


Table of Contents
Paper 1: Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models
Abstract:Recently, researchers from the University of Munich, NVIDIA and other institutions have used The latent diffusion model (LDM) enables high-resolution long video synthesis.
In the paper, the researchers applied the video model to real-world problems and generated high-resolution long videos. They focus on two related video generation problems, one is video synthesis of high-resolution real-world driving data, which has great potential as a simulation engine in autonomous driving environments, and the other is text-guided video generation for creative content generation.
To this end, researchers proposed the Video Latent Diffusion Model (Video LDM) and extended LDM to a computationally intensive task - high-resolution video generation. In contrast to previous video generation DM work, they pre-trained Video LDM only on images (or used available pre-trained image LDM), allowing the utilization of large-scale image datasets.
Then the temporal dimension is introduced into the latent space DM and the pre-trained spatial layer is fixed while only training these temporal layers on the encoded image sequence (i.e. video), thereby converting the LDM image generator Convert to video generator (picture below left). Finally, the decoder of the LDM is fine-tuned in a similar manner to achieve temporal consistency in pixel space (right image below).
Recommendation: Video version Stable Diffusion: NVIDIA achieves the highest 1280×2048, the longest 4.7 seconds.
Paper 2: MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models
##Abstract: A team from King Abdullah University of Science and Technology (KAUST) developed a GPT-4 Similar product - MiniGPT-4. MiniGPT-4 demonstrates many capabilities similar to GPT-4, such as generating detailed image descriptions and creating websites from handwritten drafts. Additionally, the authors observed other emerging capabilities of MiniGPT-4, including creating stories and poems based on given images, providing solutions to problems shown in images, teaching users how to cook based on food photos, etc.
MiniGPT-4 uses a projection layer to align a frozen visual encoder and a frozen LLM (Vicuna). MiniGPT-4 consists of a pre-trained ViT and Q-Former visual encoder, a separate linear projection layer, and an advanced Vicuna large language model. MiniGPT-4 only requires training linear layers to align visual features with Vicuna.
Example demonstration: Creating a website from a sketch.

Recommendation: Nearly 10,000 stars in 3 days, experience GPT-4 image recognition ability without any difference, see MiniGPT-4 Chat with pictures and build a website with sketches.
Paper 3: OpenAssistant Conversations - Democratizing Large Language Model Alignment
Abstract: To democratize large-scale alignment research, researchers from institutions such as LAION AI (which provides the open source data used by Stable diffusion.) A large amount of text-based input and feedback is collected to create OpenAssistant Conversations, a diverse and unique dataset specifically designed to train language models or other AI applications.
This dataset is a human-generated, human-annotated assistant-style conversation corpus covering a wide range of topics and writing styles, consisting of 161,443 messages distributed across 66,497 conversation trees , in 35 different languages. The corpus is the product of a global crowdsourcing effort involving more than 13,500 volunteers. It is an invaluable tool for any developer looking to create SOTA instruction models. And the entire dataset is freely accessible to anyone.
In addition, to prove the effectiveness of the OpenAssistant Conversations data set, the study also proposes a chat-based assistant OpenAssistant, which can understand tasks, interact with third-party systems, and dynamically retrieve information . This is arguably the first fully open source large-scale instruction fine-tuning model trained on human data.
The results show that OpenAssistant’s responses are more popular than GPT-3.5-turbo (ChatGPT).
