


The arXiv paper "JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes", uploaded in July 22, reports on the work of Professor Tao Dacheng of the University of Sydney, Australia, and Beijing JD Research Institute.

Depth estimation, visual odometry (VO) and bird's eye view (BEV) scene layout estimation are three key tasks for driving scene perception, which is the key to motion in autonomous driving. Fundamentals of planning and navigation. Although complementary, they usually focus on separate tasks and rarely address all three simultaneously.
A simple approach is to do it independently in a sequential or parallel manner, but there are three disadvantages, namely 1) depth and VO results are affected by the inherent scale ambiguity problem; 2) BEV layout is usually done independently Estimating roads and vehicles while ignoring explicit overlay-underlay relationships; 3) Although depth maps are useful geometric cues for inferring scene layout, BEV layout is actually predicted directly from front view images without using any depth-related information.
This paper proposes a joint perception framework JPerceiver to solve these problems and simultaneously estimate scale-perceived depth, VO and BEV layout from monocular video sequences. Use a cross-view geometric transformation (CGT) to propagate absolute scale from the road layout to depth and VO according to a carefully designed scale loss. At the same time, a cross-view and cross-modal transfer (CCT) module is designed to use depth clues to reason about road and vehicle layout through attention mechanisms. JPerceiver is trained in an end-to-end multi-task learning method, in which the CGT scale loss and CCT modules promote knowledge transfer between tasks and facilitate feature learning for each task.
Code and model can be downloaded
https://github.com/sunnyHelen/JPerceiver. As shown in the figure, JPerceiver consists of three networks: depth, attitude and road layout, all based on the encoder-decoder architecture. The depth network aims to predict the depth map Dt of the current frame It, where each depth value represents the distance between a 3D point and the camera. The goal of the pose network is to predict the pose transformation Tt → t m between the current frame It and its adjacent frame It m. The goal of the road layout network is to estimate the BEV layout Lt of the current frame, that is, the semantic occupancy of roads and vehicles in the top-view Cartesian plane. The three networks are jointly optimized during training.
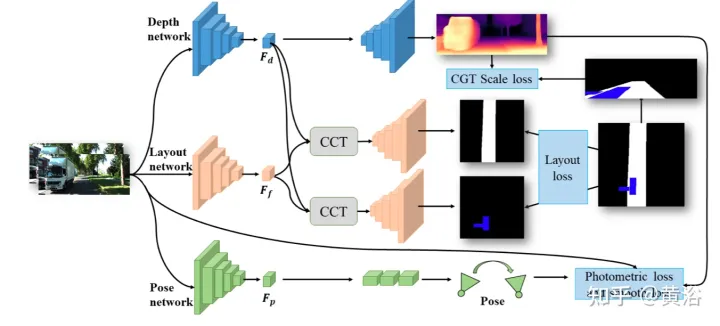 #The two networks predicting depth and pose are jointly optimized with photometric loss and smoothness loss in a self-supervised manner. In addition, the CGT scale loss is also designed to solve the scale ambiguity problem of monocular depth and VO estimation.
#The two networks predicting depth and pose are jointly optimized with photometric loss and smoothness loss in a self-supervised manner. In addition, the CGT scale loss is also designed to solve the scale ambiguity problem of monocular depth and VO estimation.
