


In autonomous driving, target detection through RGB images or lidar point clouds has been widely explored. However, how to make these two data sources complementary and beneficial to each other remains a challenge. AutoAlignV1 and AutoAlignV2 are mainly the work of the University of Science and Technology of China, Harbin Institute of Technology, and SenseTime (initially including the Chinese University of Hong Kong and Tsinghua University).
AutoAlignV1 comes from the arXiv paper "AutoAlign: Pixel-Instance Feature Aggregation for Multi-Modal 3D Object Detection", uploaded in April 2022.

This paper proposes an automatic feature fusion strategy AutoAlign V1 for 3D target detection. Use a learnable alignment map to model the mapping relationship between the image and the point cloud, rather than establishing a deterministic correspondence with the camera projection matrix. This graph enables the model to automatically align non-homomorphic features in a dynamic and data-driven manner. Specifically, a cross-attention feature alignment module is designed to adaptively aggregate pixel-level image features of each voxel. In order to enhance the semantic consistency in the feature alignment process, a self-supervised cross-modal feature interaction module is also designed, through which the model can learn feature aggregation guided by instance-level features.
Multimodal 3-D object detectors can be roughly divided into two categories: decision-level fusion and feature-level fusion. The former detects objects in their respective modes and then brings the bounding boxes together in 3D space. Unlike decision-level fusion, feature-level fusion combines multi-modal features into a single representation to detect objects. Therefore, the detector can make full use of features from different modalities during the inference stage. In view of this, more feature-level fusion methods have been developed recently.
A work projects each point to the image plane and obtains the corresponding image features through bilinear interpolation. Although feature aggregation is performed finely at the pixel level, dense patterns in the image domain will be lost due to the sparsity of fusion points, that is, the semantic consistency in image features is destroyed.
Another work uses the initial solution provided by the 3D detector to obtain RoI features of different modalities and connect them together for feature fusion. It maintains semantic consistency by performing instance-level fusion, but suffers from problems such as rough feature aggregation and missing 2D information in the initial proposal generation stage.
To fully utilize these two methods, the authors propose an integrated multi-modal feature fusion framework for 3-D object detection named AutoAlign. It enables the detector to aggregate cross-modal features in an adaptive manner, proving effective in modeling relationships between non-homomorphic representations. At the same time, it exploits pixel-level fine-grained feature aggregation while maintaining semantic consistency through instance-level feature interaction.
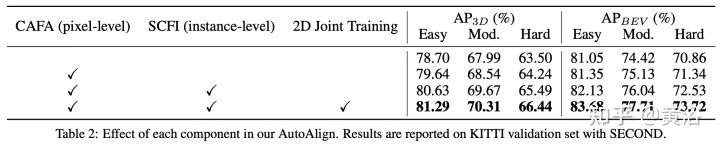
As shown in the figure: feature interaction operates at two levels: (i) pixel-level feature aggregation; (ii) instance-level feature interaction.
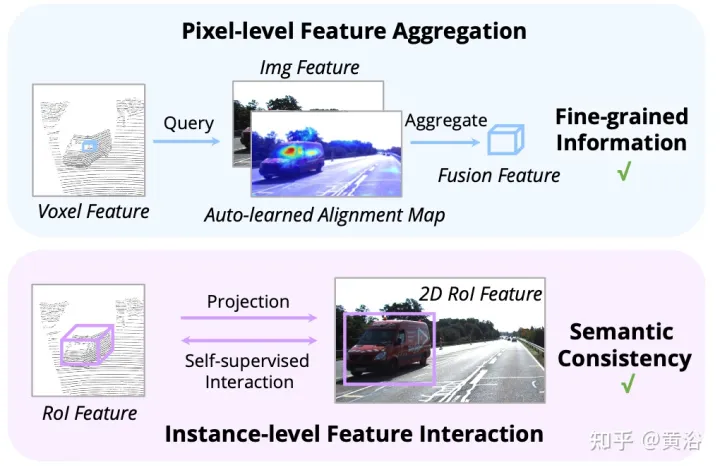
Previous work mainly utilizes camera projection matrices to align image and point features in a deterministic manner. This approach is effective, but may introduce two potential problems: 1) the point cannot obtain a broader view of the image data, and 2) only positional consistency is maintained, while semantic correlation is ignored. Therefore, AutoAlign designed the Cross Attention Feature Alignment (CAFA) module to adaptively align features between non-homomorphic representations. CAFA (Cross-Attention Feature Alignment) The module does not use a one-to-one matching mode, but makes each voxel aware of the entire image and dynamically focuses on the pixel level based on the learnable alignment map. 2D features.
