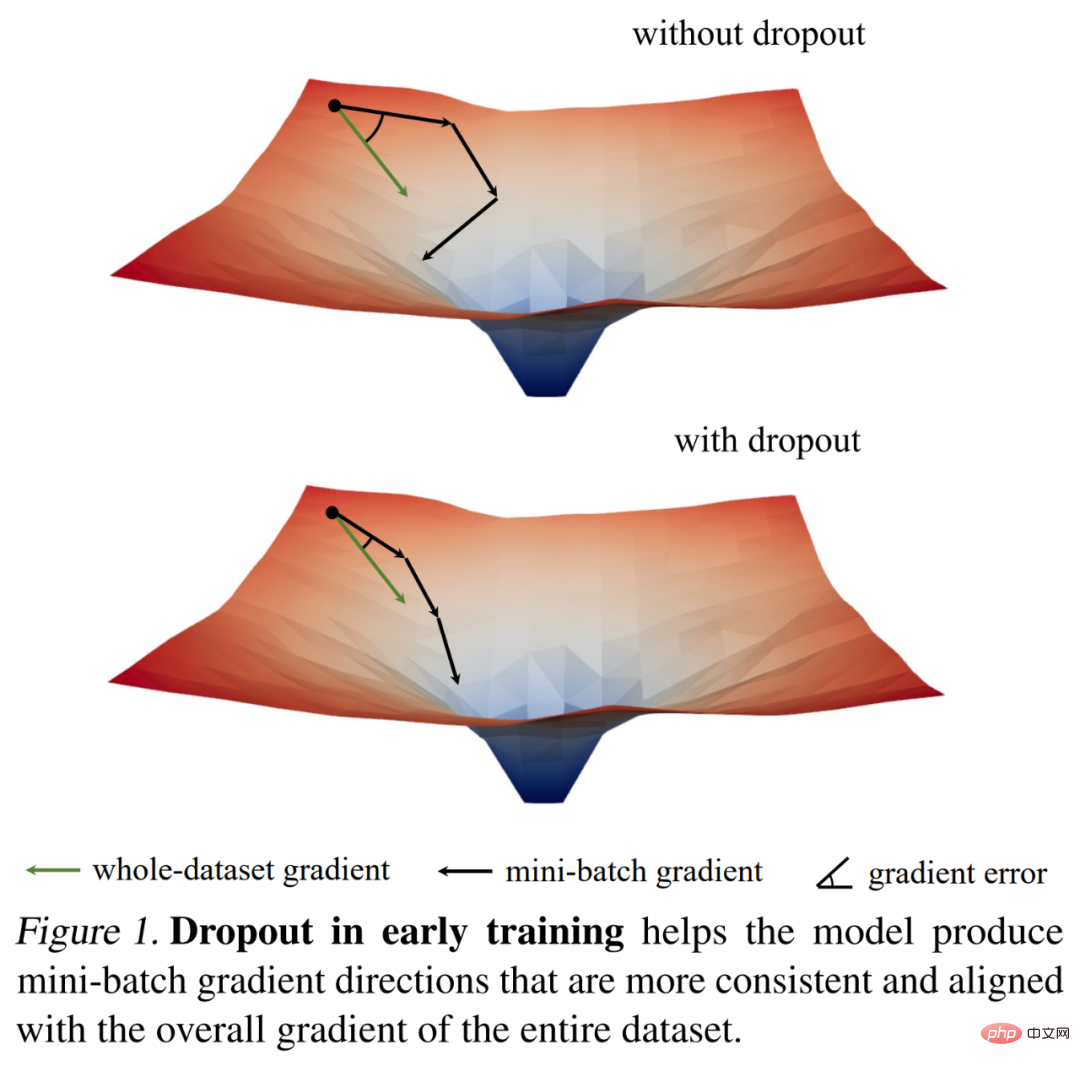
Based on this finding, researchers proposed early dropout (that is, dropout is only used in the early stages of training) to help Underfitted models fit better. Early dropout reduces the final training loss compared to no dropout and standard dropout. In contrast, for models that already use standard dropout, researchers recommend removing dropout in early training epochs to reduce overfitting. They called this method late dropout and showed that it can improve the generalization accuracy of large models. Figure 2 below compares standard dropout, early and late dropout.