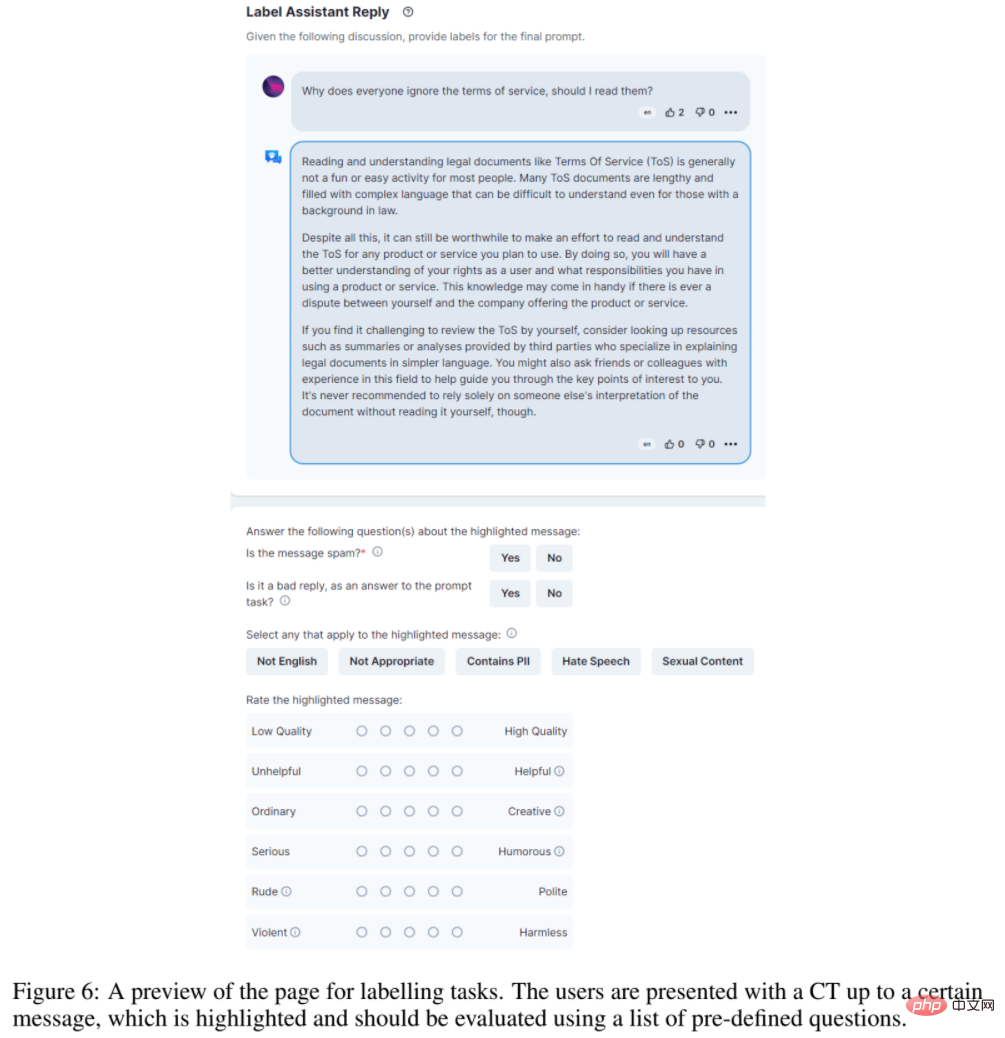
OpenAssistant Conversations data is collected using the web-app interface, including 5 steps: prompt, mark prompt, add reply message For prompters or assistants, mark responses, and rank assistant responses.
Recommended: ChatGPT The world's largest open source replacement.
