

This article brings you relevant knowledge aboutRedis, which mainly introduces the relevant content about persistence strategy. RDB persistence refers to the process of storing data in memory within a specified time interval. The data set snapshot is written to the disk. Let's take a look at it. I hope it will be helpful to everyone.

Recommended learning:Redis video tutorial
Redis (Remote Dictionary Server), that is, remote dictionary service, is a Open source in-memory cache data storage service. Written in ANSI C language, it supports network, memory-based and persistent log-type, Key-Value data storage, and provides APIs in multiple languages
Redis is an in-memory database, and the data is Stored in memory, in order to avoid permanent loss of data caused by process exit, the data in Redis needs to be regularly saved from memory to the hard disk in some form (data or command). When Redis restarts next time, use persistent files to achieve data recovery. In addition, persistent files can be copied to a remote location for disaster backup purposes. There are two persistence mechanisms for Redis:
RDB saves the current data to the hard disk, and AOF saves each executed write command to the hard disk (similar to MySQL's Binlog). AOF persistence has better real-time performance, that is, less data is lost when the process exits unexpectedly.
##RDB(RedisData Base)refers to writing a snapshot of the data set in memory to disk within a specified time interval. RDB is a memory snapshot (a binary sequence of memory data (in the form of persistence), each time a snapshot is generated from Redis to fully back up the data.
Advantages: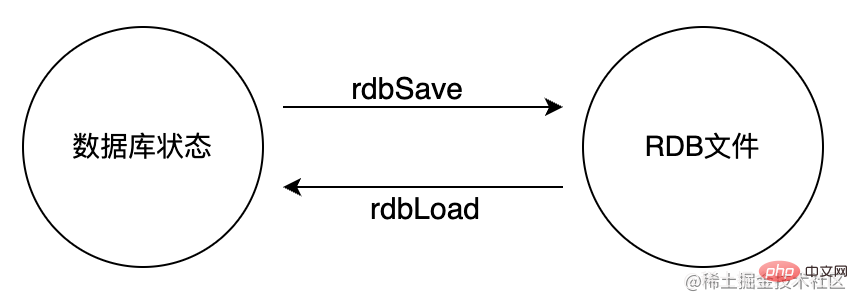
REDISconstant string with a length of 5 bytes.


Manual instruction trigger
Manually trigger RDB persistence using thesavecommand andbgsavecommand, the difference between these two commands is as follows:
save: Execute thesavecommand to block other operations of Redis, which will cause Redis to be unable to Responds to client requests, not recommended.
bgsave: Execute thebgsavecommand, Redis creates a child process in the background, and saves the snapshot asynchronously. At this time, Redis can still respond to the client's request.
Automatic interval saving
By default, Redis saves the database snapshot in a binary file named dump.rdb. Redis can be set to automatically save a data set when the condition "the data set has at least M changes within N seconds" is met. For example, the following settings will cause Redis to automatically save a data set when it meets the condition of "at least 10 keys have been changed within 60 seconds":save 60 10.
The default configuration of Redis is as follows. Automatic saving can be triggered if one of the three settings is met:
save 60 10000 save 300 10 save 900 1
The data structure of the automatic saving configuration
records the server trigger Thesaveparamsattribute of the automaticBGSAVEcondition.
lastsaveAttribute: Record the time when the server last executedSAVEorBGSAVE.
dirtyAttributes: and how many times the server has written since the last time the RDB file was saved.
