


As we all know, OpenAI is not Open when it comes to ChatGPT. The Yangtuo series models open sourced from Meta are also "limited to academic research applications" due to issues such as data sets. People are still looking for bypasses. When it comes to restricting methods, here comes the big model that focuses on 100% open source.
On April 12, Databricks released Dolly 2.0, which is another new version of the ChatGPT-like human interactivity (instruction following) large language model (LLM) released two weeks ago .
Databricks says Dolly 2.0 is the industry’s first open source, directive-compliant LLM, fine-tuned on a transparent and freely available dataset that is also open source. Can be used for commercial purposes. This means Dolly 2.0 can be used to build commercial applications without paying for API access or sharing data with third parties.

According to Databricks CEO Ali Ghodsi, while there are other large models that can be used for commercial purposes, "they don't talk to you like Dolly 2.0." And based on the Dolly 2.0 model, users can modify and improve training data , as it is freely available under an open source license. So you can make your own version of Dolly.
Databricks also released the dataset on which Dolly 2.0 was fine-tuned, called databricks-dolly-15k. This is a corpus of more than 15,000 records generated by thousands of Databricks employees. Databricks calls it "the first open source, human-generated instruction corpus, specifically designed to enable large languages to demonstrate the magical interactivity of ChatGPT" ."
In the past two months, the industry and academia have caught up with OpenAI and proposed a wave of ChatGPT-like tools that follow instructions. Models, these versions are considered open source by many definitions (or offer some degree of openness or limited access). Among them, Meta's LLaMA has attracted the most attention, which has led to a large number of further improved models, such as Alpaca, Koala, Vicuna, and Databricks' Dolly 1.0.
But on the other hand, many of these "open" models are under "industrial restrictions" because they are trained on datasets with terms designed to limit commercial use - For example, the 52,000 question and answer data set from the StanfordAlpaca project was trained on the output of OpenAI's ChatGPT. And OpenAI’s terms of use include a rule that you can’t use OpenAI’s services to compete with them.
Databricks thought about ways to solve this problem: the newly proposed Dolly 2.0 is a 12 billion parameter language model, which is based on the open source EleutherAI pythia model series and is specifically designed for small open source instruction record corpora Fine-tuned (databricks-dolly-15k), this dataset was generated by Databricks employees and licensed under terms that permit use, modification, and extension for any purpose, including academic or commercial applications.
Until now, models trained on the output of ChatGPT have been in a legal gray area. “The entire community has been tiptoeing around this problem, and everyone is releasing these models, but none of them are commercially available,” Ghodsi said. "That's why we're so excited." "Everyone else wants to go bigger, but we're actually interested in something smaller," Ghodsi said of Dolly of miniature scale. "Secondly, we looked through all the answers and it is of high quality."
Ghodsi said he believes Dolly 2.0 will start a "snowball" effect and allow other players in the field of artificial intelligence to People join in and come up with other alternatives. He explained that restrictions on commercial use were a big hurdle to overcome: "We're excited now because we finally found a way around it. I guarantee you're going to see people applying these 15,000 problems to the real world. Every model there is, they'll see how many of these models suddenly become a little bit magical and you can interact with them."
To download the weights for the Dolly 2.0 model, simply visit the Databricks Hugging Face page and visit the Dolly repo of databricks-labs to download the databricks-dolly-15k dataset.
The "databricks-dolly-15k" dataset contains 15,000 high-quality human-generated prompt/reply pairs, by more than 5,000 Databricks employees in 2023 Written during March and April, is specifically designed to provide instructions for tuning large language models. These training recordings are natural, expressive and designed to represent a wide range of behaviors, from brainstorming and content generation to information extraction and summarization.
According to the license terms of this data set (Creative Commons Attribution-ShareAlike 3.0 Unported License), anyone can use, modify or extend this data set for any purpose, including commercial applications.
Currently, this dataset is the first open source, human-generated instruction dataset.
Why create such a data set? The team also explained why in a blog post.
A key step in creating Dolly 1.0, or any directive that follows LLM, is to train the model on a dataset of directive and reply pairs. Dolly 1.0 costs $30 to train and uses a dataset created by the Alpaca team at Stanford University using the OpenAI API.
After Dolly 1.0 was released, many people asked to try it out, and some users also wanted to use this model commercially.
But the training dataset contains the output of ChatGPT, and as the Stanford team points out, the terms of service try to prevent anyone from creating a model that competes with OpenAI.
Previously, all well-known directive compliance models (Alpaca, Koala, GPT4All, Vicuna) were subject to this restriction: commercial use was prohibited. To solve this problem, Dolly's team began looking for ways to create a new dataset without restrictions on commercial use.
Specifically, the team learned from a research paper published by OpenAI that the original InstructGPT model was trained on a data set consisting of 13,000 instruction-following behavior demonstrations. Inspired by this, they set out to see if they could achieve similar results, led by Databricks employees.
It turns out that generating 13,000 questions and answers was harder than imagined. Because every answer must be original and cannot be copied from ChatGPT or anywhere on the web, otherwise it will "pollute" the data set. But Databricks has more than 5,000 employees, and they were very interested in LLM. So the team conducted a crowdsourcing experiment that created a higher-quality dataset than what 40 annotators had created for OpenAI.
Of course, this work is time-consuming and labor-intensive. In order to motivate everyone, the team has set up a competition, and the top 20 annotators will receive surprise prizes. At the same time, they also listed 7 very specific tasks:
Here are some examples:


## Initially, the team was skeptical about reaching 10,000 results. But with nightly leaderboard play, it managed to hit 15,000 results in one week.
The team then shut down the game due to concerns about "tying up staff productivity" (which makes sense).
Feasibility of commercializationAfter the data set was quickly created, the team began to consider commercial applications.
They wanted to make an open source model that could be used commercially. Although databricks-dolly-15k is much smaller than Alpaca (the dataset on which Dolly 1.0 was trained), the Dolly 2.0 model based on EleutherAI pythia-12b exhibits high-quality instruction following behavior.
In hindsight, this is not surprising. After all, many instruction tuning datasets released in recent months contain synthetic data, which often contain hallucinations and factual errors.
databricks-dolly-15k, on the other hand, is generated by professionals, is of high quality, and contains long-form answers to most tasks.
Here are some examples of Dolly 2.0 used for summarization and content generation:

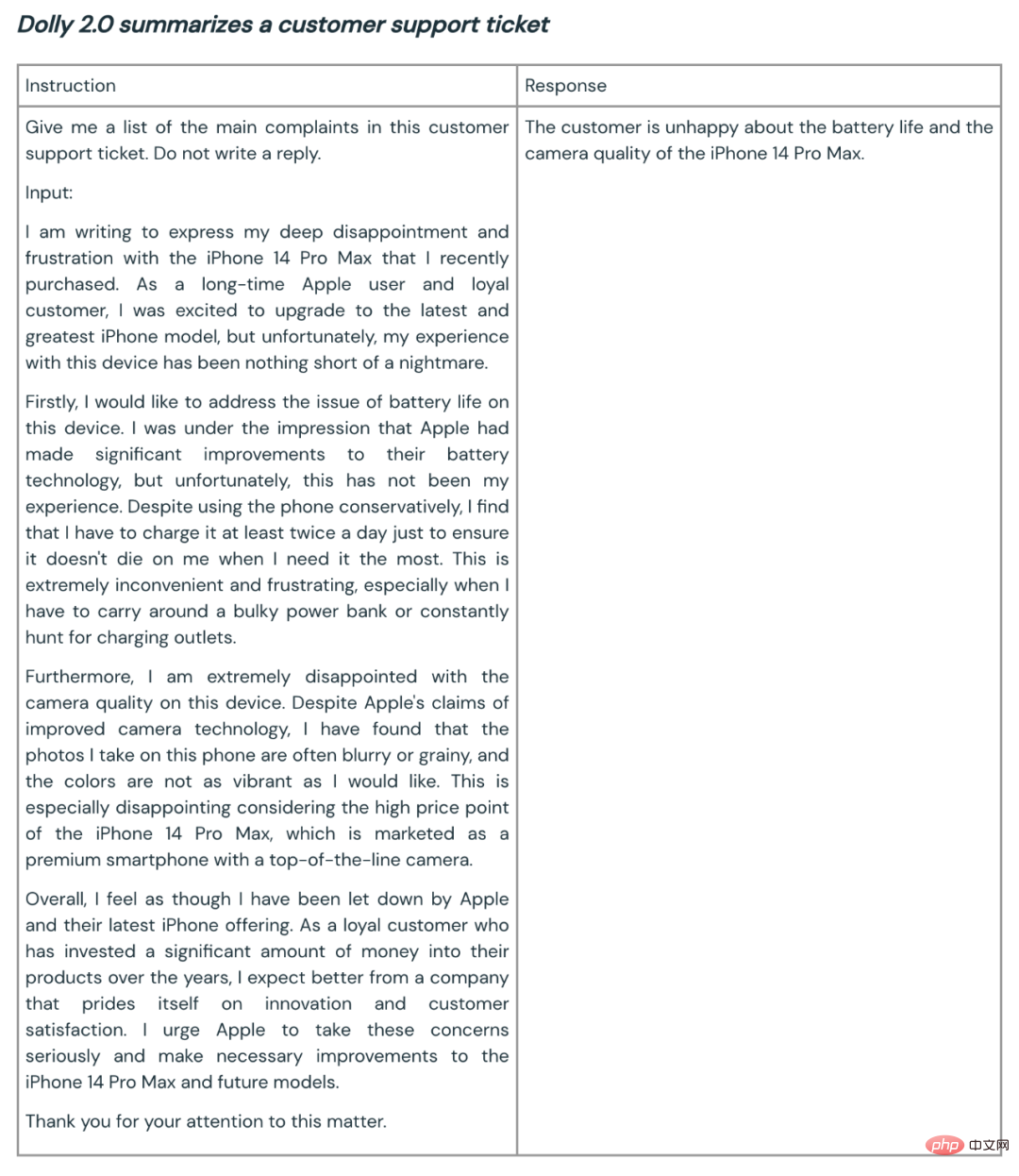

Based on initial customer feedback, the Dolly team says capabilities like this could have broad application across the enterprise. Because many companies want to have their own models to create higher-quality models for their own specific domain applications, rather than handing over their sensitive data to third parties.
The open source of Dolly 2 is a good start for building a better large model ecosystem. Open source datasets and models encourage commentary, research, and innovation, helping to ensure that everyone benefits from advances in AI technology. The Dolly team expects the new model and open-source dataset will serve as the seeds for much subsequent work, helping to lead to more powerful language models.
The above is the detailed content of The world's first truly open source ChatGPT large model Dolly 2.0, which can be modified at will for commercial use. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