##Paper 4: Inpaint Anything: Segment Anything Meets Image Inpainting
IA has three main functions: (i) Remove Anything: Users only need to click on the object they want to remove, and IA will remove the object without leaving a trace, achieving efficient "magic" Eliminate"; (ii) Fill Anything: At the same time, the user can further tell IA what they want to fill in the object through text prompt (Text Prompt), and IA will then drive the embedded AIGC (AI-Generated Content) Models (such as Stable Diffusion [2]) generate corresponding content-filled objects to achieve "content creation" at will; (iii) Replace Anything: The user can also click to select the objects that need to be retained and tell IA using text prompts If you want to replace the background of an object with something, you can replace the background of the object with the specified content to achieve a vivid "environment transformation". The overall framework of IA is shown in the figure below: Recommendation: No need for fine marking, click on the object to remove the object, Content filling and scene replacement. Paper 5: Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP Abstract: Meta and UTAustin jointly proposed a new open language style model (open-vocabulary segmentation, OVSeg), which allows the Segment Anything model to know the categories to be separated. From an effect point of view, OVSeg can be combined with Segment Anything to complete fine-grained open language segmentation. For example, in Figure 1 below, identify the types of flowers: sunflowers, white roses, chrysanthemums, carnations, green dianthus. Recommendation: Meta/UTAustin proposes a new open class segmentation model. Paper 6: Plan4MC: Skill Reinforcement Learning and Planning for Open-World Minecraft Tasks Abstract: The team from Peking University and Beijing Zhiyuan Artificial Intelligence Research Institute proposed Plan4MC, a method to efficiently solve Minecraft multitasking without expert data. The author combines reinforcement learning and planning methods to decompose solving complex tasks into two parts: learning basic skills and skill planning. The authors use intrinsic reward reinforcement learning methods to train three types of fine-grained basic skills. The agent uses a large language model to build a skill relationship graph, and obtains task planning through searching on the graph. In the experimental part, Plan4MC can currently complete 24 complex and diverse tasks, and the success rate has been greatly improved compared to all baseline methods. Recommendation: Use ChatGPT and reinforcement learning to play "Minecraft", Plan4MC overcomes 24 complex tasks. Paper 7: T2Ranking: A large-scale Chinese Benchmark for Passage Ranking ##Abstract:Paragraph sorting is a very important and challenging topic in the field of information retrieval, and has attracted much attention from academia and industry. wide attention from the industry. The effectiveness of the paragraph ranking model can improve search engine user satisfaction and help information retrieval-related applications such as question and answer systems, reading comprehension, etc. In this context, some benchmark datasets such as MS-MARCO, DuReader_retrieval, etc. were constructed to support related research work on paragraph sorting. However, most of the commonly used data sets focus on English scenes. For Chinese scenes, existing data sets have limitations in data scale, fine-grained user annotation, and solution to the problem of false negative examples. Against this background, this study constructed a new Chinese paragraph ranking benchmark data set based on real search logs: T2Ranking.
Recommendation: 300,000 real queries, 2 million Internet paragraphs, Chinese paragraph ranking benchmark data set released. ArXiv Weekly Radiostation