As shown in the figure: AutoAlign consists of two core components. CAFA performs feature aggregation on the image plane and extracts fine-grained pixel-level information of each voxel feature. SCFI (Self-supervised Cross-modal Feature Interaction) Perform cross-modal self-supervision and use instance-level guidance to enhance the semantic consistency of the CAFA module.
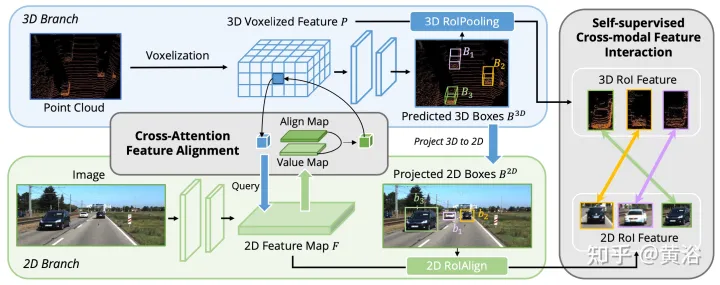
#CAFA is a fine-grained paradigm for aggregating image features. However, it cannot capture instance-level information. In contrast, RoI-based feature fusion maintains the integrity of the object while suffering from rough feature aggregation and missing 2D information during the proposal generation stage.
In order to bridge the gap between pixel-level and instance-level fusion, the Self-supervised Cross-modal Feature Interaction (SCFI) module is introduced to guide the learning of CAFA. It directly utilizes the final predictions of the 3D detector as proposals, leveraging image and point features for accurate proposal generation. Furthermore, instead of concatenating cross-modal features together for further bounding box optimization, similarity constraints are added to cross-modal feature pairs as instance-level guidance for feature alignment.
Given a 2D feature map and corresponding 3D voxelized features, N regional 3D detection frames are randomly sampled, and then projected onto the 2D plane using the camera projection matrix, thereby generating a set of 2D frame pairs. Once the paired boxes are obtained, 2DRoIAlign and 3DRoIPooling are used in 2D and 3D feature spaces to obtain the respective RoI features.
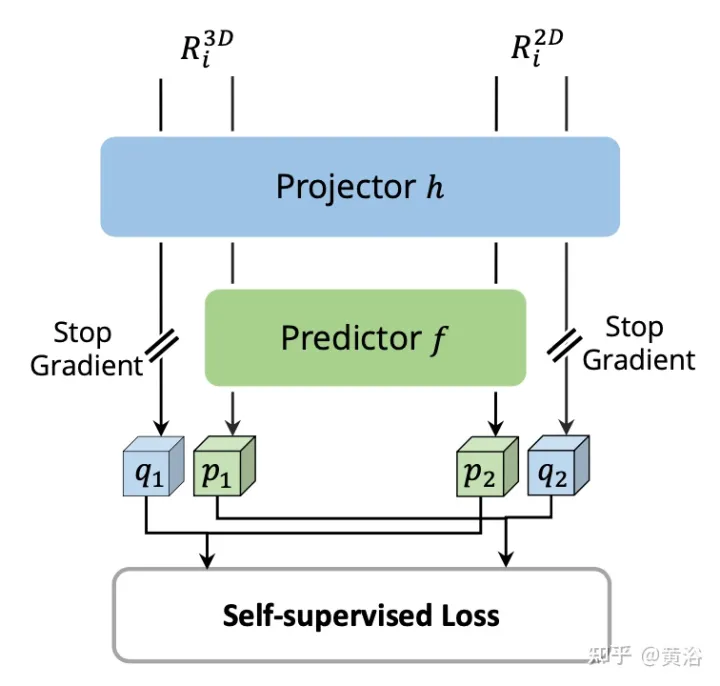
For each pair of 2D and 3D RoI features, perform Self-supervised cross-modal feature interaction (SCFI)## on the features from the image branch and the voxelized features from the point branch. #. Both features are fed into a projection head, which transforms the output of one modality to match the other. Introduce a prediction head with two fully connected layers. As shown in the figure:
 ## AutoAlignV2 comes from "AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection", uploaded in July 2022.
## AutoAlignV2 comes from "AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection", uploaded in July 2022.
 Abstract
Abstract
(Cross-Attention Feature Alignment) module. It focuses on sparse learnable sampling points for cross-modal relationship models, which enhances tolerance to calibration errors and greatly speeds up feature aggregation across modalities. In order to overcome the complex GT-AUG in multi-modal settings, a simple and effective cross-modal enhancement strategy is designed for convex combination based on image patches given depth information. Additionally, through an image-level dropout training scheme, the model is able to perform inference in a dynamic manner. The code will be open source:
https://github.com/zehuichen123/AutoAlignV2.Note: GT-AUG ("
SECOND: Sparsely embedded convolutional detection". Sensors, 2018), a data enhancement methodBackground
Additionally, note that the operational complexity of style is quadratic in image size, so it is impractical to apply query on high-resolution feature maps. This limitation may lead to rough and inaccurate image information, as well as the loss of hierarchical representation brought about by FPN. On the other hand, data augmentation, especially GT-AUG, is a key step for 3D detectors to achieve competitive results. In terms of multimodal approaches, an important issue is how to maintain synchronization between images and point clouds when performing cut and paste operations. MoCa uses labor-intensive mask annotation in the 2D domain to obtain accurate image features. Border-level annotations are also suitable, but require sophisticated point filtering.
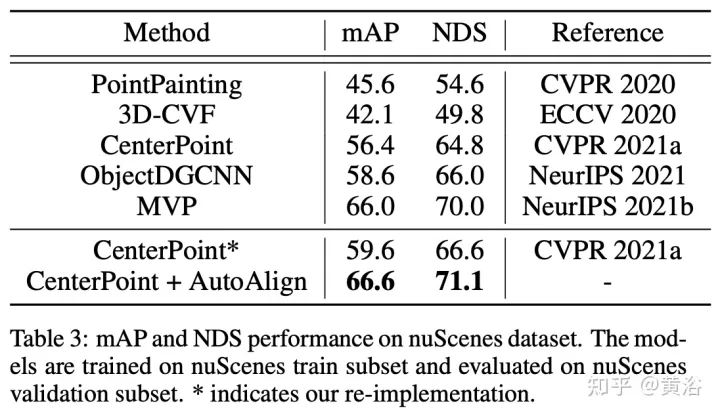
The purpose of AutoAlignV2 is to effectively aggregate image features to further enhance the performance of the 3D object detector. Starting from the basic architecture of AutoAlign: input the paired images into a lightweight backbone network ResNet, and then input it into FPN to obtain the feature map. Then, relevant image information is aggregated through a learnable alignment map to enrich the 3D representation of non-empty voxels in the voxelization stage. Finally, the enhanced features are fed into the subsequent 3D detection pipeline to generate instance predictions.
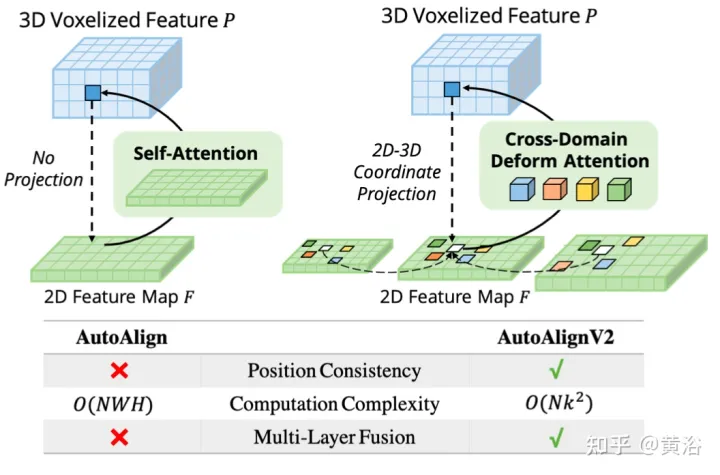
The picture shows the comparison between AutoAlignV1 and AutoAlignV2: AutoAlignV2 prompts the alignment module to have a general mapping relationship guaranteed by a deterministic projection matrix, while retaining the ability to automatically adjust the feature aggregation position. Due to its light computational cost, AutoAlignV2 is able to aggregate multi-layer features of hierarchical image information.
