


Contrast Contrastive Learning (CL) is a popular research direction in the field of AI in recent years, attracting the attention of many researchers. Its self-supervised learning method was named AI at ICLR 2020 by big names such as Bengio and LeCun. In the future, it will successively participate in major conferences such as NIPS, ACL, KDD, CIKM, etc. Google, Facebook, DeepMind, Alibaba, Tencent, Byte and other major companies have also invested in it, and CL-related work has also maxed out the CV. Even the SOTA of some NLP problems has been in the limelight in the AI circle for a while.
The technical source of CL comes from metric learning. The general idea is: define the positive and negative examples of the sample, as well as the mapping relationship (map the entity to a new space), and the optimization goal is to make the positive examples in the space The distance between the target sample and the target sample is closer, while the negative example is relatively far away. Because of this, CL looks very similar to the idea of vectorized recall, but in fact there is an essential difference between the two. Vectorized recall is a type of supervised learning, with clear label data and more emphasis on the selection of negative samples ( Known as the "doctrine" that negative samples are king); and CL is a branch of self-supervised learning (a paradigm of unsupervised learning) that does not require manual label information and directly uses the data itself as supervision information to learn samples Characteristic expression of data, and then referenced in downstream tasks. In addition, the core technology of CL is data augmentation, which focuses more on how to construct positive samples. The following figure is an abstract CL overall flow chart

#The label information of contrastive learning comes from the data itself, and the core module is data enhancement. Data enhancement technology in the image field is relatively intuitive. For example, operations such as image rotation, occlusion, partial extraction, coloring, and blurring can produce a new image that is generally similar to the original image but partially different (that is, the enhanced new image). Figure), the figure below is a partial image data enhancement method (from SimCLR[1]).

When talking about the principle of CL, we have to mention self-supervised learning, which avoids the high cost of manual labeling, and The sparsity of low label coverage makes it easier to learn general feature representations. Self-supervised learning can be divided into two major categories: generative methods and contrastive methods. The typical representative of the generative method is the autoencoder, and the classic representative of contrastive learning is SimCLR of ICLR 2020, which learns feature representations through the comparison of (enhanced) positive and negative samples in the feature space. Compared with generative methods, the advantage of contrastive methods is that they do not need to reconstruct samples at the pixel level, and only need to learn distinguishability in the feature space, which makes related optimization simple. The author believes that the effectiveness of CL is mainly reflected in the distinguishability of the learningitem representation, and the learning of distinguishability relies on the construction ideas of positive and negative samples, as well as the specific model structure and optimization goals.
Combined with the implementation process of CL, Dr Zhang[2]abstracted three questions that CL must answer, which is also the difference between The typical characteristics of metric learning are (1) how to construct positive and negative examples, that is, how data enhancement is implemented; (2) how to construct the Encoder mapping function, which not only retains as much original information as possible, but also prevents Collapse problem; (3) How to design the loss function. The currently commonly used NCE loss is as shown in the following formula. It is not difficult to see that these three basic questions correspond to the three elements of modeling: sample, model, and optimization algorithm.
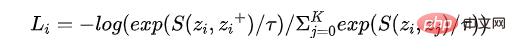
It can be seen from the loss formula that the numerator part emphasizes that the closer the distance to the positive example is, the better. The S function measures the similarity, and the closer the distance, the better. The larger the S value, the denominator emphasizes that the farther the distance from the negative example is, the better. The lower the loss, the higher the corresponding distinguishability.
Among these three basic issues, data enhancement is the core innovation of the CL algorithm. Different enhancement methods are the basic guarantee for the effectiveness of the algorithm and the identity of the major CL algorithms; the Encoder function is usually implemented with the help of neural networks; except In addition to NCE loss, there are other variations of loss. For example, Google[3] proposed a supervised contrast loss.
CL is a learning algorithm of self-supervised learning. When it comes to self-supervised learning, Bert is probably an unavoidable topic in the NLP field. Bert pre-training Fine- The tuning model has achieved breakthroughs in solving many problems. Since self-supervision can succeed in NLP, can't computer vision also do it? In fact, Bert's success in the field of NLP also directly stimulated the occurrence and development of CL in the field of images. In view of the fact that data enhancement can be carried out intuitively in the image field, CL is also the first to make progress in the field of CV. For example, the development opportunity of CL - SimCLR algorithm, its innovation points mainly include (1) exploring the combination of multiple different data enhancement technologies, The optimal one was selected; (2) A nonlinear mapping Projector was added after the Encoder, mainly because the vector representation learned by the Encoder will include enhanced information, while the Projector aims to remove this part of the influence and return to the essence of the data. Later, Hinton's students implemented SimCLR v2 based on SimCLR. The main improvement was in the network structure of the Encoder. They also drew on the idea of Memory Bank used by MoCo to further improve SOTA.
In fact, before SimCLR, Kaiming He proposed another classic algorithm for contrastive learning at the end of 2019MoCo[4], The main idea is that since the comparison is between positive and negative samples, increasing the number of negative samples can increase the difficulty of the learning task and thereby enhance model performance. Memory Bank is a classic idea to solve this problem, but it cannot avoid representation inconsistencies. In view of this problem, the MoCo algorithm proposes to use momentum to update the Encoder parameters to solve the problem of inconsistent encoding of new and old candidate samples. Later, Kaiming He proposed MoCo v2 on the basis of MoCo (after SimCLR was proposed). The main framework of the model has not been changed, and details such as the data enhancement method, Encoder structure and learning rate have been optimized.
Contrastive learning is not only a popular research direction in academia in image, text, multi-modal and other fields, but also in the industry represented by recommendation systems. world has been applied.
Google applies CL to the recommendation systemGoogle SSL[5], the purpose is to learn from unpopular and niche items High-quality vector representation to help solve the recommendation cold start problem. Its data enhancement technology mainly uses Random Feature Masking (RFM) and Correlated Feature Masking (CFM) methods (CFM solves the problem that RFM may construct invalid variants to a certain extent), and then CL is combined with the twin towers in the form of an auxiliary tower. The main tasks of recall are trained together. The overall process is shown in the figure below.

