


arXiv paper "ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning", July 22, author from Shanghai Jiao Tong University, Shanghai AI Laboratory, University of California San Diego and JD.com Beijing Research Institute.

Propose a spatio-temporal feature learning scheme that can simultaneously provide a set of more representative features for perception, prediction and planning tasks, called ST-P3. Specifically, an egocentric-aligned accumulation technique is proposed to retain the geometric information in the 3-D space before sensing BEV conversion; the author designs a dual pathway model to Past motion changes are taken into account for future predictions; a time domain-based refinement unit is introduced to compensate for planned visual element recognition. Source code, model and protocol details open sourcehttps://github.com/OpenPerceptionX/ST-P3.
The pioneering LSS method extracts perspective features from multi-view cameras, lifts them to 3D through depth estimation, and fuses them into BEV space. Feature conversion between two views, whose latent depth prediction is crucial.
Upgrading two-dimensional planar information to three dimensions requires additional dimensions, that is, depth suitable for three-dimensional geometric autonomous driving tasks. To further improve feature representation, it is natural to incorporate temporal information into the framework since most scenes are tasked with video sources.
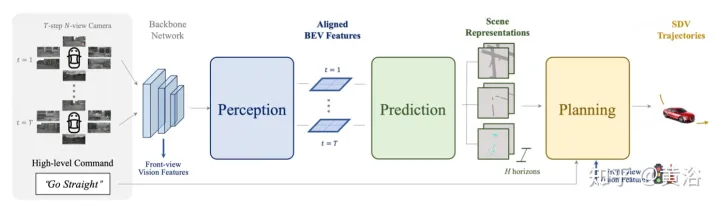
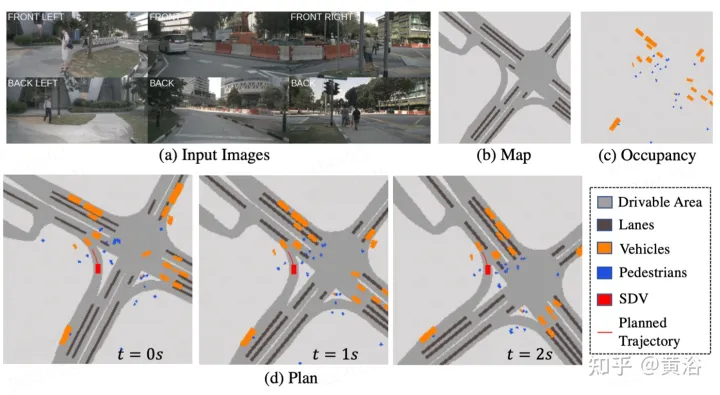
Described in the figureST- P3Overall framework: Specifically, given a set of surrounding camera videos, input them into the backbone to generate preliminary front view features. Performs auxiliary depth estimation to convert 2D features into 3D space. The self-centered alignment accumulation scheme first aligns past features to the current view coordinate system. Current and past features are then aggregated in three-dimensional space, preserving geometric information before converting to BEV representation. In addition to the commonly used prediction time domain model, performance is further improved by constructing a second path to explain past motion changes. This dual-path modeling ensures stronger feature representation to infer future semantic outcomes. In order to achieve the ultimate goal of trajectory planning, the early feature prior knowledge of the network is integrated. A refinement module was designed to generate the final trajectory with the help of high-level commands in the absence of HD maps.
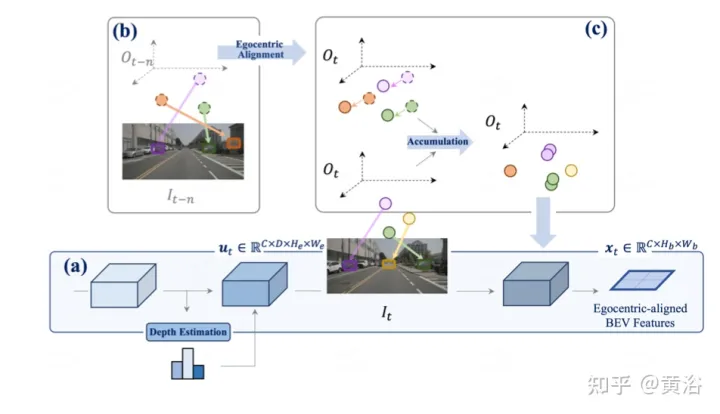
The picture shows the self-centered alignment accumulation method of perception. (a) Utilize depth estimation to lift the features at the current timestamp to 3D and merge into BEV features after alignment; (b-c) Align the 3D features of the previous frame with the current frame view and fuse with all past and current states, Thereby enhancing feature representation.
