


This article introduces the Chinese CLIP large-scale pre-training image and text representation model recently open sourced by the Damo Academy Magic Community ModelScope, which can better understand Chinese and Chinese Internet images, and can perform multiple tasks such as image and text retrieval and zero-sample image classification. To achieve the best results, the code and models have all been open source, so users can use Magic to get started quickly.

In the current Internet ecosystem, there are countless multi-modal related tasks and scenarios, such as image and text retrieval, image classification, video and image and text content and other scenarios. In recent years, image generation, which has become popular all over the Internet, has become even more popular and has quickly gone out of the circle. Behind these tasks, a powerful image and text understanding model is obviously necessary. I believe everyone will be familiar with the CLIP model launched by OpenAI in 2021. Through simple image-text twin tower comparison learning and a large amount of image-text corpus, the model has significant image-text feature alignment capabilities, and can be used in zero-sample image classification, It has outstanding results in cross-modal retrieval and is also used as a key module in image generation models such as DALLE2 and Stable Diffusion.
But unfortunately, OpenAI CLIP’s pre-training mainly uses graphic and text data from the English world and cannot naturally support Chinese. Even if there are researchers in the community who have distilled multilingual versions of Multilingual-CLIP (mCLIP) through translated texts, they still cannot meet the needs of the Chinese world, and their understanding of texts in the Chinese field is not very good, such as searching for "Spring Festival couplets" , but what is returned is Christmas-related content:

##mCLIP Retrieve demo Search for "Spring Festival Couplets" Return results
This also shows that we need a CLIP who understands Chinese better, not only understands our language, but also understands the images of the Chinese world.
2. MethodResearchers at DAMO Academy collected large-scale Chinese image-text pair data (approximately 200 million in size), including data from LAION-5B Chinese subset, Wukong's Chinese data, and translated graphic and text data from COCO, Visual Genome, etc. Most of the training images and texts come from public data sets, which greatly reduces the difficulty of reproduction. In terms of training methods, in order to effectively improve the training efficiency and model effect of the model, the researchers designed a two-stage training process:
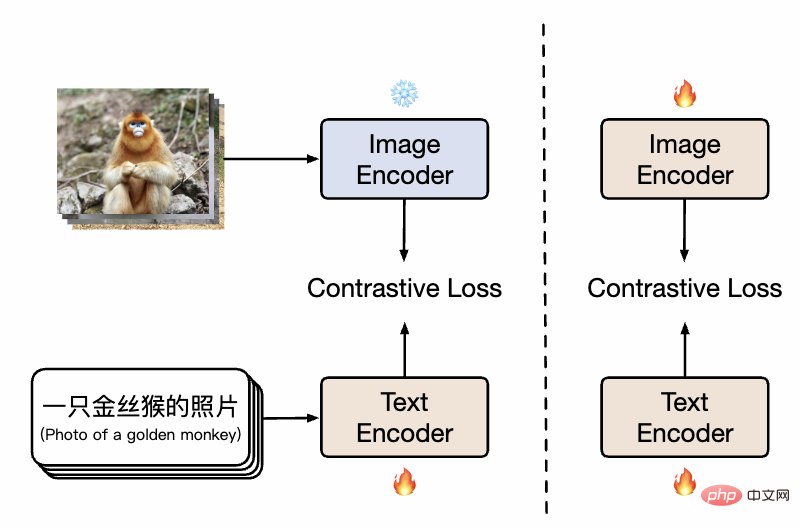
##Chinese CLIP method diagram
As shown in the figure, in the first stage, the model uses the existing image pre-training model and text pre-training The model initializes the twin towers of Chinese-CLIP separately and freezes the image-side parameters, allowing the language model to associate with the existing image pre-training representation space while reducing training overhead. Subsequently, in the second stage, the image side parameters are unfrozen, allowing the image model and language model to be associated while modeling the data distribution with Chinese characteristics. The researchers found that compared with pre-training from scratch, this method showed significantly better experimental results on multiple downstream tasks, and its significantly higher convergence efficiency also meant smaller training overhead. Compared with only training the text side in one stage of training, adding the second stage of training can effectively further improve the effect on downstream graphics and text tasks, especially graphics and text tasks native to Chinese (rather than translated from English data sets).
