


In this article, I will explain in detail the paper "Why do tree-based models still outperform deep learning on tabular data" This paper explains an observation that has been observed by machine learning practitioners around the world in various fields. Phenomenon observed - tree-based models are much better at analyzing tabular data than deep learning/neural networks.
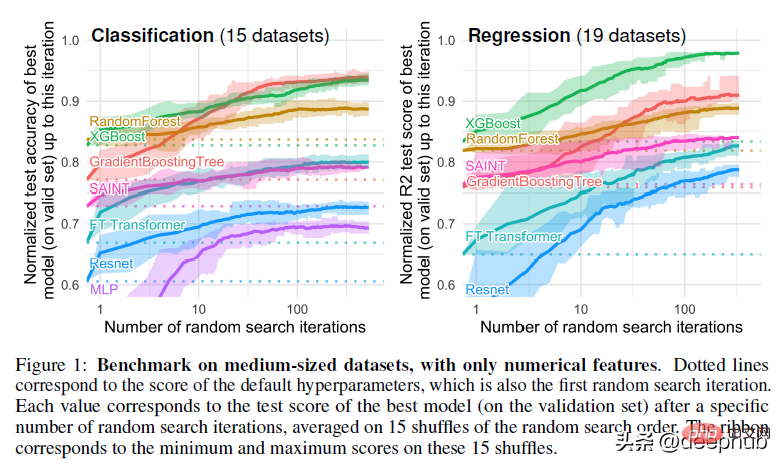
This paper has undergone a lot of preprocessing. For example, things like removing missing data can hinder tree performance, but random forests are great for missing data situations if your data is very messy: contains a lot of features and dimensions. The robustness and advantages of RF make it superior to more "advanced" solutions, which are prone to problems.

Most of the rest of the work is pretty standard. I personally don't like to apply too many pre-processing techniques as this can lead to losing a lot of the nuances of the dataset, but the steps taken in the paper basically produce the same dataset. However, it is important to note that the same processing method is used when evaluating the final results.
The paper also uses random search for hyperparameter tuning. This is also the industry standard, but in my experience Bayesian search is better suited for searching in a wider search space.
Understanding this, we can dive into our main question-why tree-based methods outperform deep learning?
This is the first reason the author shares why deep learning neural networks cannot compete with random forests. In short, neural networks have a hard time creating the best fit when it comes to non-smooth functions/decision boundaries. Random forests do better in weird/jagged/irregular patterns.

If I were to guess the reason, it might be the use of gradients in neural networks, and gradients rely on differentiable search spaces, which by definition are smooth, So it is impossible to distinguish between sharp points and some random functions. So I recommend learning AI concepts like Evolutionary Algorithms, Traditional Search and more basic concepts as these concepts can lead to great results in various situations when NN fails.
For a more specific example of the difference in decision boundaries between tree-based methods (RandomForests) and deep learners, take a look at the figure below -
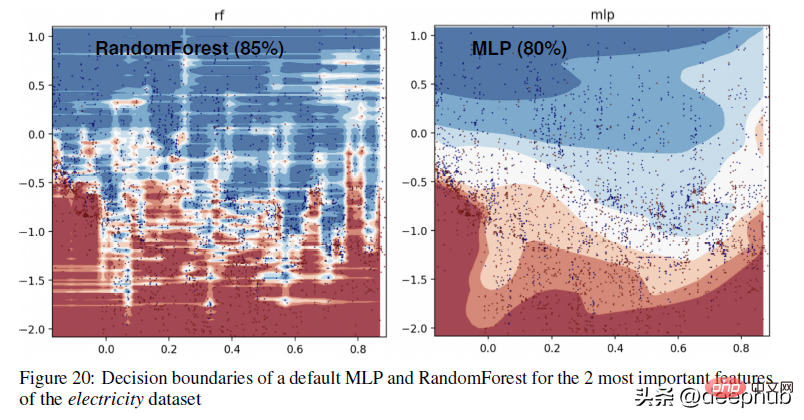
in the appendix , the author explains the above visualization as follows:
In this part, we can see that RandomForest is able to learn irregular patterns on the x-axis (corresponding to date features) that MLP cannot learn. We show this difference in default hyperparameters, which is typical behavior of neural networks, but in practice it is difficult (though not impossible) to find hyperparameters that successfully learn these patterns.