Researchers used different models to evaluate early dropout and late dropout on image classification and downstream tasks, and the results show Both consistently produced better results than standard dropout and no dropout. They hope their findings can provide novel insights into dropout and overfitting and inspire further development of neural network regularizers.
Before proposing early dropout and late dropout, this study explored whether dropout can be used as a tool to reduce underfitting. This study performed a detailed analysis of the training dynamics of dropout using its proposed tools and metrics, and compared the training processes of two ViT-T/16 on ImageNet (Deng et al., 2009): one without dropout as a baseline; the other One has a dropout rate of 0.1 throughout training.
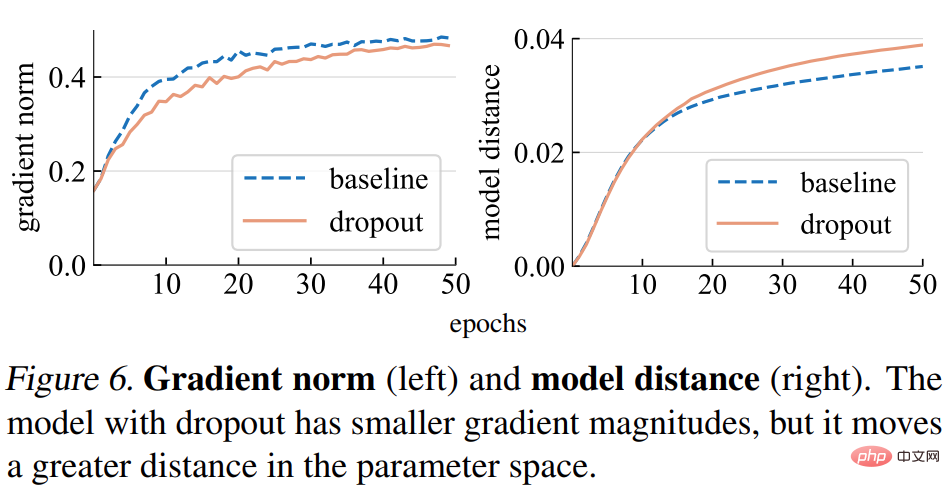
Gradient norm (norm). This study first analyzes the impact of dropout on the strength of gradient g. As shown in Figure 6 (left) below, the dropout model produces gradients with smaller norms, indicating that it takes smaller steps with each gradient update.
Model distance. Since the gradient step size is smaller, we expect the dropout model to move a smaller distance relative to its initial point than the baseline model. As shown in Figure 6 (right) below, the study plots the distance of each model from its random initialization. However, surprisingly, the dropout model actually moved a greater distance than the baseline model, contrary to what the study originally expected based on the gradient norm.
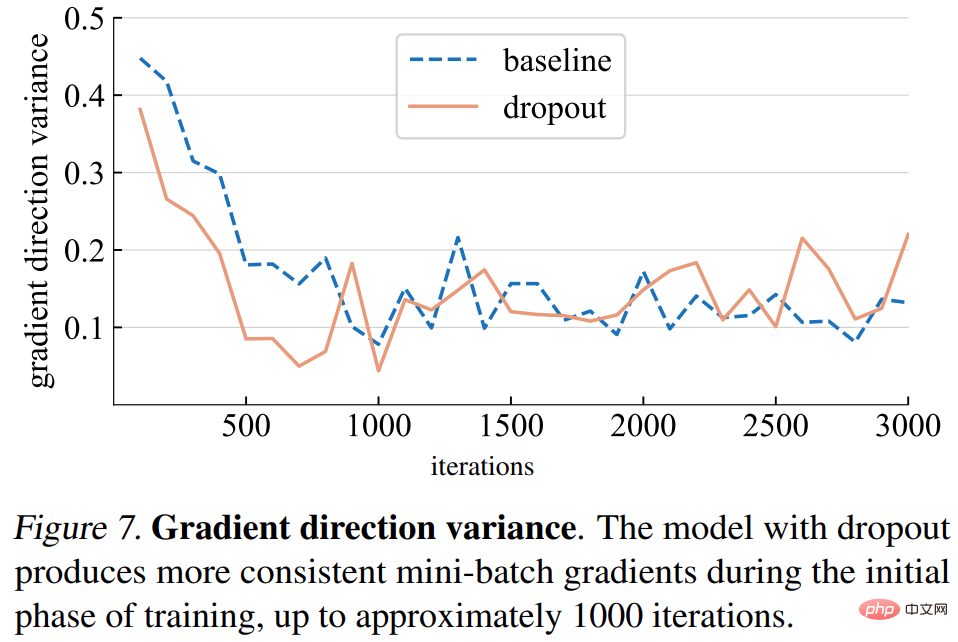
Gradient direction variance. The study first hypothesizes that dropout models produce more consistent gradient directions across mini-batches. The variances shown in Figure 7 below are generally consistent with the assumptions. Until a certain number of iterations (about 1000), the gradient variances of both the dropout model and the baseline model fluctuate at a low level.