In order to achieve scale-aware environment perception, using the scale information in the BEV layout, the scale loss of CGT is proposed for depth estimation and VO. Since the BEV layout shows the semantic occupancy in the BEV Cartesian plane, it covers the range of Z meters in front of the vehicle and (Z/2) meters to the left and right respectively. It provides a natural distance field z, the metric distance zij of each pixel relative to the own vehicle, as shown in the figure:
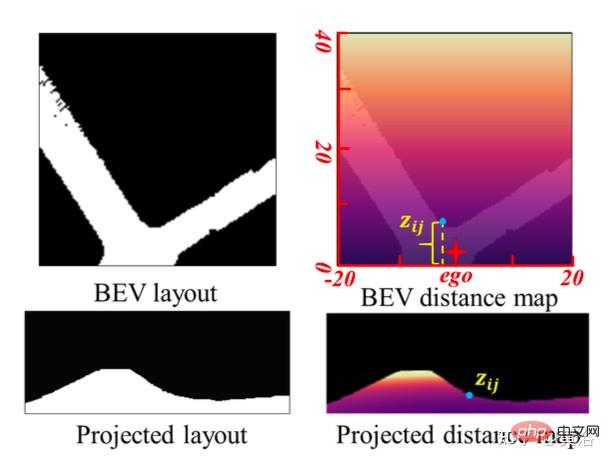 Assume that the BEV plane is the ground , its origin is just below the origin of the self-vehicle coordinate system. Based on the camera external parameters, the BEV plane can be projected to the forward camera through homography transformation. Therefore, the BEV distance field z can be projected into the forward camera, as shown in the figure above, and used to adjust the predicted depth d, thus deriving the CGT scale loss:
Assume that the BEV plane is the ground , its origin is just below the origin of the self-vehicle coordinate system. Based on the camera external parameters, the BEV plane can be projected to the forward camera through homography transformation. Therefore, the BEV distance field z can be projected into the forward camera, as shown in the figure above, and used to adjust the predicted depth d, thus deriving the CGT scale loss:
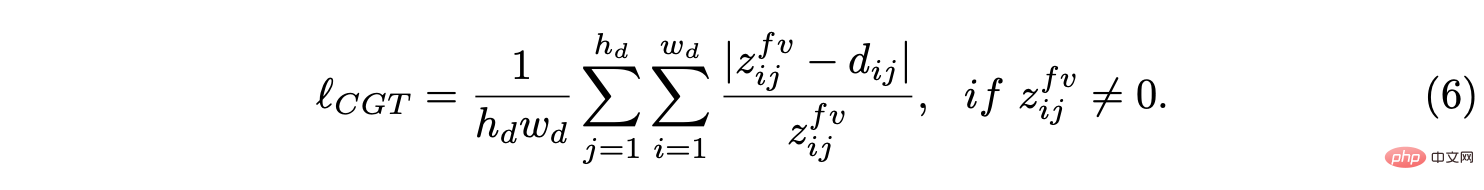 For roads For layout estimation, an encoder-decoder network structure is adopted. It is worth noting that a shared encoder is used as a feature extractor and different decoders to learn the BEV layout of different semantic categories simultaneously. In addition, a CCT module is designed to enhance feature interaction and knowledge transfer between tasks, and provide 3-D geometric information for BEV’s spatial reasoning. In order to regularize the road layout network, various loss terms are combined together to form a hybrid loss and achieve different classes of balanced optimization.
For roads For layout estimation, an encoder-decoder network structure is adopted. It is worth noting that a shared encoder is used as a feature extractor and different decoders to learn the BEV layout of different semantic categories simultaneously. In addition, a CCT module is designed to enhance feature interaction and knowledge transfer between tasks, and provide 3-D geometric information for BEV’s spatial reasoning. In order to regularize the road layout network, various loss terms are combined together to form a hybrid loss and achieve different classes of balanced optimization.
CCT studies the correlation between the forward view feature Ff, BEV layout feature Fb, re-converted forward feature Ff′ and forward depth feature FD, and refines the layout features accordingly, as shown in the figure Shown: divided into two parts, namely
CCT-CVand CCT-CM of the cross-view module and the cross-modal module.
In CCT, Ff and Fd are extracted by the encoder of the corresponding perceptual branch, while Fb is obtained by a view projection MLP to convert Ff to BEV, and a cycle loss constrained same MLP to re-convert it to Ff′.
In CCT-CV, the cross-attention mechanism is used to discover the geometric correspondence between the forward view and BEV features, and then guides the refinement of the forward view information and prepares for BEV inference. In order to make full use of the forward view image features, Fb and Ff are projected to patches: Qbi and Kbi, as query and key respectively.
In addition to utilizing forward view features, CCT-CM is also deployed to impose 3-D geometric information from Fd. Since Fd is extracted from the forward view image, it is reasonable to use Ff as a bridge to reduce the cross-modal gap and learn the correspondence between Fd and Fb. Fd plays the role of Value, thereby obtaining valuable 3-D geometric information related to BEV information and further improving the accuracy of road layout estimation.
In the process of exploring a joint learning framework to simultaneously predict different layouts, there are large differences in the characteristics and distribution of different semantic categories. For features, the road layout in driving scenarios usually needs to be connected, while different vehicle targets must be segmented.
Regarding the distribution, more straight road scenes are observed than turning scenes, which is reasonable in real data sets. This difference and imbalance increase the difficulty of BEV layout learning, especially jointly predicting different categories, since simple cross-entropy (CE) loss or L1 loss fails in this case. Several segmentation losses, including distribution-based CE loss, region-based IoU loss, and boundary loss, are combined into a hybrid loss to predict the layout of each category.