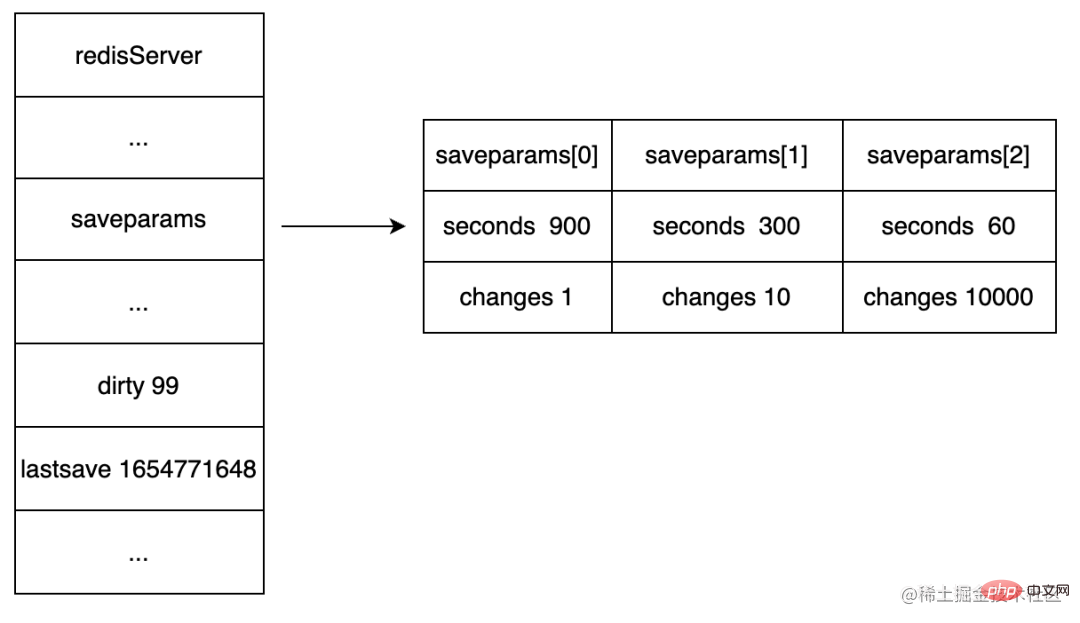
When backing up the RDB persistence scheme, Redis will fork a separate child process for persistence and write the data to a temporary file, replacing the old RDB file after persistence is complete. During the entire persistence process, the main process (the process that provides services to the client) does not participate in IO operations, which ensures the high performance of the Redis service. The RDB persistence mechanism is suitable for applications that do not have high requirements for data integrity but pursue efficient recovery. Scenes. The following shows the RDB persistence process:
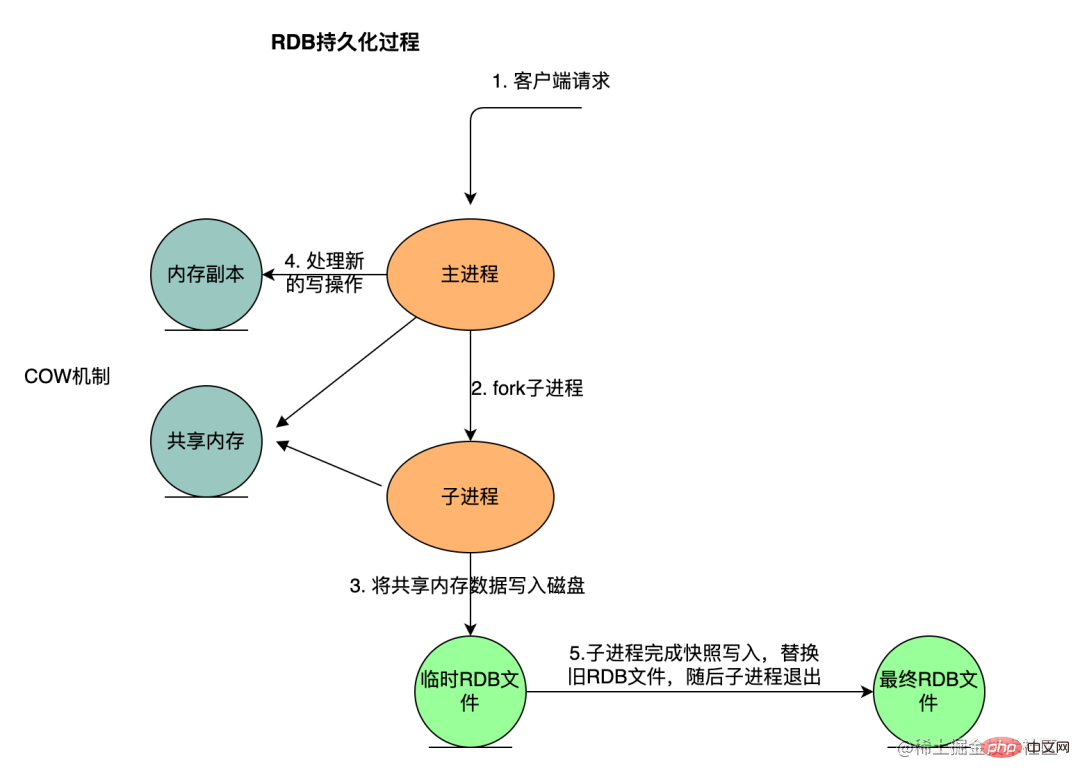
The key execution steps are as follows
The Redis parent process first determines: whether save is currently being executed. Or the child process of bgsave/bgrewriteaof, if it is being executed, the bgsave command will return directly. The child processes of bgsave/bgrewriteaof cannot be executed at the same time, mainly due to performance considerations: two concurrent child processes perform a large number of disk write operations at the same time, which may cause serious performance problems.