Another important factor, especially for those large data sets that encode multiple relationships at the same time. If you feed irrelevant features to a neural network, the results will be terrible (and you will waste more resources training your model). This is why it's so important to spend a lot of time on EDA/domain exploration. This will help understand the features and ensure everything runs smoothly.
The authors of the paper tested the performance of the model when adding random and removing useless features. Based on their results, 2 very interesting results were found
Removing a large number of features reduces the performance gap between models. This clearly shows that one of the advantages of tree models is their ability to judge whether features are useful and to avoid the influence of useless features.
Adding random features to a dataset shows that neural networks degrade much more severely than tree-based methods. ResNet especially suffers from these useless properties. The improvement of transformer may be because the attention mechanism in it will be helpful to a certain extent.
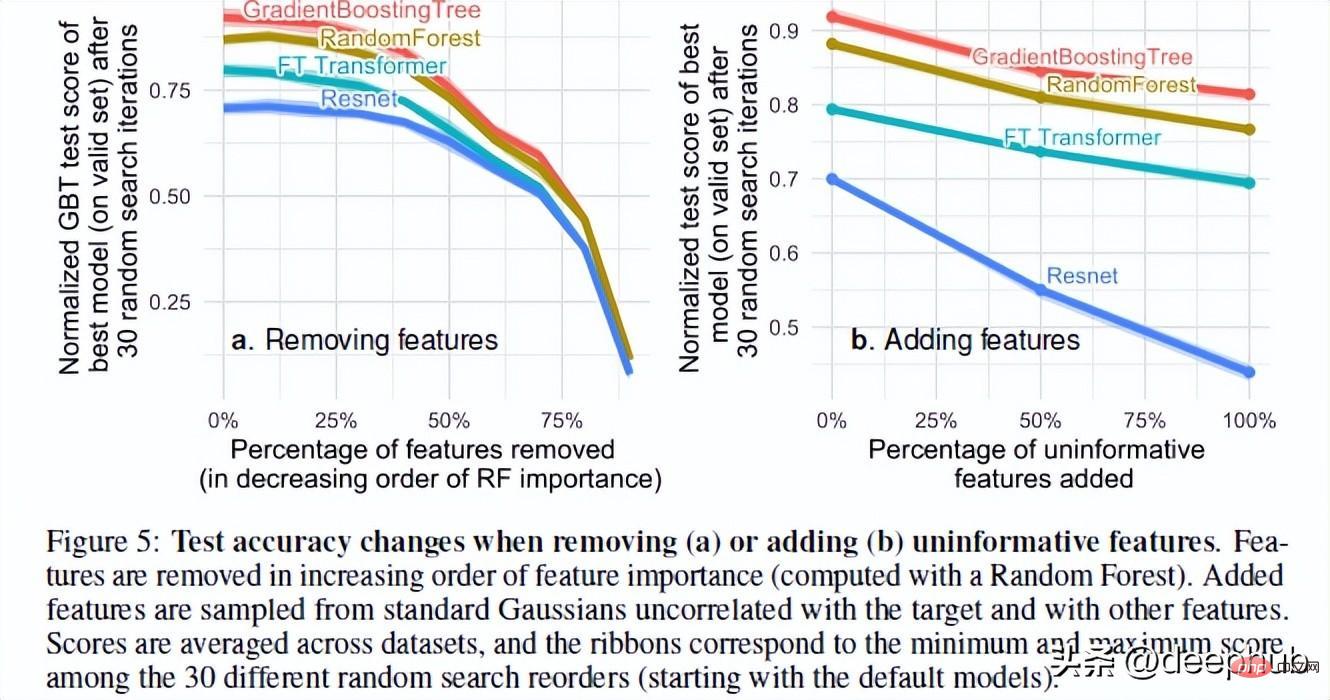
One possible explanation for this phenomenon is the way decision trees are designed. Anyone who has taken an AI course will know the concepts of information gain and entropy in decision trees. This enables the decision tree to choose the best path by comparing the remaining features.
Back to topic, there is one last thing that makes RF perform better than NN when it comes to tabular data. That's rotational invariance.
Neural networks are rotation invariant. This means that if you perform a rotation operation on your data sets, it will not change their performance. After rotating the dataset, the performance and ranking of different models changed significantly. Although ResNets was always the worst, it maintained its original performance after rotating, while all other models changed greatly.