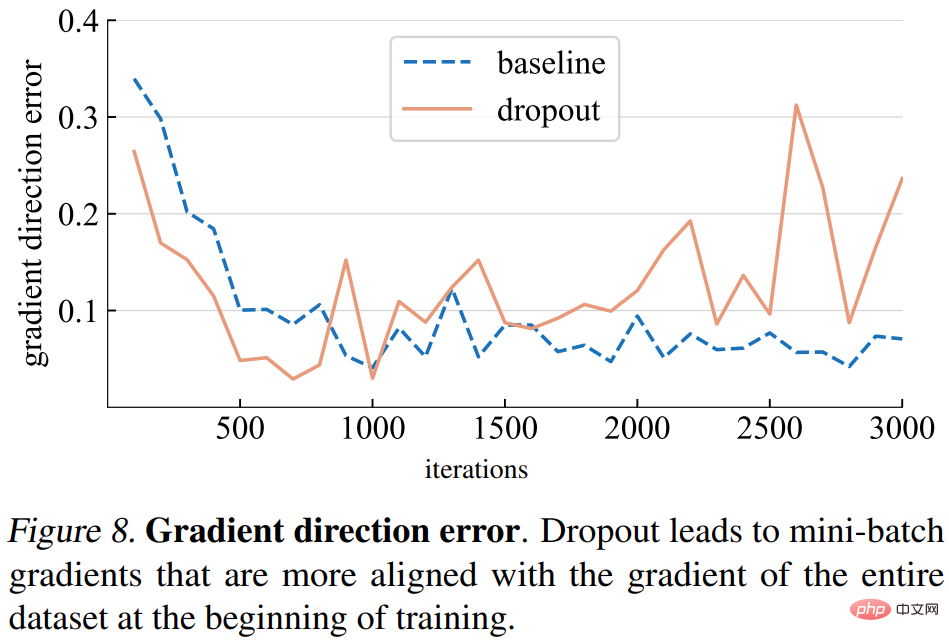
Gradient direction error. However, what should be the correct gradient direction? To fit the training data, the basic goal is to minimize the loss of the entire training set, not just the loss of any one mini-batch. The study computes the gradient of a given model over the entire training set, with dropout set to inference mode to capture the gradient of the full model. The gradient direction error is shown in Figure 8 below.
Based on the above analysis, this study found that using dropout as early as possible can potentially improve the model's ability to fit the training data. Whether a better fit to the training data is needed depends on whether the model is underfitting or overfitting, which can be difficult to define precisely. The study used the following criteria:
#The state of a model depends not only on the model architecture, but also on the dataset used and other training parameters.
Then, the study proposed two methods, early dropout and late dropout
early dropout. By default, underfitted models do not use dropout. To improve its ability to adapt to training data, this study proposes early dropout: using dropout before a certain iteration and then disabling dropout during the rest of the training process. The research experiments show that early dropout reduces the final training loss and improves accuracy.
late dropout. Standard dropout is already included in the training settings for overfitting models. In the early stages of training, dropout may inadvertently cause overfitting, which is undesirable. To reduce overfitting, this study proposes late dropout: dropout is not used before a certain iteration, but is used in the rest of training.
The method proposed in this study is simple in concept and implementation, as shown in Figure 2. The implementation requires two hyperparameters: 1) the number of epochs to wait before turning dropout on or off; 2) the drop rate p, which is similar to the standard dropout rate. This study shows that these two hyperparameters can ensure the robustness of the proposed method.
The researchers conducted an empirical evaluation on the ImageNet-1K classification dataset with 1000 classes and 1.2M training images, and reported top-1 verification accuracy.