This paradigm can aggregate heterogeneous features in a data-driven manner. However, two major bottlenecks still hinder performance. The first is inefficient feature aggregation. Although global attention maps automatically achieve feature alignment between RGB images and lidar points, the computational cost is high. The second is complex data-enhanced synchronization between images and points. GT-AUG is a key step for high-performance 3D object detectors, but how to maintain semantic consistency between points and images during training remains a complex problem.
As shown in the figure, AutoAlignV2 consists of two parts: Cross-domain DeformCAFA module and Depth-aware GT-AUG data enhancement strategy, and also proposes a Image-level dropout training strategy enables the model to perform inference in a more dynamic way.
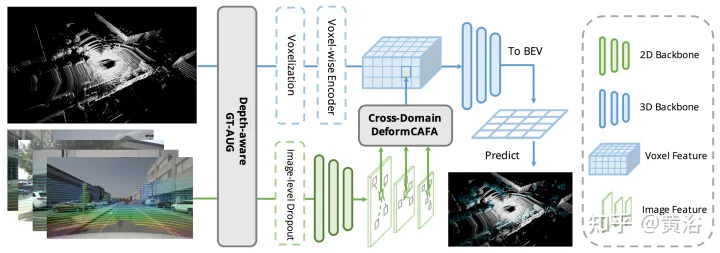
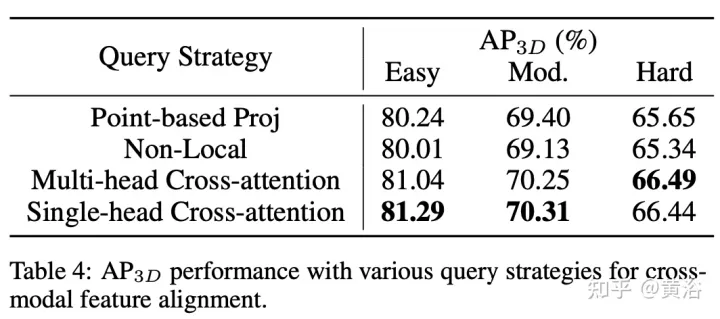
The bottleneck of CAFA is to treat all pixels as possible spatial locations. Based on the properties of 2D images, the most relevant information is mainly located in geometrically adjacent locations. Therefore, it is not necessary to consider all locations, but only a few key point areas. As shown in the figure, a new cross-domain DeformCAFA operation is introduced here, which greatly reduces the sampling candidates and dynamically determines the keypoint area of the image plane for each voxel query feature.
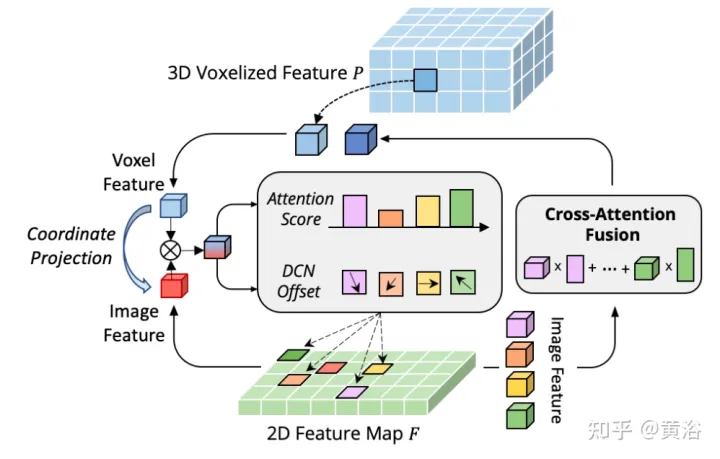
With the help of dynamically generated sampling offsets, DeformCAFA is able to model cross-domain relationships faster than ordinary operations. Able to perform multi-layer feature aggregation, that is, fully utilizing the hierarchical information provided by the FPN layer. Another advantage of DeformCAFA is that it explicitly maintains positional consistency with the camera projection matrix to obtain reference points. Therefore, DeformCAFA can produce semantically and positionally consistent alignments even without adopting the CFSI module proposed in AutoAlign.
