



News on April 20th, artificial intelligence chatbots have become increasingly popular in the past four months, and they are able to complete a variety of tasks, such as writing complex academic papers and conducting research. Intense dialogue and amazing abilities.
Chatbots don’t think like humans, they don’t even know what they’re talking about. They can mimic human speech because the artificial intelligence that drives them has absorbed vast amounts of text, much of it scraped from the internet.
These texts are the AI’s primary source of information about the world during its construction, and they can have a profound impact on how the AI responds. If artificial intelligence achieves excellent results on the judicial examination, it may be because its training data contains thousands of LSAT (Law School Admission Test, American Law School Admission Test) information.
Tech companies are always secretive about what information they provide to artificial intelligence. So The Washington Post set out to analyze one of these important data sets, revealing the types of proprietary, personal and often offensive websites used to train AI.
To explore the internal makeup of artificial intelligence training data, the Washington Post teamed up with researchers from the Allen Institute for Artificial Intelligence to analyze Google’s C4 data set. This dataset is a massive snapshot of more than 15 million websites, the content of which is used to train many high-profile English-language AIs, such as Google’s T5 and Facebook’s LLaMA. OpenAI did not disclose what kind of data set they used to train the model that supports the chatbot ChatGPT.
For the survey, researchers used data from web analytics company Similarweb to classify websites. About a third of these sites could not be classified and were excluded, mainly because they no longer exist on the Internet. The researchers then ranked the remaining 10 million websites based on the number of "tokens" that appeared on each website in the data set. A token is a small piece of text processing information, usually a word or phrase, used to train AI models.
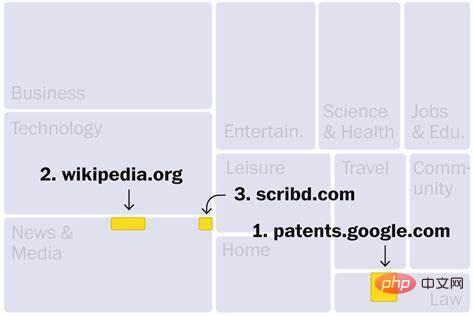
Websites in the C4 dataset are mainly from industries such as news, entertainment, software development, medical and content creation. This could explain why these fields may be threatened by a new wave of artificial intelligence. The top three websites are: the first is Google Patent Search, which contains patent texts published around the world; the second is Wikipedia; and the third is Scribd, a digital library that only accepts paid subscriptions. In addition, other high-ranking websites include the pirated e-book marketplace Library (No. 190), which was shut down by the U.S. Department of Justice for illegal activities. In addition, there are at least 27 websites in the data set that have been identified by the US government as markets for pirated and counterfeit products.
Also featured are some of the top sites, such as wowhead (No. 181), a forum for World of Warcraft players, and a website founded by Arianna Huffington to help combat burnout. Website ThriveGlobal (No. 175). Additionally, there are at least 10 websites selling dumpsters, including dumpsteroid (No. 183), but it appears to be no longer accessible.
Although most websites are safe, some have serious privacy issues. For example, two websites ranked in the top 100 list privately hosted copies of state voter registration databases. While voter data is public, these models may use this personal information in unknown ways.
Industrial and commercial websites occupy the largest category (accounting for 16% of classified tokens). Topping the list is The Motley Fool (No. 13), which provides investment advice. Next is Kickstarter (No. 25), a website that allows users to crowdfund creative projects. Patreon, which ranks lower at No. 2,398, helps creators collect monthly fees from subscribers for exclusive content.
However, Kickstarter and Patreon may allow artificial intelligence to access artists’ ideas and marketing copy, raising concerns that AI may copy these works when providing suggestions to users. Artists, who currently do not receive any compensation when their work is included in AI training data, have filed infringement claims against text-to-image generators Stable Diffusion, MidJourney and DeviantArt.
According to this Washington Post analysis, more legal challenges may be coming: There are more than 200 million occurrences of the copyright symbol (indicating works registered as intellectual property) in the C4 data set.
Technical websites are the second largest category, accounting for 15% of classified tokens. This includes many platforms that help people build websites, such as Google Sites (No. 85), which has pages covering everything from a judo club in Reading, England, to a kindergarten in New Jersey.