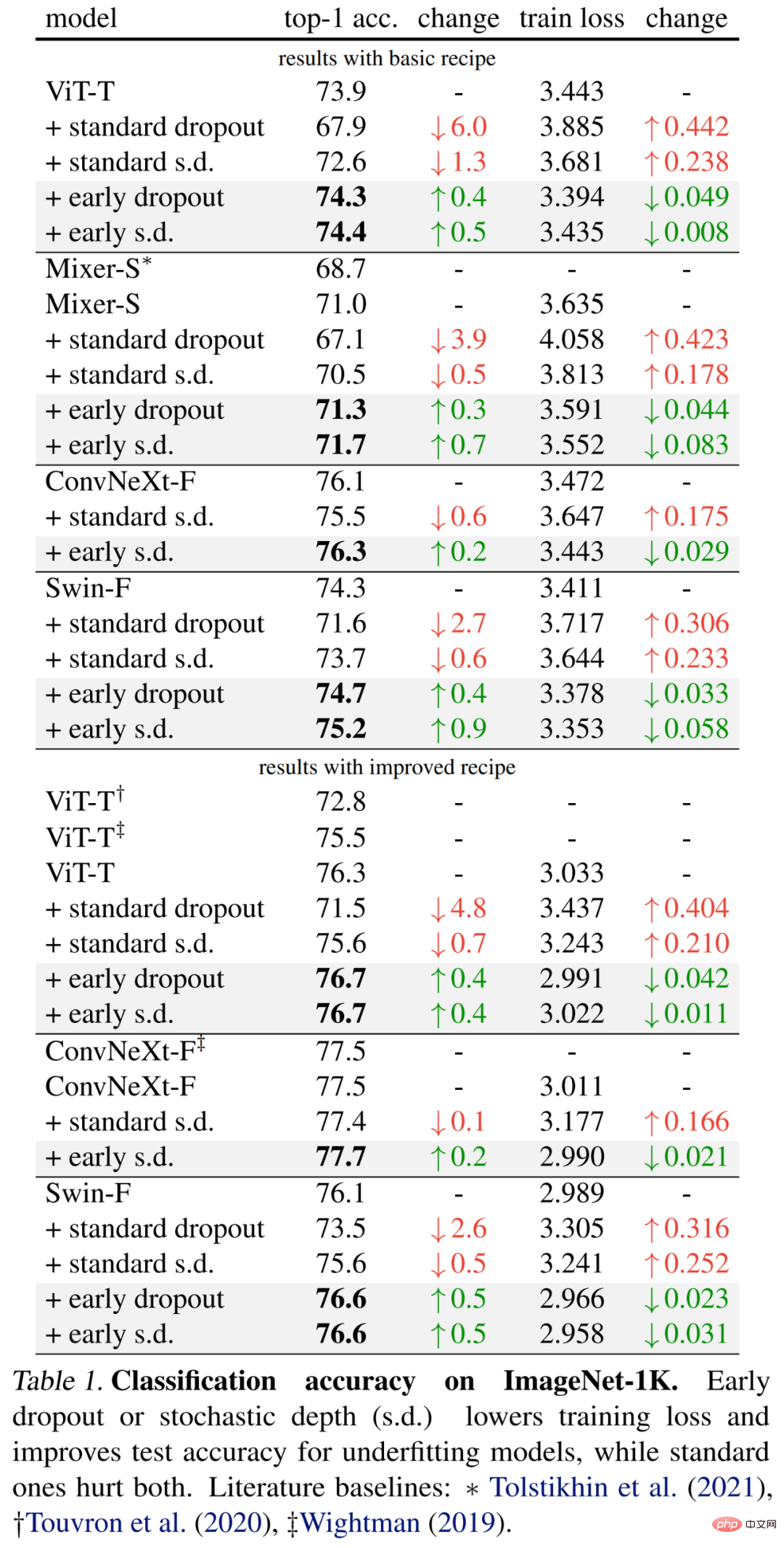
The specific results are first shown in Table 1 (upper part) below. Early dropout continues to improve test accuracy and reduce training loss, indicating that dropout in the early stage helps the model fit better. data. The researchers also show comparisons with standard dropout and stochastic depth (s.d.) using a drop rate of 0.1, both of which have a negative impact on the model.
