


Running large-scale models on consumer GPUs is an ongoing challenge for the machine learning community.
The size of language models has been getting larger. PaLM has 540B parameters, OPT, GPT-3 and BLOOM have about 176B parameters. The model is still moving in a larger direction. develop.

# These models are difficult to run on easily accessible devices. For example, BLOOM-176B needs to run on eight 80GB A100 GPUs (~$15,000 each) to complete the inference task, while fine-tuning BLOOM-176B requires 72 such GPUs. Larger models such as PaLM will require more resources.
We need to find ways to reduce the resource requirements of these models while maintaining model performance. Various techniques have been developed in the field that attempt to reduce model size, such as quantization and distillation.
BLOOM was created last year by more than 1,000 volunteer researchers in a project called "BigScience", which is operated by the artificial intelligence startup Hugging Face with funds from the French government. On July 12 this year The BLOOM model is officially released.
Using Int8 inference will significantly reduce the memory footprint of the model, but will not reduce the prediction performance of the model. Based on this, researchers from the University of Washington, Meta AI Research Institute (formerly Facebook AI Research) and other institutions jointly conducted a study with HuggingFace, trying to make the trained BLOOM-176B run on fewer GPUs, and the proposed method Fully integrated into HuggingFace Transformers.

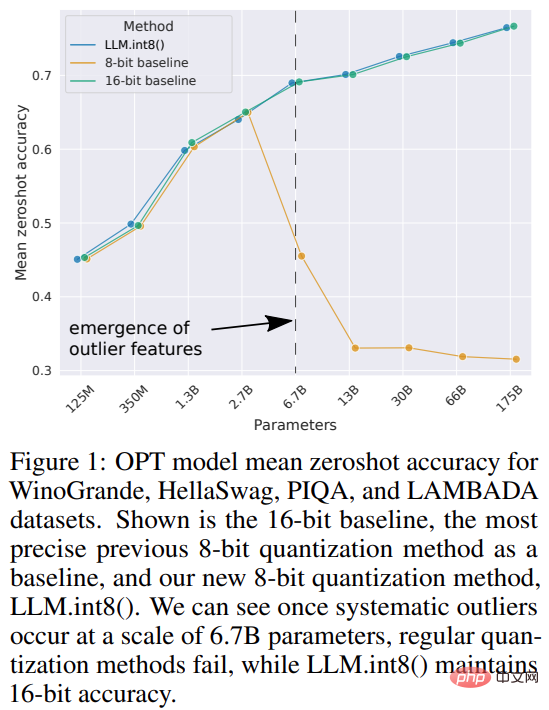
This research proposes the first billion-scale Int8 quantization process for transformer, which does not affect the model's Reasoning performance. It can load a 175B parameter transformer with 16-bit or 32-bit weights and convert feedforward and attention projection layers to 8-bit. It cuts the memory required for inference in half while maintaining full precision performance.
The study named the combination of vector quantization and mixed-precision decomposition LLM.int8(). Experiments show that by using LLM.int8(), it is possible to perform inference with an LLM of up to 175B parameters on a consumer GPU without performance degradation. This approach not only sheds new light on the impact of outliers on model performance, but also makes it possible for the first time to use very large models, such as OPT-175B/BLOOM, on a single server with consumer-grade GPUs.
The size of the machine learning model depends on the number of parameters and their precision, usually float32, float16 or bfloat16 one. float32 (FP32) stands for standardized IEEE 32-bit floating-point representation, and a wide range of floating-point numbers can be represented using this data type. FP32 reserves 8 bits for the "exponent", 23 bits for the "mantissa", and 1 bit for the sign of the number. Also, most hardware supports FP32 operations and instructions.
And float16 (FP16) reserves 5 bits for the exponent and 10 bits for the mantissa. This leaves the representable range of FP16 numbers much lower than FP32, exposing it to the risk of overflow (trying to represent a very large number) and underflow (representing a very small number).
When overflow occurs, you will get a NaN (not a number) result, and if you perform sequential calculations like in neural networks, a lot of work will crash. bfloat16 (BF16) avoids this problem. BF16 reserves 8 bits for the exponent and 7 bits for the decimal, meaning BF16 can retain the same dynamic range as FP32.
Ideally, training and inference should be done in FP32, but it is slower than FP16/BF16, so use mixed precision to improve training speed. But in practice, half-precision weights also provide similar quality to FP32 during inference. This means we can use half the precision weights and use half the GPU to achieve the same results.
But what if we could use different data types to store these weights with less memory? A method called quantization has been widely used in deep learning.
This study first used 2-byte BF16/FP16 half precision instead of 4-byte FP32 precision in the experiment, achieving almost the same inference results. In this way, the model is reduced by half. But if you reduce this number further, the accuracy will decrease, and the quality of inference will drop sharply.
To make up for this, this study introduces 8bit quantification. This method uses a quarter of the precision and therefore requires only a quarter of the model size, but this is not achieved by removing the other half of the bits.
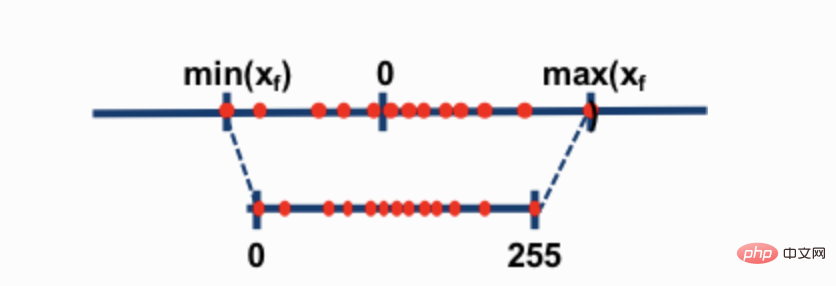
The two most common 8-bit quantization techniques are zero-point quantization and absmax (absolute maximum) quantization. Both methods map floating point values to more compact int8 (1 byte) values.
For example, in zero-point quantization, if the data range is -1.0-1.0, and quantized to -127-127, the expansion factor is 127. At this expansion factor, a value of 0.3, for example, would be expanded to 0.3*127 = 38.1. Quantization usually involves rounding, which gives us 38. If we reverse this, we get 38/127=0.2992 - a quantization error of 0.008 in this example. These seemingly small errors tend to accumulate and grow as they propagate through the model layers and cause performance degradation.
While these techniques are capable of quantifying deep learning models, they often result in reduced model accuracy. But LLM.int8(), integrated into the Hugging Face Transformers and Accelerate libraries, is the first technique that does not degrade performance even for large models with 176B parameters (like BLOOM).
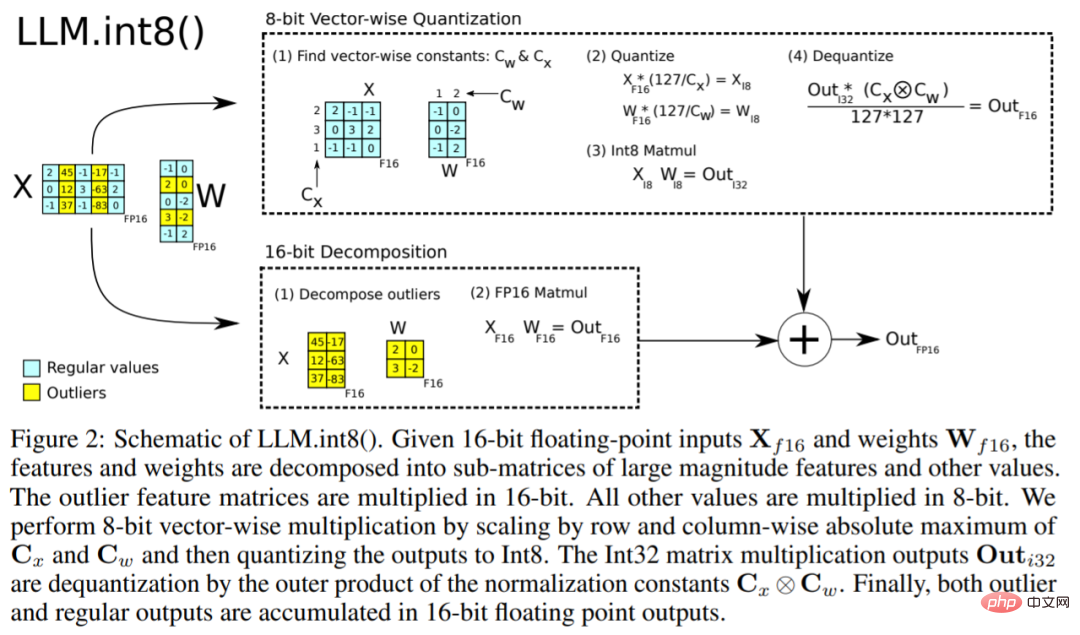
The LLM.int8() algorithm can be explained like this. In essence, LLM.int8() attempts to complete matrix multiplication calculations in three steps:
These steps can be summarized in the animation below:

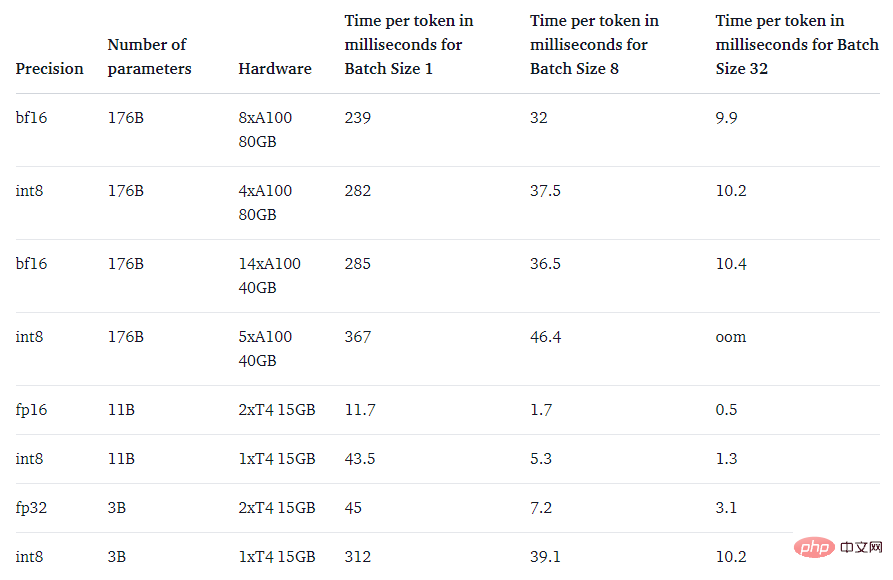
Finally, the study Also focused on a question: Is it faster than the native model?
The main purpose of the LLM.int8() method is to make large models more accessible without reducing performance. However, if it's very slow, it's not very useful. The research team benchmarked the generation speed of multiple models and found that BLOOM-176B with LLM.int8() was approximately 15% to 23% slower than the fp16 version - which is completely acceptable. And smaller models like the T5-3B and T5-11B have even greater decelerations. The research team is working to improve the speed of these small models.
The above is the detailed content of Consumer-grade GPU successfully runs a large model with 176 billion parameters. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