The C4 data set also contains more than 500,000 personal blogs, accounting for 3.8% of classified content. Publishing platform Medium ranks 46th and is the fifth largest technology website, with tens of thousands of blogs under its domain name. In addition, there are blogs written on platforms such as WordPress, Tumblr, Blogpot, and Live Journal.
These blogs range from the professional to the personal, such as a blog called "Grumpy Rumblings" co-authored by two anonymous academics, one of whom recently wrote about how their partner lost his job. How it affects a couple's taxes. In addition, there are some top blogs focusing on live-action role-playing games in the C4 dataset.
The content of social networks such as Facebook and Twitter (which are considered the core of the modern web) is blocked from crawling, which means that most data sets used to train artificial intelligence cannot access them. Tech giants like Facebook and Google are sitting on vast amounts of conversational data, but they don’t yet know how to use personal user information to train artificial intelligence models for internal use or to sell as products.
News and media sites ranked third across all categories, and half of the top ten sites were news outlets: The New York Times ranked fourth, the Los Angeles Times ranked sixth, and the Guardian Newspaper website ranked seventh, Forbes website ranked eighth, Huffington Post website ranked ninth, and Washington Post website ranked 11th. Like artists and creators, several news organizations have criticized tech companies for using their content without authorization or compensation.
At the same time, the "Washington Post" also found that several media ranked lower in NewsGuard's independent credibility rating: such as Russia's RT (65th), the far-right news website Breitbart ( No. 159) and anti-immigrant website vdare (No. 993), which is linked to white supremacy.
Chatbots have been proven to share misinformation. Untrustworthy training data can lead them to spread bias and promote misinformation without users being able to trace them to their original source.
Community websites account for about 5% of classified content, mainly religious websites.
Like most companies, Google filters and screens data before feeding it to AI. In addition to removing meaningless and repetitive text, the company also uses an open-source "bad word list" that includes 402 English terms and an emoji. Companies often use high-quality data sets to fine-tune models to block content users don’t want to see.
While such lists are intended to limit models being trained on racial slurs and inappropriate content, a lot of things make it past the filter. The Washington Post found hundreds of pornographic websites and more than 72,000 examples of "Nazi" on the banned word list.
Meanwhile, The Washington Post found that the filters failed to remove some disturbing content, including white supremacist websites, anti-trans websites and sites known for organizing harassment campaigns against individuals. The anonymous message board 4chan. The study also uncovered websites promoting conspiracy theories.
Web scraping may sound like copying the entire Internet, but it's actually just collecting snapshots, a sample of web pages at a specific moment in time. The C4 dataset was originally created by the non-profit organization CommonCrawl for web content crawling in April 2019 and is a popular resource for artificial intelligence model training. CommonCrawl said the organization tried to prioritize the most important and reputable websites but made no attempt to avoid licensed or copyright-protected content.
The Washington Post believes that it is critical to present the complete content of data in artificial intelligence models that are expected to manage many aspects of people’s modern lives. However, many websites in this dataset contain highly offensive language, and even if the model is trained to mask these words, objectionable content may still be present.
Experts say that although the C4 data set is large, large language models may use even larger data sets. For example, OpenAI released GPT-3 training data in 2020, which has 40 times the amount of web scraped data in C4. GPT-3’s training data includes all of the English Wikipedia, a collection of free novels by unpublished authors frequently used by large tech companies, and a compilation of linked text highly rated by Reddit users.
Experts say many companies don’t even log the contents of their training data (even internally) for fear of finding out about personally identifiable information, copyrighted material and other data that has been stolen without consent. . As companies highlight the challenge of explaining how chatbots make decisions, this is an area where executives need to give transparent answers.
The above is the detailed content of US media reveals large model training data set: some content is a bit 'dirty'. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 Talent assessment tools
Talent assessment tools
 How to restore Bluetooth headset to binaural mode
How to restore Bluetooth headset to binaural mode
 How to remove Firefox security lock
How to remove Firefox security lock
 What is the difference between eclipse and idea?
What is the difference between eclipse and idea?
 How much is Dimensity 8200 equal to Snapdragon?
How much is Dimensity 8200 equal to Snapdragon?
 How to turn on Word safe mode
How to turn on Word safe mode








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



