


Due to their complexity, neural networks are often considered the “holy grail” for solving all machine learning problems. Tree-based methods, on the other hand, have not received equal attention, mainly due to the apparent simplicity of such algorithms. However, these two algorithms may seem different, but they are like two sides of the same coin, both important.

Tree-based methods are usually better than neural networks. Essentially, tree-based methods and neural network-based methods are placed in the same category because they both approach the problem through step-by-step deconstruction, rather than splitting the entire data set through complex boundaries like support vector machines or logistic regression. .
Obviously, tree-based methods gradually segment the feature space along different features to optimize information gain. What is less obvious is that neural networks also approach tasks in a similar way. Each neuron monitors a specific part of the feature space (with multiple overlaps). When input enters this space, certain neurons are activated.
Neural networks view this piece-by-piece model fitting from a probabilistic perspective, while tree-based methods take a deterministic perspective. Regardless, the performance of both depends on the depth of the model, since their components are associated with various parts of the feature space.
A model with too many components (nodes for a tree model, neurons for a neural network) will overfit, while a model with too few components simply won’t give Meaningful predictions. (Both of them start by memorizing data points, rather than learning generalization.)
If you want to understand more intuitively how the neural network divides the feature space, you can read this introduction Article on the Universal Approximation Theorem: https://medium.com/analytics-vidhya/you-dont-understand-neural-networks-until-you-understand-the-universal-approximation-theory-85b3e7677126.
While there are many powerful variations of decision trees, such as Random Forest, Gradient Boosting, AdaBoost, and Deep Forest, in general, tree-based methods are essentially simplifications of neural networks Version.
Tree-based methods solve the problem piece by piece through vertical and horizontal lines to minimize entropy (optimizer and loss). Neural networks use activation functions to solve problems piece by piece.
Tree-based methods are deterministic rather than probabilistic. This brings some nice simplifications like automatic feature selection.
The activated condition nodes in the decision tree are similar to the activated neurons (information flow) in the neural network.
The neural network transforms the input through fitting parameters and indirectly guides the activation of subsequent neurons. Decision trees explicitly fit parameters to guide the flow of information. (This is the result of deterministic versus probabilistic.)
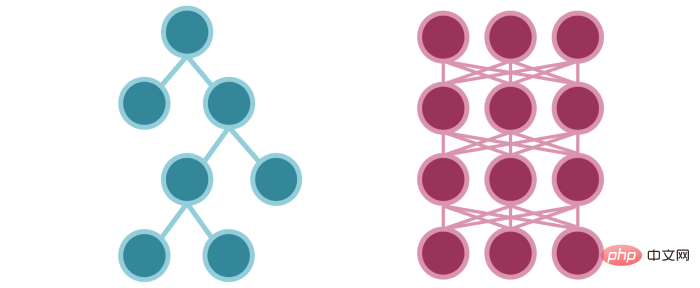
The flow of information in the two models is similar, just in the tree model The flow method is simpler.
Of course, this is an abstract conclusion, and it may even be possible Controversial. Granted, there are many obstacles to making this connection. Regardless, this is an important part of understanding when and why tree-based methods are better than neural networks.
For decision trees, working with structured data in tabular or tabular form is natural. Most people agree that using neural networks to perform regression and prediction on tabular data is overkill, so some simplifications are made here. The choice of 1s and 0s, rather than probabilities, is the main source of the difference between the two algorithms. Therefore, tree-based methods can be successfully applied to situations where probabilities are not required, such as structured data.
For example, tree-based methods show good performance on the MNIST dataset because each number has several basic features. There is no need to calculate probabilities and the problem is not very complex, which is why a well-designed tree ensemble model can perform as well as or better than modern convolutional neural networks.
Generally, people tend to say that "tree-based methods just remember the rules", which is correct. Neural networks are the same, except they can remember more complex, probability-based rules. Rather than explicitly giving a true/false prediction for a condition like x>3, the neural network amplifies the input to a very high value, resulting in a sigmoid value of 1 or generating a continuous expression.
On the other hand, since neural networks are so complex, there is a lot that can be done with them. Both convolutional and recurrent layers are outstanding variants of neural networks because the data they process often require the nuances of probability calculations.
There are very few images that can be modeled with ones and zeros. Decision tree values cannot handle datasets with many intermediate values (e.g. 0.5) that's why it performs well on MNIST dataset where pixel values are almost all black or white but pixels of other datasets The value is not (e.g. ImageNet). Similarly, the text has too much information and too many anomalies to express in deterministic terms.
This is why neural networks are mainly used in these fields, and why neural network research stagnated in the early days (before the beginning of the 21st century) when large amounts of image and text data were not available. . Other common uses of neural networks are limited to large-scale predictions, such as YouTube video recommendation algorithms, which are very large and must use probabilities.
The data science team at any company will probably use tree-based models instead of neural networks, unless they are building a heavy-duty application like blurring the background of a Zoom video. But in daily business classification tasks, tree-based methods make these tasks lightweight due to their deterministic nature, and their methods are the same as neural networks.
In many practical situations, deterministic modeling is more natural than probabilistic modeling. For example, to predict whether a user will purchase an item from an e-commerce website, a tree model is a good choice because users naturally follow a rule-based decision-making process. A user’s decision-making process might look something like this:
Generally speaking, humans follow a rule-based and structured decision-making process. In these cases, probabilistic modeling is unnecessary.
The above is the detailed content of Machine Learning: Don't underestimate the power of tree models. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