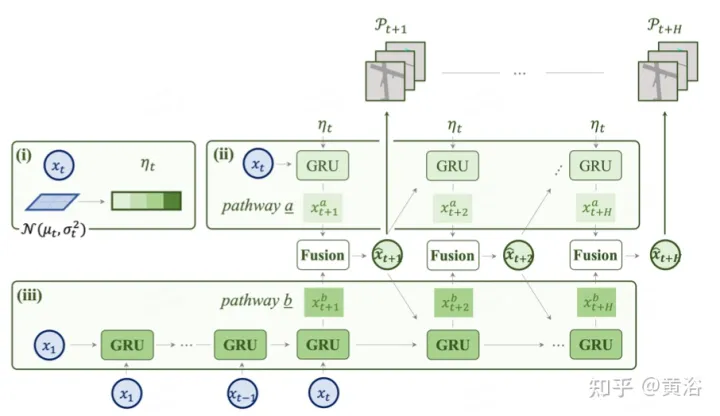
As shown in the figure is a two-way model used for prediction: (i) The latent code is the distribution from the feature map; (ii iii) Road a It incorporates an uncertainty distribution that indicates future multi-modalities, while path b learns from past changes, helping path a’s information to compensate.
#As the ultimate goal, it is necessary to plan a safe and comfortable trajectory to reach the target point. This motion planner samples a set of different trajectories and selects one that minimizes the learned cost function. However, integrating information from target points and traffic lights through a time domain model adds additional optimization steps.
The picture shows the integration and refinement of prior knowledge for planning: the overall cost diagram includes two sub-costs. Minimum-cost trajectories are further redefined using forward-looking features to aggregate vision-based information from camera inputs.
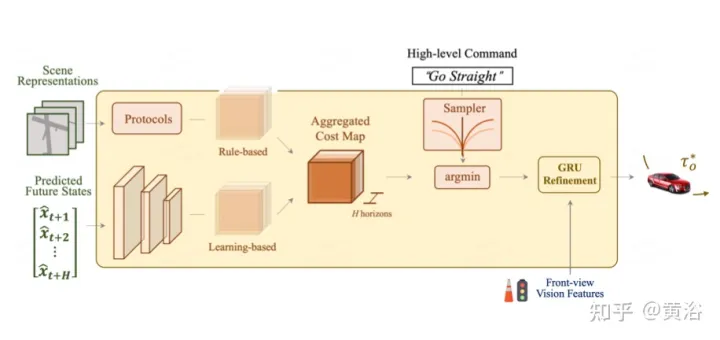
Penalize trajectories with large lateral acceleration, jerk, or curvature. Hopefully, this trajectory will reach its destination efficiently, so forward progress will be rewarded. However, the above cost items do not contain target information usually provided by route maps. Use high-level commands, including forward, turn left, and turn right, and evaluate trajectories only based on the corresponding commands.
In addition, traffic lights are crucial to SDV to optimize trajectories through the GRU network. The hidden state is initialized with the front camera features of the encoder module and each sample point of the cost term is used as input.
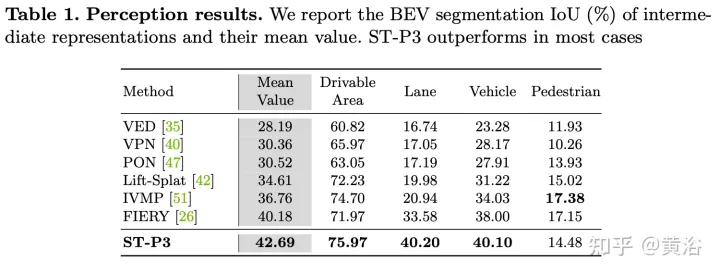
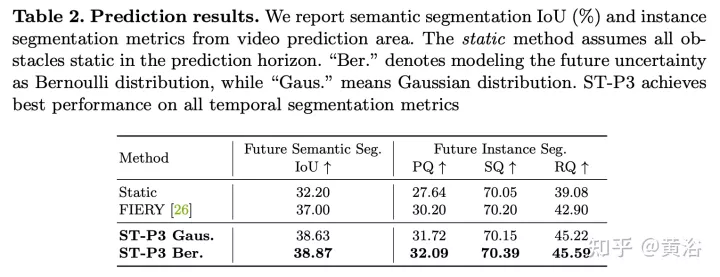
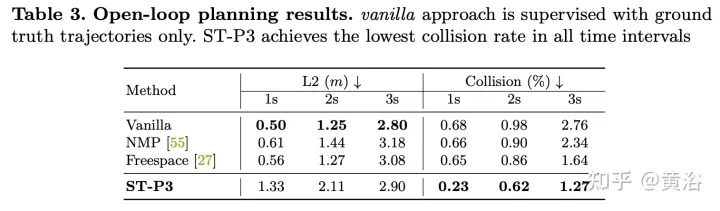
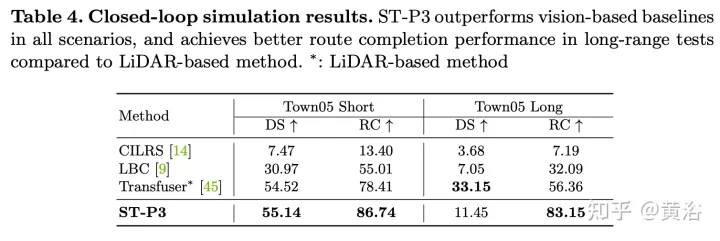
The experimental results are as follows:
The above is the detailed content of ST-P3: End-to-end spatiotemporal feature learning vision method for autonomous driving. For more information, please follow other related articles on the PHP Chinese website!
 What skills are needed to work in the PHP industry?
What skills are needed to work in the PHP industry?
 How to open pdb file
How to open pdb file
 How to read data from excel file in python
How to read data from excel file in python
 The difference between c language and python
The difference between c language and python
 How to view stored procedures in MySQL
How to view stored procedures in MySQL
 How to use the month function
How to use the month function
 Windows cannot connect to wifi solution
Windows cannot connect to wifi solution
 vcruntime140.dll cannot be found and code execution cannot continue
vcruntime140.dll cannot be found and code execution cannot continue








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