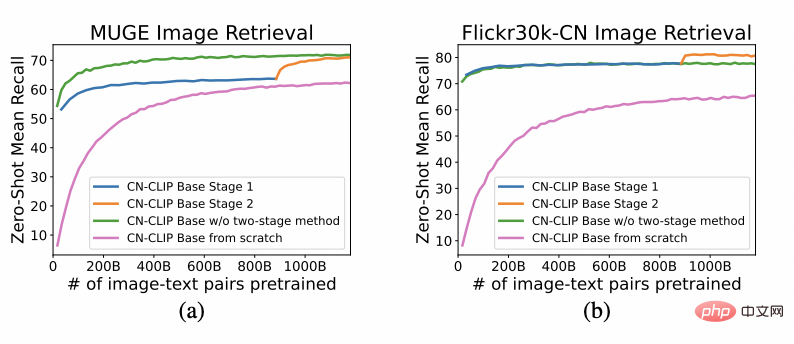
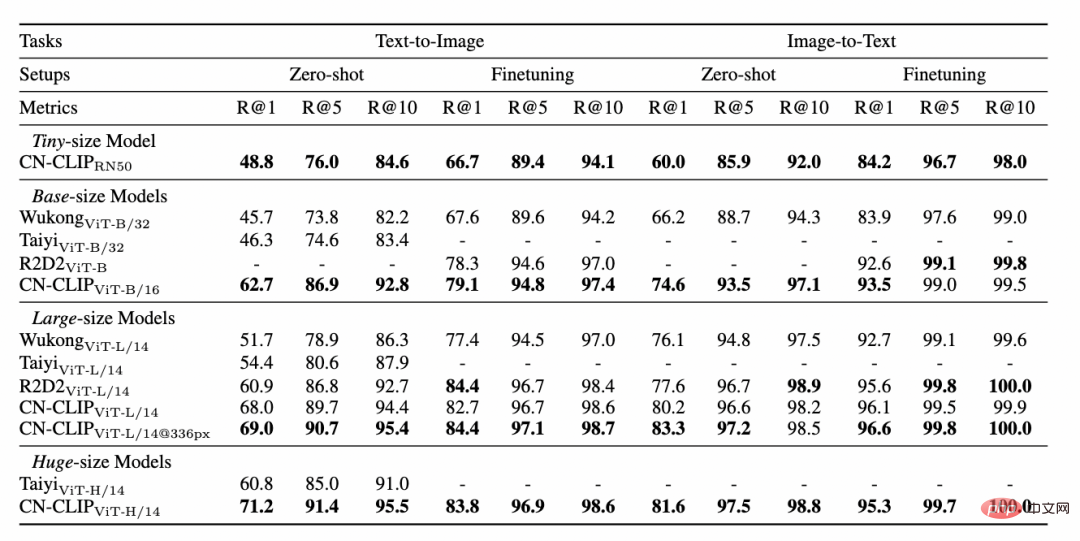
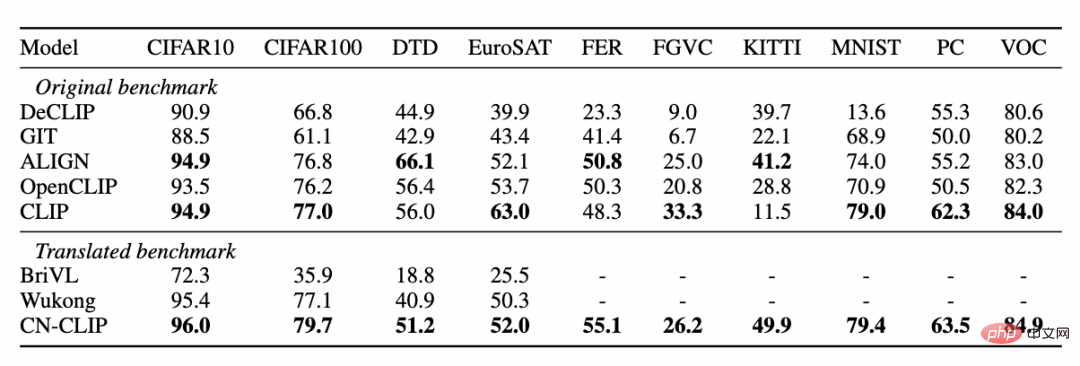
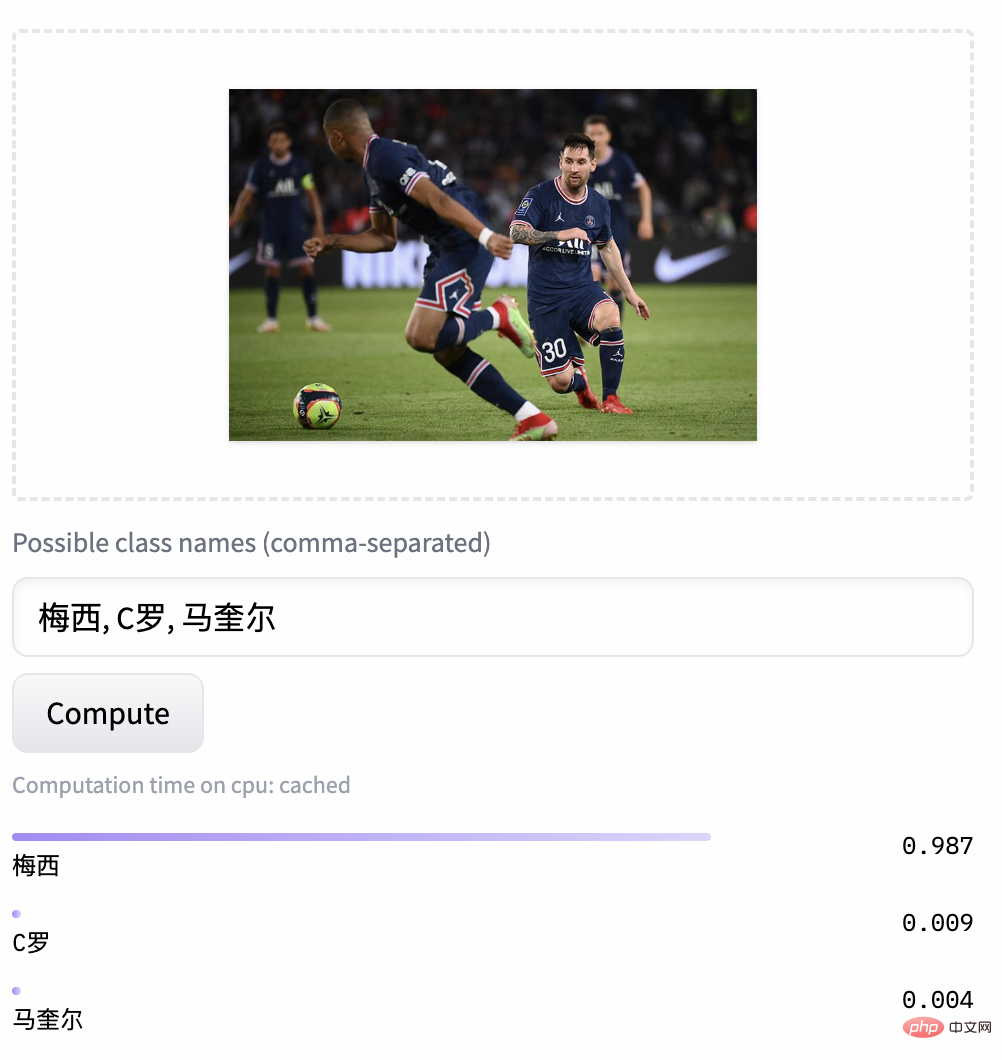
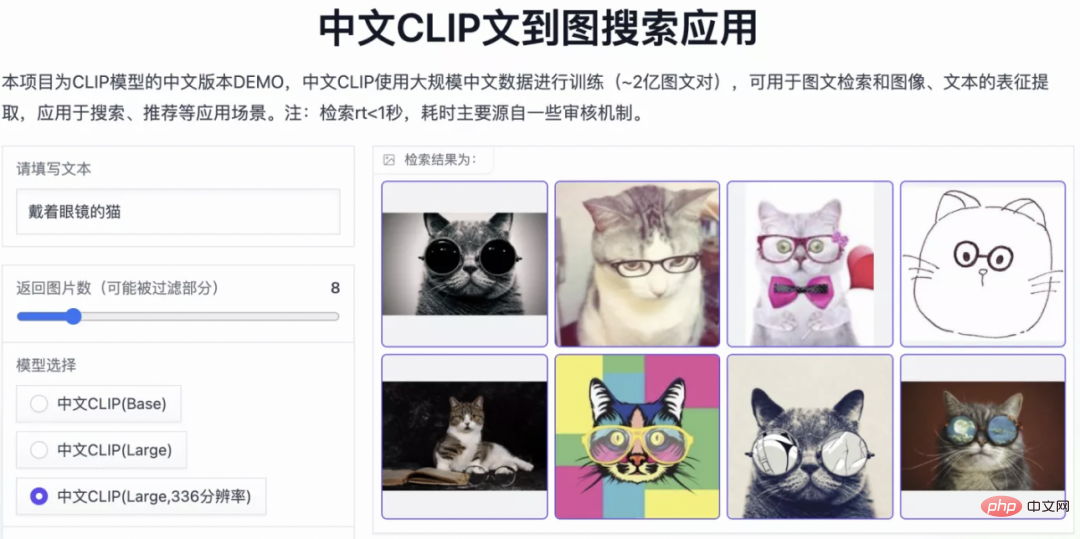
On two data sets: MUGE Chinese e-commerce image and text retrieval, Flickr30K-CN translation version general image and text retrieval Observe the effect change trend of zero-shot as pre-training continues Using this strategy, researchers have trained models of multiple scales, from the smallest ResNet-50, ViT-Base and Large to ViT-Huge. They are all now open and users can fully access them on demand. Use the model that best suits your scenario: Multiple experimental data show that Chinese-CLIP can be used in Chinese Cross-modal retrieval has achieved the best performance. Among them, on the Chinese native e-commerce image retrieval data set