Compared with ordinary non-local operations, sparse style DeformCAFA greatly improves efficiency. However, when voxel features are directly applied as tokens to generate attention weights and deformable offsets, the detection performance is barely comparable to, or even worse than, bilinear interpolation. After careful analysis, there is a cross-domain knowledge translation problem in the token generation process. Unlike the original deformation operation, which is usually performed in a unimodal setting, cross-domain attention requires information from both modalities. However, voxel features only consist of spatial domain representations, and it is difficult to perceive information in the image domain. Therefore, it is important to reduce the interaction between different modalities.
Assume that the representation of each target can be unambiguously decomposed into two components: domain-specific information and instance-specific information. The former refers to data related to the representation itself, including the built-in attributes of domain features, while the latter represents the ID information about the target regardless of which domain the target is encoded in.
For most deep learning models, data augmentation is a critical part of achieving competitive results. However, in terms of multi-modal 3D object detection, when point clouds and images are combined together in data augmentation, it is difficult to maintain synchronization between the two, mainly due to object occlusion or viewpoint changes. To solve this problem, a simple yet effective cross-modal data augmentation algorithm named depth-aware GT-AUG is designed. This method abandons the requirement for complex point cloud filtering processes or fine mask annotation of the image domain. Instead, depth information is introduced from 3D object annotations to mix-up image regions.
Specifically, given a virtual target P to be pasted, follow the same 3D implementation of GT-AUG. As for the image domain, it is first sorted from far to near. For each target to be pasted, the same area is cropped from the original image and combined on the target image with a blending ratio of α. The detailed implementation is shown in Algorithm 1 below.

Depth-aware GT-AUG follows the augmentation strategy only in the 3D domain, but simultaneously maintains it through mix-up based cut-and-paste Synchronization of image planes. The key point is that after pasting enhanced patches on the original 2D image, MixUp technology will not completely remove the corresponding information. Instead, it attenuates the compactness of such information relative to depth to ensure that the features of corresponding points exist. Specifically, if a target is occluded n times by other instances, the transparency of the target area decays by a factor (1− α)^n according to its depth order.
As shown in the figure are some enhanced examples:

In fact, image is usually an input option that is not supported by all 3D detection systems. Therefore, a more realistic and applicable multi-modal detection solution should adopt a dynamic fusion approach: when the image is not available, the model detects the target based on the original point cloud; when the image is available, the model performs feature fusion and produces better predictions . To achieve this goal, an image-level dropout training strategy is proposed to randomly dropout the clustered image features at the image level and fill them with zeros during training. As shown in the figure: (a) image fusion; (b) image-level dropout fusion.
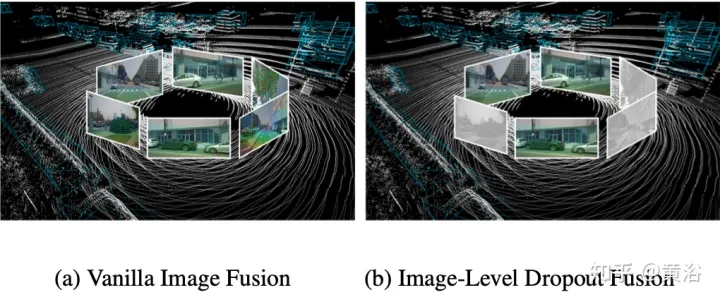
Since image information is intermittently lost, the model should gradually learn to use 2D features as an alternative input.

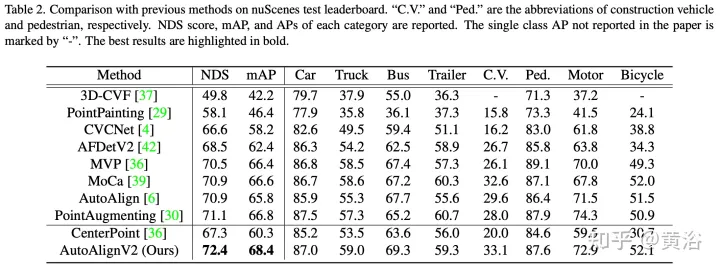


##
The above is the detailed content of Multi-modal fusion BEV target detection method AutoAlign V1 and V2. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



