


According to The Information, former Google artificial intelligence researcher Jacob Devlin recently left the company to join OpenAI, but before that, he revealed that he had warned Sundar Pichai, CEO of Google parent company Alphabet, that Google The chatbot Bard is getting data from ChatGPT in an indirect way.

Do you still remember the incident where Baidu Wenxin was questioned as a "shell"? Recently, foreign media broke the news that Google seems to have done the same.
According to The Information, former Google artificial intelligence researcher Jacob Devlin recently left the company to join OpenAI, but before that, he revealed that he had told Sundar Pichai, CEO of Google parent company Alphabet, Warning, Google's chatbot Bard is getting data from ChatGPT in an indirect way.
According to Devlin’s description, Bard’s development team visited a website called ShareGPT, which shared and published a large number of chat content obtained by users through ChatGPT. This means that Bard used ChatGPT’s ready-made data to “arm” itself, which is equivalent to stealing ChatGPT’s early results.

In response, Google spokesperson Chris Pappas quickly issued a statement to the media, firmly and clearly stating, "Bard did not use any ShareGPT or ChatGPT data for training. ( "Bard is not trained on any data from ShareGPT or ChatGPT.")"
When asked by the media whether Google Bard had ever used ChatGPT data before, Pappas refused to answer, insisting that all he could say was the content of the above statement. .
This incident can’t help but remind people of similar doubts faced by Baidu Wenxinyiyan recently.
In late March, some netizens posted a question questioning how Baidu Wenxin Yiyan Painting is essentially “translating Chinese sentences into English words, using the artificial intelligence Stable Diffusion that has just been open sourced abroad to generate pictures, and then returning them to English. Here you go, I said I drew it myself.”
Examples cited by netizens at the time include inputting instructions into Wen Xinyiyan, asking him to draw “mouse and bus”, and the picture Wenxinyiyan made was “mouse” and bus", because the English words for "mouse" and "bus" are "mouse" and "bus".
Baidu also responded urgently. On March 23, Baidu issued a statement stating that Wenxin Yiyan is completely a large language model developed by Baidu, and the Wenxin graph capability comes from the Wenxin cross-modal large model ERNIE-ViLG. In large model training, Baidu uses global Internet public data, which is in line with industry practice. At the same time, he said that Wen Xinyiyan is constantly learning and growing during the use process, and hopes that everyone will have some confidence in self-developed technology and products.
Subsequently, Baidu corrected similar problems, and users soon discovered that the relevant problems no longer existed, indicating that similar situations were being corrected following user feedback.
Regarding Baidu Wen Xinyiyan’s question, industry experts also said that the use of network public data is a basic operation of the industry. There are a number of intermediate service providers in this industry that specialize in training data for AI applications. The AI data sets they train based on public data annotation are indeed used by multiple AI applications at the same time.
However, the basic operations in the industry may not receive the same understanding and recognition at the consumer level. This time, Google Bard was exposed to use ChatGPT data for training, which also caused an uproar abroad. Many netizens accused Google of stealing OpenAI. results.
Public data on the Internet, including website information, is easily captured by technical means, which is a piece of cake for Google, which is a search engine. In addition, this kind of revelation comes from a recently resigned employee of Google, so the credibility has naturally been greatly improved.
However, some netizens pointed out that after Devlin left the Google AI team, he joined competitor OpenAI. His revelations inevitably involve commercial interests, and the authenticity needs to be further confirmed.
However, in the view of Geek.com, no matter how true such an incident is, it fully demonstrates an "iron rule": the field of AI large models is really lagging behind step by step, and latecomers want to catch up with the first movers. It's a level, it's not easy.
There are many influencing factors behind this, including algorithms, computing power, and the quality of training data. What's more important is that after the first large AI model finds its way to success, it will keep training and evolving, and will not stop and wait for the pursuers.
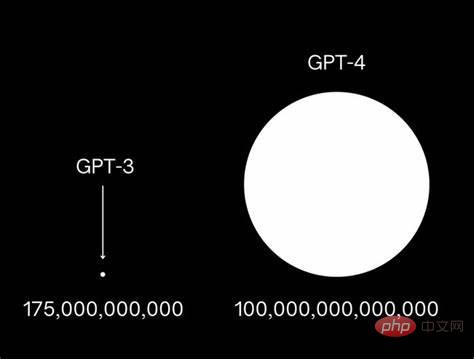
Because of this, OpenAI’s GPT has been quickly upgraded from GPT-3 to the GPT-4 era. This has also triggered a number of celebrities, including Musk, to jointly issue an open letter calling on large companies to suspend large-scale operations. Model development speed to avoid threatening humans.
Robin Li also said in previous interviews with the media that although he performed better in some areas, overall Baidu Wenxinyiyan and OpenAI ChatGPT There is still a gap of one or two months between levels. He also pointed out that when ChatGPT was launched in the early stages, the external feedback was even worse than Wen Xinyiyan’s.
Another bad news for Google Bard is that Google’s Brain artificial intelligence team is rumored to be cooperating with DeepMind, another artificial intelligence company affiliated with Alphabet, to jointly carry out a new project code-named Gemini, with the goal of developing Come up with a product that can compete with OpenAI’s GPT. This seems to imply that Google is not confident in Bard and hopes to develop a more advanced AI large model and create a more advanced AI chat robot.
The above is the detailed content of Google did it too? Bard was exposed to use ChatGPT data for training. The big model is really falling behind step by step.. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