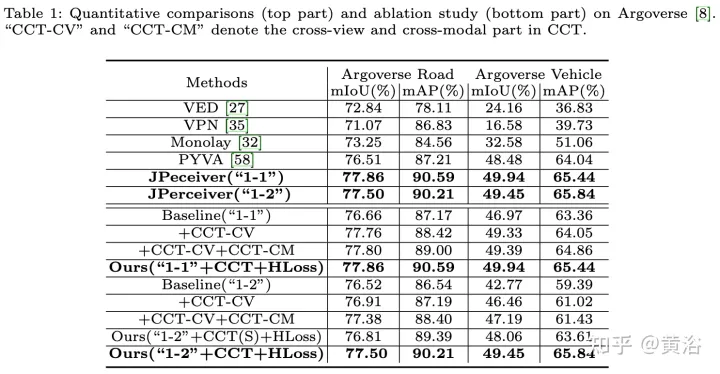
The experimental results are as follows:
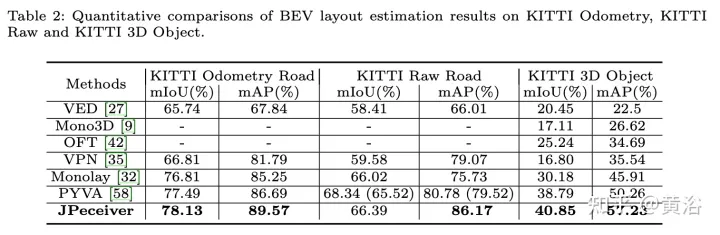
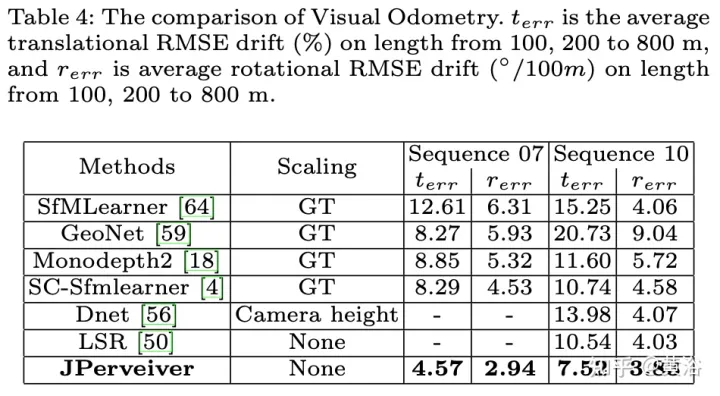
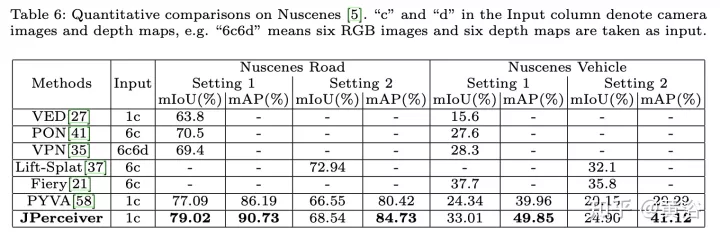
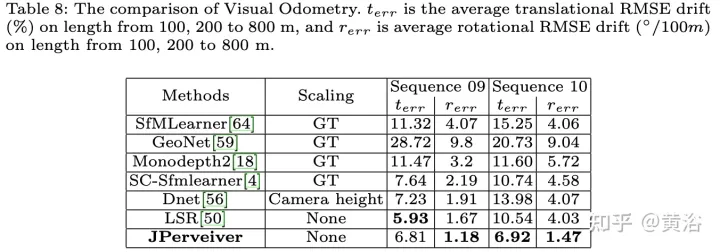 ##
##
The above is the detailed content of Perception network for depth, attitude and road estimation in joint driving scenarios. For more information, please follow other related articles on the PHP Chinese website!
 Usage of accept function
Usage of accept function
 How the tcp three-way handshake works
How the tcp three-way handshake works
 How to solve the problem of failure to load dll
How to solve the problem of failure to load dll
 How to save pictures in Douyin comment area to mobile phone
How to save pictures in Douyin comment area to mobile phone
 What are the python artificial intelligence libraries?
What are the python artificial intelligence libraries?
 How to set font in css
How to set font in css
 Main purpose of file system
Main purpose of file system
 Windows 10 service outage time
Windows 10 service outage time








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