Additionally, the researchers improved the method for these small models by doubling the training epochs and reducing the mixup and cutmix intensity. The results in Table 1 below (bottom) show significant improvements in baseline accuracy, sometimes significantly exceeding the results of previous work.
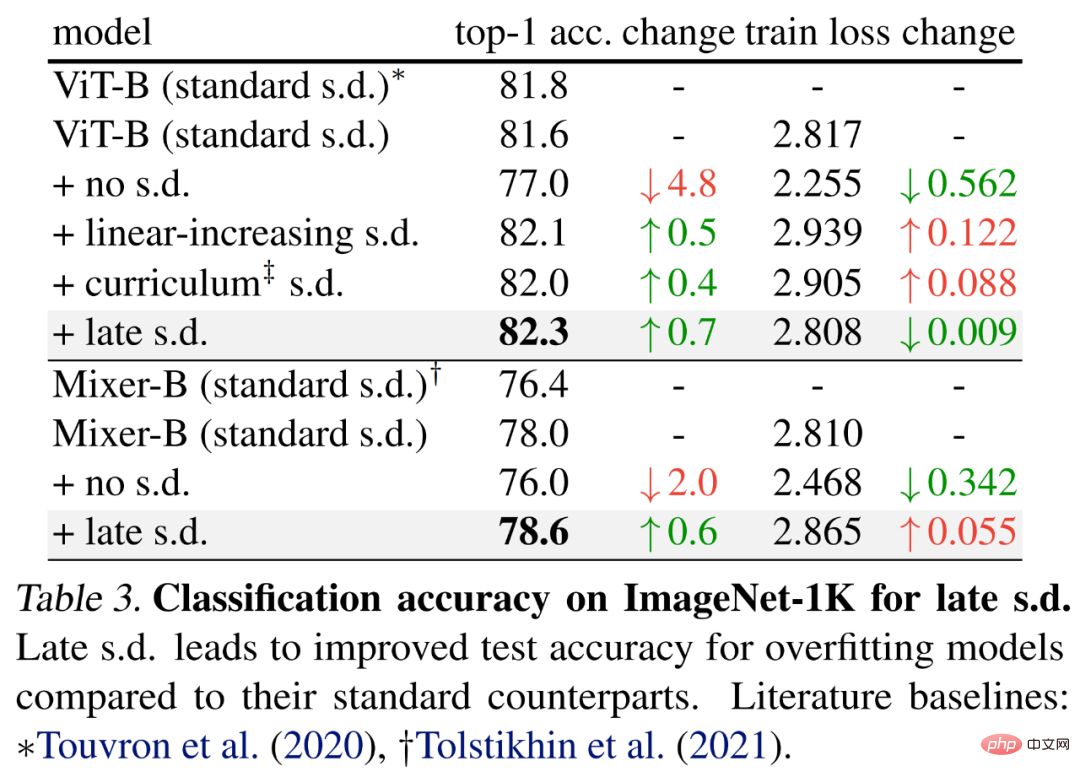
To evaluate late dropout, the researchers chose larger models, namely ViT-B and Mixer-B with 59M and 86M parameters respectively. , using basic training methods.
The results are shown in Table 3 below. Compared with standard s.d., late s.d. improves the test accuracy. This improvement is achieved while maintaining ViT-B or increasing the Mixer-B training loss, indicating that late s.d. effectively reduces overfitting.
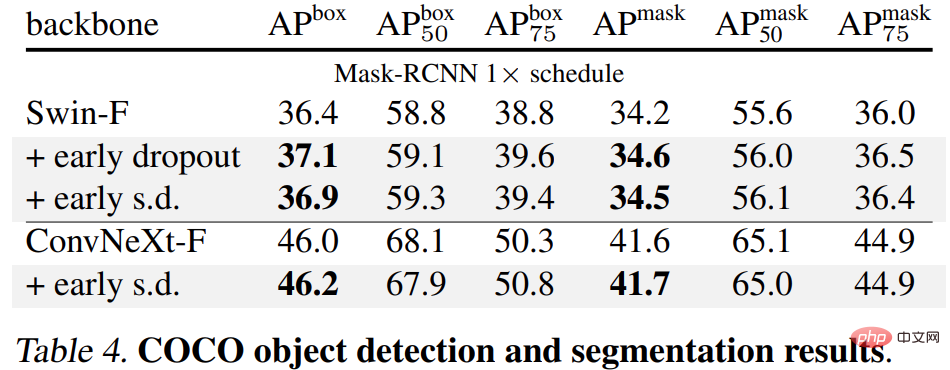
Finally, the researchers fine-tuned the pre-trained ImageNet-1K models on downstream tasks and evaluated them . Downstream tasks include COCO object detection and segmentation, ADE20K semantic segmentation, and downstream classification on five datasets including C-100. The goal is to evaluate the learned representation during the fine-tuning phase without using early dropout or late dropout.