# During the training process of the model, the items of the main task mainly come from the exposure log, so they are also the head. Popular items are relatively friendly. In order to eliminate the influence of the Matthew effect, the sample construction in the auxiliary task needs to consider a different distribution from the main task. Subsequent CL also drew on this thinking in the practice process of Zhuanzhuan to ensure the model learning results. of adequate coverage.
Data enhancement is not limited to the item side, Alibaba-Seq2seq[6]Apply the idea of CL to the sequence recommendation problem, that is Enter the user behavior sequence and predict the next possible interactive item. Specifically, its data enhancement is mainly applied to the characteristics of user behavior sequences. The user's historical behavior sequence is divided into two sub-sequences according to time series. As a representation of the user after data enhancement, it is fed into the twin-tower model. The more similar the final output results are, the better. At the same time, in order to explicitly model the multiple interests of users, this article extracts multiple vectors in the Encoder part instead of compressing them into one user vector. Because with the splitting of subsequences and the construction of positive and negative examples, users naturally have vector representations of multiple behavior sequences. In positive examples, the vector of the previous part of the user's historical behavior is close to the vector of the latter part of the historical behavior. , and in the negative example, the distance between different users is relatively far, and even for the same user, the vector representations of products in different categories are relatively far away.
CL can also be applied in conjunction with other learning paradigms, Graph comparison learning[7], the overall framework is shown in the figure below