MUGE, Chinese CLIP of multiple scales has achieved the best performance at this scale. On data sets such as English-native Flickr30K-CN, Chinese CLIP can significantly exceed domestic baseline models such as Wukong, Taiyi, and R2D2, regardless of zero sample or fine-tuning settings. This is largely due to Chinese-CLIP's larger Chinese pre-training image and text corpus, and Chinese-CLIP is different from some existing domestic image and text representation models in order to minimize the training cost and freeze the entire image side. Instead, it uses two Staged training strategies to better adapt to the Chinese field: MUGE Chinese e-commerce image and text retrieval data Set experimental results ##Flickr30K-CN Chinese image and text retrieval data set experimental results #At the same time, the researchers verified the effect of Chinese CLIP on the zero-sample image classification data set. Since there are not many authoritative zero-shot image classification tasks in the Chinese field, the researchers are currently testing on the English translation version of the data set. Chinese-CLIP can achieve comparable performance to CLIP on these tasks through Chinese prompts and category labels: Zero-sample classification experiment results #Zero-sample image classification example 4. Quick use
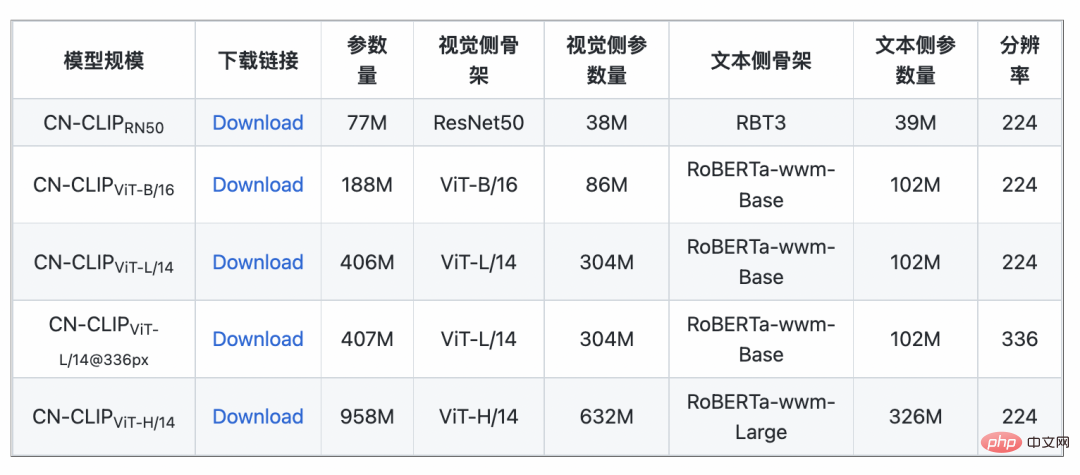
3. Experiment
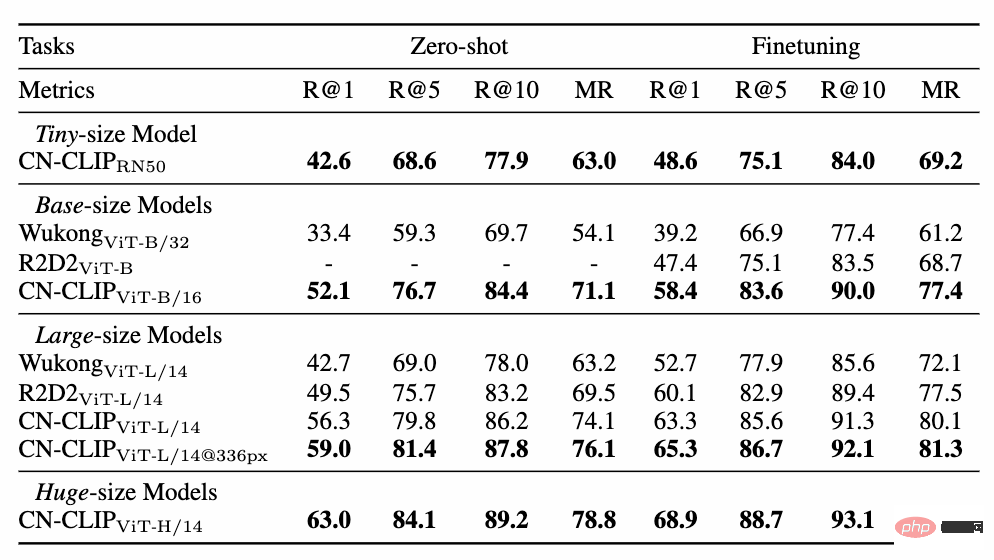

 5. Conclusion
5. Conclusion
The above is the detailed content of CLIP is not down to earth? You need a model that understands Chinese better. For more information, please follow other related articles on the PHP Chinese website!
 Solution to the problem that setting the Chinese interface of vscode does not take effect
Solution to the problem that setting the Chinese interface of vscode does not take effect
 C++ software Chinese change tutorial
C++ software Chinese change tutorial
 How to solve the problem that Apple cannot download more than 200 files
How to solve the problem that Apple cannot download more than 200 files
 Usage of urlencode function
Usage of urlencode function
 The memory cannot be written solution
The memory cannot be written solution
 What is the difference between pass by value and pass by reference in java
What is the difference between pass by value and pass by reference in java
 The difference between array pointer and pointer array
The difference between array pointer and pointer array
 The advantages of OTC trading
The advantages of OTC trading








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