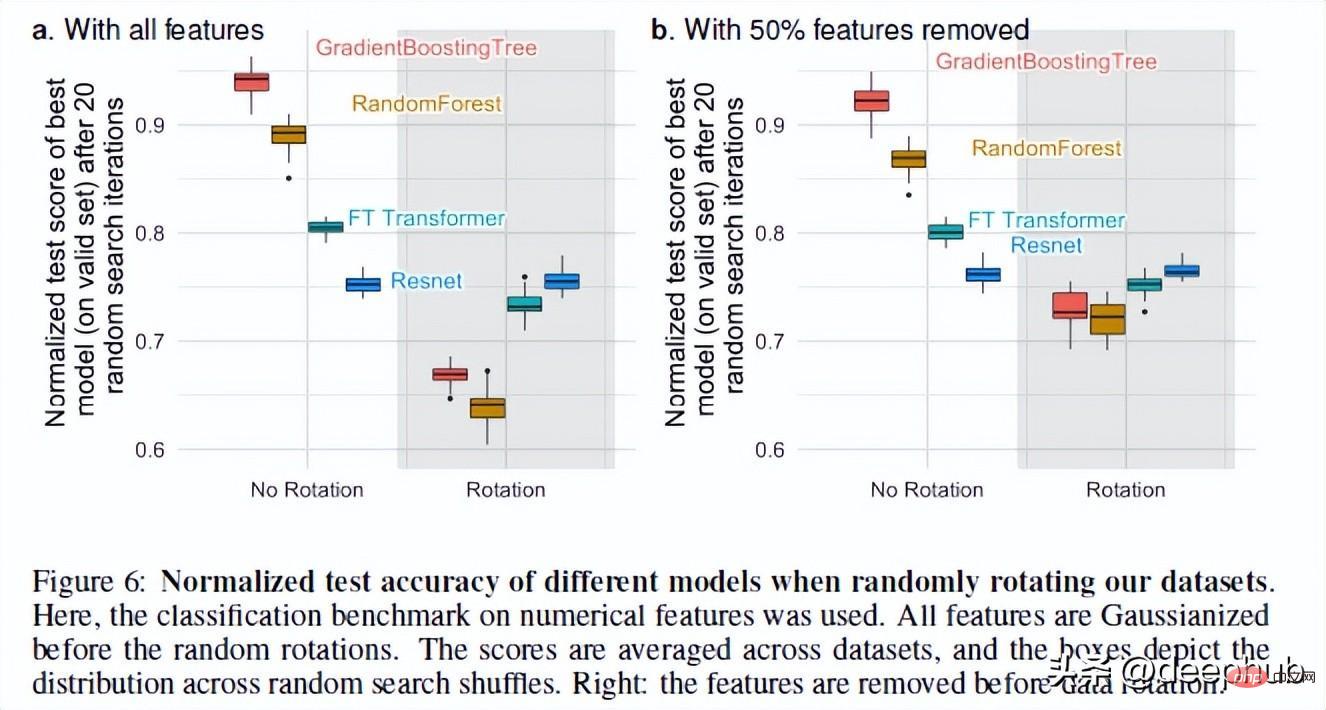
This is very interesting: what exactly does it mean to rotate a data set? There are no detailed explanations in the entire paper (I have contacted the author and will follow up this phenomenon). If you have any thoughts, please share them in the comments as well.
But this operation lets us see why rotation variance is important. According to the authors, taking linear combinations of features (which is what makes ResNets invariant) may actually misrepresent features and their relationships.
Obtaining optimal data biases by encoding the original data, which may mix features with very different statistical properties and cannot be recovered by a rotation-invariant model, will provide the model with Better performance.
This is a very interesting paper. Although deep learning has made great progress on text and image data sets, it basically has no advantage at all on tabular data. The paper uses 45 datasets from different domains for testing, and the results show that even without considering its superior speed, tree-based models are still state-of-the-art on moderate data (~10K samples).
The above is the detailed content of Why tree-based models still outperform deep learning on tabular data. For more information, please follow other related articles on the PHP Chinese website!
 How to delete blank pages in word without affecting other formats
How to delete blank pages in word without affecting other formats
 Permanently free oa system
Permanently free oa system
 What is the normal temperature of a laptop?
What is the normal temperature of a laptop?
 How to measure internet speed on computer
How to measure internet speed on computer
 What is the difference between golang and python
What is the difference between golang and python
 Introduction to the usage of vbs whole code
Introduction to the usage of vbs whole code
 How to read excel data in html
How to read excel data in html
 How to buy and sell Bitcoin on Ouyi platform
How to buy and sell Bitcoin on Ouyi platform








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