GCL usually enhances graph data by randomly deleting points or edges in the graph, while the author of this article tends to keep important structures and attributes unchanged, and perturbations occur on unimportant edges or nodes.
The image field is also possible, such as Meituan-ConSERT[8] algorithm, in experiments on sentence semantic matching tasks, improved by 8% compared to the previous SOTA (BERT-flow), and can still show good performance improvement with a small number of samples. This algorithm applies data enhancement to the Embedding layer and uses the method of implicitly generating enhanced samples. Specifically, four data enhancement methods are proposed: Adversarial Attack, Token Shuffling, Cutoff and Dropout, these four methods are all obtained by adjusting the Embedding matrix, which is more efficient than the explicit enhancement method.
The Zhuanzhuan platform is committed to promoting the better development of low-carbon circular economy and can cover all categories of goods. In recent years, the development performance in the field of mobile phone 3C is especially great. protrude. CL’s practice in the Zhuanzhuan recommendation system also chooses a text-based application idea. Considering the unique attributes of second-hand transactions, the problems that need to be solved include (1) the orphan attribute of second-hand goods, which makes the vector of the ID class not applicable; (2) How data enhancement is implemented; (3) How positive and negative examples are constructed; (4) What is the model structure of the Encoder (including loss design issues). To address these four issues, we will explain them in detail in conjunction with the overall flow chart below
For the problem of orphan attributes of second-hand goods, we use text-based vectors as the representation of goods. Specifically, we use the text description of the goods ( Including title and content) set, train the word2vec model, and obtain the vector representation of the product through pooling based on the word vector.
The Auto Encoder algorithm is one of the commonly used data enhancement methods in the field of text contrastive learning (in addition to machine translation, CBERT and other different ideas), we also use the AE algorithm to train the model , learn the product vector, and use the intermediate vector of the algorithm as the enhanced vector representation of the product, and you will have a positive example.
The production principle of negative examples is to randomly select dissimilar products within the Batch. The basis for judging similar products is calculated based on the user's posterior click behavior. In the recall results of recommendation systems represented by CF (collaborative filtering), product combinations that can be recalled through common click behavior are considered similar, otherwise they are considered dissimilar. The reason why behavioral basis is used to determine similarity is, on the one hand, to introduce the user's behavior and achieve an organic combination of text and behavior; on the other hand, it is also to match the business goals as much as possible.
Specifically for the Encoder part, we use a twin-tower structure similar to the twin network. We feed the text vectors of the samples (positive or positive or negative) respectively to train the classification model. The network structure is three-layer fully connected. Neural network, the two towers share the network parameters and optimize the model parameters by optimizing the cross-entropy loss. In the actual industry, the training target of the twin-tower model in most recommendation systems is the user's posterior behavior (clicks, collections, orders, etc.), and our training target is whether the samples are similar or not. The reason why we adopt the form of twin network is, This is also because doing so can ensure the coverage of learning results.
According to the conventional ideas of CL, the input vector of the final Encoder part is extracted as a vector representation of the product, which can be further applied in the recall, rough ranking and even fine ranking of the recommendation system. Currently, the recall module of the Zhuanzhuan recommendation system has been implemented, which has increased the online order and bag rate by more than 10%.
Through manual evaluation and online AB experiments, the effectiveness of CL’s learned vector representation has been fully confirmed. After the recall module is implemented, it can be recommended This can be extended to other modules of the system and even other algorithm scenarios. Learning product vector representations in a pre-training manner (of course, you can also learn user vector representations) is just an application path. CL provides more of a learning framework or learning idea, through data enhancement and comparison. The algorithm learns the differentiability of items. This idea can be naturally introduced into the ranking module of the recommendation system, because the ranking problem can also be understood as the differentiability problem of items.
About the author
Li Guangming, senior algorithm engineer. Participated in the construction of algorithm systems for Zhuanzhuan search algorithm, recommendation algorithm, user portrait and other systems, and has practical applications in GNN, small sample learning, comparative learning and other related fields.
[1]SimCLR: A_Simple_Framework_for_Contrastive_Learning_of_Visual_Representations
[2]Zhang Junlin: //m.sbmmt.com/link/be7ecaca534f98c4ca134e527b12d4c8
##[3]Google: Supervised_Contrastive_Learning
[4]MoCo: Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning
[5]SSL: Self-supervised_Learning_for_Large-scale_Item_Recommendations
[6]Ali-Seq2seq: Disentangled_Self-Supervision_in_Sequential_Recommenders
[7]GCL: Graph_contrastive_learning_with_adaptive_augmentation
[8]ConSERT: ConSERT:_A_Contrastive_Framework_for_Self-Supervised_Sentence_Representation_Transfer
The above is the detailed content of The practice of contrastive learning algorithms in Zhuanzhuan. For more information, please follow other related articles on the PHP Chinese website!
 Application of artificial intelligence in life
Application of artificial intelligence in life
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 How to enter recovery mode on win10 system computer
How to enter recovery mode on win10 system computer
 How to open bak file
How to open bak file
 what does facebook mean
what does facebook mean
 How to set textarea read-only
How to set textarea read-only
 How to export project in phpstorm
How to export project in phpstorm
 What should I do if the ps temporary disk is full?
What should I do if the ps temporary disk is full?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



