


Nowadays, new text-generated image models are released every once in a while, and each of them has very powerful effects. They always amaze everyone. This field has already reached the sky. However, AI systems such as OpenAI's DALL-E 2 or Google's Imagen can only generate two-dimensional images. If text can also be turned into a three-dimensional scene, the visual experience will be doubled. Now, the AI team from Apple has launched the latest neural architecture for 3D scene generation -GAUDI.

It can capture complex and realistic 3D scene distribution, immersive rendering from a moving camera, and also based on text prompts. Create 3D scenes! The model is named after Antoni Gaudi, a famous Spanish architect.

##Paper address: https://arxiv.org/pdf/2207.13751.pdf
Neural rendering combines computer graphics with artificial intelligence and has produced many methods of generating 3D models from 2D images. system. For example, the recently developed 3D MoMa by Nvidia can create a 3D model from less than 100 photos in an hour. Google also relies on Neural Radiation Fields (NeRFs) to combine 2D satellite and Street View images into 3D scenes in Google Maps to achieve immersive views. Google’s HumanNeRF can also render 3D human bodies from videos.
Currently, NeRFs are mainly used as a neural storage medium for 3D models and 3D scenes, which can be rendered from different camera perspectives. NeRFs are also already starting to be used in virtual reality experiences.
So, can NeRFs, with its powerful ability to realistically render images from different camera angles, be used in generative AI? Of course, there are research teams that have tried to generate 3D scenes. For example, Google launched the AI system Dream Fields for the first time last year. It combines NeRF's ability to generate 3D views with OpenAI's CLIP's ability to evaluate image content, and finally achieves the ability to Generate NeRF matching text description.

##Caption: Google Dream Fields
However, Google’s Dream Fields can only generate 3D views of a single object, and there are many difficulties in extending it to completely unconstrained 3D scenes. The biggest difficulty is that there are great restrictions on the position of the camera. For a single object, every possible and reasonable camera position can be mapped to a dome, but in a 3D scene, the position of the camera will be affected by objects and walls, etc. Obstacle limitations. If these factors are not considered during scene generation, it will be difficult to generate a 3D scene.2
camera pose decoder,which separates the camera pose from the 3D geometry and appearance of the scene, can predict the possible position of the camera, and ensure that the output is a valid position of the 3D scene architecture .
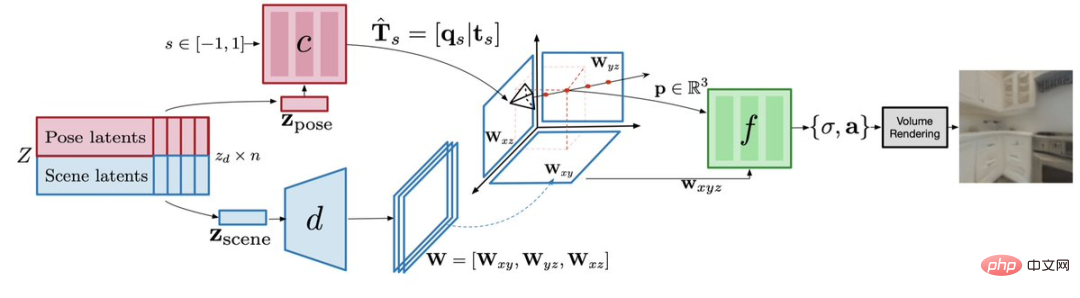
Note: Decoder model architectureScene decoder for scenariosYou can predict the representation of a three-dimensional plane, which is a 3D canvas.
Then,Radiation Field Decoderwill use the volume rendering equation on this canvas to draw subsequent images.
GAUDI’s 3D generation consists of two stages:
One is the optimization of latent and network parameters: learning latent representations that encode the 3D radiation fields and corresponding camera poses of thousands of trajectories. Unlike for a single object, the effective camera pose varies with the scene, so it is necessary to encode the valid camera pose for each scene.
The second is to use the diffusion model to learn a generative model on the latent representation, so that it can model well in both conditional and unconditional reasoning tasks. The former generates 3D scenes based on text or image prompts, while the latter generates 3D scenes based on camera trajectories.
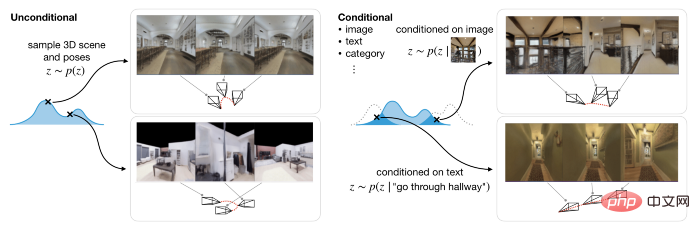
With 3D indoor scenes, GAUDI can generate new camera movements. As in some of the examples below, the text description contains information about the scene and the navigation path. Here the research team adopted a pre-trained RoBERTa-based text encoder and used its intermediate representation to adjust the diffusion model. The generated effect is as follows: Text prompt: Enter the kitchen

Text prompt: Go upstairs

Text prompt: Go through the corridor

In addition, using pre-trained ResNet-18 as the image encoder, GAUDI is able to sample the radiation field of a given image observed from random viewpoints, thereby extracting from the image cues Create 3D scenes. Image prompt:

Generate 3D scene:

Image Tips:

Generate 3D scene:

Researcher Experiments on four different datasets, including the indoor scanning dataset ARKitScences, show that GAUDI can reconstruct learned views and match the quality of existing methods. Even in the huge task of producing 3D scenes with hundreds of thousands of images for thousands of indoor scenes, GAUDI did not suffer from mode collapse or orientation problems.
The emergence of GAUDI will not only have an impact on many computer vision tasks, but its 3D scene generation capabilities will also be beneficial to model-based reinforcement learning and planning, SLAM and 3D content. Production and other research fields.
At present, the quality of the video generated by GAUDI is not high, and many artifacts can be seen. However, this system may be a good start and foundation for Apple's ongoing AI system for rendering 3D objects and scenes. It is said that GAUDI will also be applied to Apple's XR headsets for generating digital positions. You can look forward to it~
The above is the detailed content of Apple develops 'AI architect' GAUDI: generates ultra-realistic 3D scenes based on text!. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