10 papers this week The selected NLP papers are: 2. Exploring the Trade-Offs: Unified Large Language Models vs Local Fine-Tuned Models for Highly-Specific Radiology NLI Task. (from Wei Liu, Dinggang Shen) 4. Stochastic Parrots Looking for Stochastic Parrots : LLMs are Easy to Fine-Tune and Hard to Detect with other LLMs. (from Rachid Guerraoui) 5. Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models. ( from Kai-Wei Chang, Song-Chun Zhu, Jianfeng Gao) 6. MER 2023: Multi-label Learning, Modality Robustness, and Semi-Supervised Learning. (from Meng Wang, Erik Cambria, Guoying Zhao) 7. GeneGPT: Teaching Large Language Models to Use NCBI Web APIs. (from Zhiyong Lu) 8 . A Survey on Biomedical Text Summarization with Pre-trained Language Model. (from Sophia Ananiadou) 9. Emotion fusion for mental illness detection from social media: A survey. (from Sophia Ananiadou) ) 10. Language Models Enable Simple Systems for Generating Structured Views of Heterogeneous Data Lakes. (from Christopher Ré)
this The 10 CV selected papers of the week are: 2. Align-DETR: Improving DETR with Simple IoU-aware BCE loss. (from Xiangyu Zhang) 3. Exploring Incompatible Knowledge Transfer in Few-shot Image Generation . (from Shuicheng Yan) 4. Learning Situation Hyper-Graphs for Video Question Answering. (from Mubarak Shah) 5. Video Generation Beyond a Single Clip. (from Ming-Hsuan Yang) 6. A Data-Centric Solution to NonHomogeneous Dehazing via Vision Transformer. (from Huan Liu) 7. Neuromorphic Optical Flow and Real-time Implementation with Event Cameras. (from Luca Benini, Davide Scaramuzza) 8. Language Guided Local Infiltration for Interactive Image Retrieval. (from Lei Zhang) 9. LipsFormer: Introducing Lipschitz Continuity to Vision Transformers. (from Lei Zhang) 10. UVA: Towards Unified Volumetric Avatar for View Synthesis, Pose rendering, Geometry and Texture Editing. (from Dacheng Tao) 本周 10 篇 ML 精选论文是: 1. Bridging RL Theory and Practice with the Effective Horizon. (from Stuart Russell) 2. Towards transparent and robust data-driven wind turbine power curve models. (from Klaus-Robert Müller) 3. Open-World Continual Learning: Unifying Novelty Detection and Continual Learning. (from Bing Liu) 4. Learning in latent spaces improves the predictive accuracy of deep neural operators. (from George Em Karniadakis) 5. Decouple Graph Neural Networks: Train Multiple Simple GNNs Simultaneously Instead of One. (from Xuelong Li) 6. Generalization and Estimation Error Bounds for Model-based Neural Networks. (from Yonina C. Eldar) 7. RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment. (from Tong Zhang) 8. Adaptive Consensus Optimization Method for GANs. (from Pawan Kumar) 9. Angle based dynamic learning rate for gradient descent. (from Pawan Kumar) 10. AGNN: Alternating Graph-Regularized Neural Networks to Alleviate Over-Smoothing. (from Wenzhong Guo)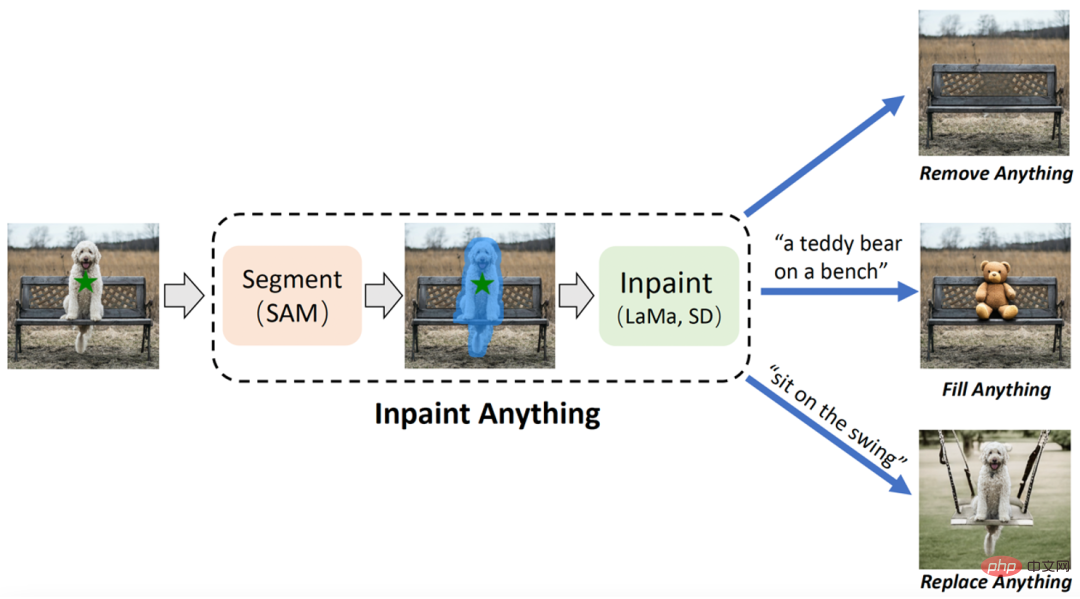


The above is the detailed content of MiniGPT-4 looks at pictures, chats, and can also sketch and build websites; the video version of Stable Diffusion is here. For more information, please follow other related articles on the PHP Chinese website!
 How to clear stringbuilder
How to clear stringbuilder
 How to open php files on mobile phone
How to open php files on mobile phone
 What should I do if the docker container cannot access the external network?
What should I do if the docker container cannot access the external network?
 localhost8080 cannot access solution
localhost8080 cannot access solution
 amd catalyst
amd catalyst
 Why is there no response when headphones are plugged into the computer?
Why is there no response when headphones are plugged into the computer?
 Bulk trading platform
Bulk trading platform
 What are the PHP visual Chinese development tools?
What are the PHP visual Chinese development tools?





















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