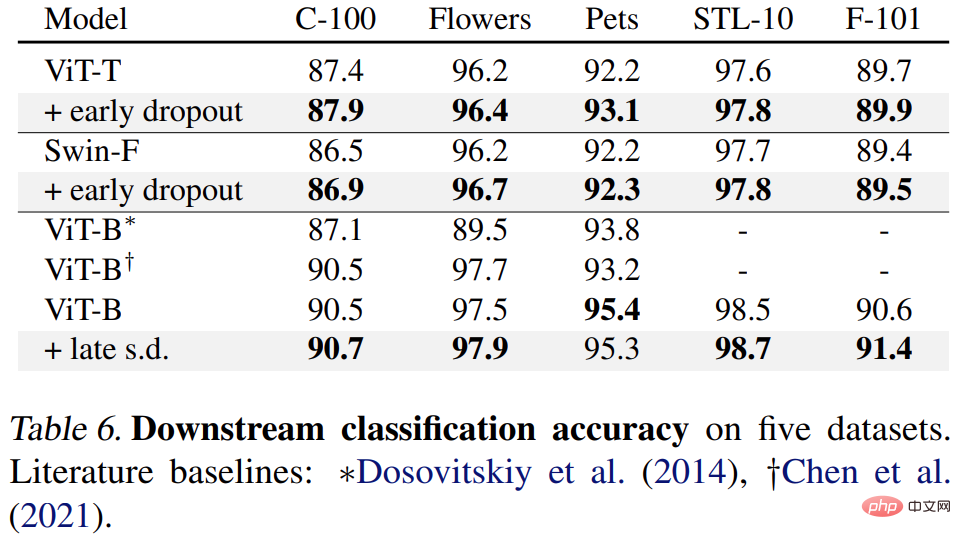
The results are shown in Tables 4, 5 and 6 below. First, when fine-tuned on COCO, the model pre-trained using early dropout or s.d. always maintains an advantage.
Secondly, for the ADE20K semantic segmentation task, the model pre-trained using this method is better than the baseline model.
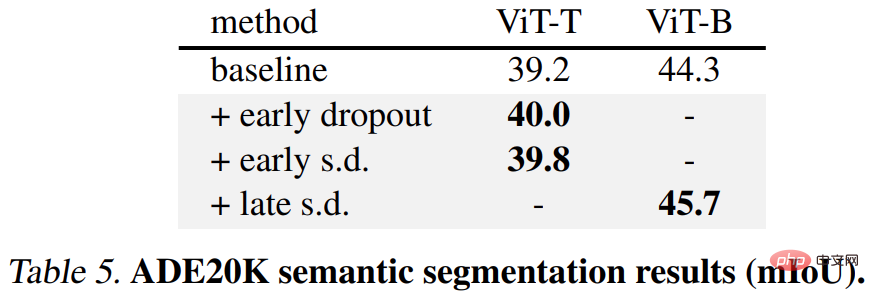
Finally, there are downstream classification tasks. This method improves the generalization performance on most classification tasks.
For more technical details and experimental results, please refer to the original paper.
The above is the detailed content of Improved Dropout can be used to alleviate underfitting problems.. For more information, please follow other related articles on the PHP Chinese website!
 Computer 404 error page
Computer 404 error page
 Solution to the Invalid Partition Table prompt when Windows 10 starts up
Solution to the Invalid Partition Table prompt when Windows 10 starts up
 How to solve the problem of missing ssleay32.dll
How to solve the problem of missing ssleay32.dll
 How to set IP
How to set IP
 How to open state file
How to open state file
 Why is the mobile hard drive so slow to open?
Why is the mobile hard drive so slow to open?
 What are the basic units of C language?
What are the basic units of C language?
 What platform is Kuai Tuan Tuan?
What platform is Kuai Tuan Tuan?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