In the step of generating RDB files, how to deal with data inconsistencies during the process of synchronizing to disk and continuous writing? Will there be any business impact when generating snapshot RDB files?
As mentioned above, during the RDB persistence process, the main process will fork a sub-process to be responsible for RDB backup. This is simple Let me introduce fork:
In Redis, RDB persistence makes full use of this technology. Redis calls the glibc function to fork a child process during persistence, and is fully responsible for the persistence work, so that the parent process can still continue. Provide services to clients. The child process of fork initially shares the same memory with the parent process (the main process of Redis); when the client requests to modify the data in the memory during the persistence process, the COW (Copy On Write) mechanism will be used to modify the data in the memory. The data segment page is separated, that is, a piece of memory is copied for the main process to modify.
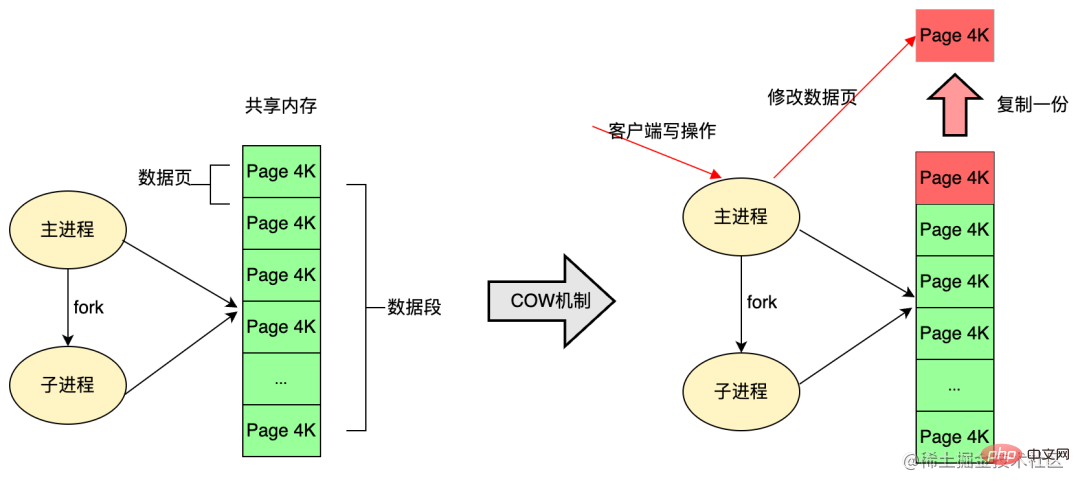
The child process created through fork can obtain exactly the same memory space as the parent process. The modification of the memory by the parent process is invisible to the child process, and the two will not. Mutual influence;
When creating a child process through fork, it will not immediately trigger the copy of a large amount of memory. Instead, COW (Copy On Write) is used. The kernel only creates virtual space structures for the newly generated child processes. They copy the virtual actual structures of the parent process, but do not allocate physical memory for these segments. They share the physical space of the parent process. When the parent and child processes change the corresponding segments, When the behavior occurs, physical space is allocated for the corresponding segment of the child process;
AOF(Append Only File)是把所有对内存进行修改的指令(写操作)以独立日志文件的方式进行记录,重启时通过执行 AOF 文件中的 Redis 命令来恢复数据。类似MySql bin-log 原理。AOF 能够解决数据持久化实时性问题,是现在 Redis 持久化机制中主流的持久化方案。
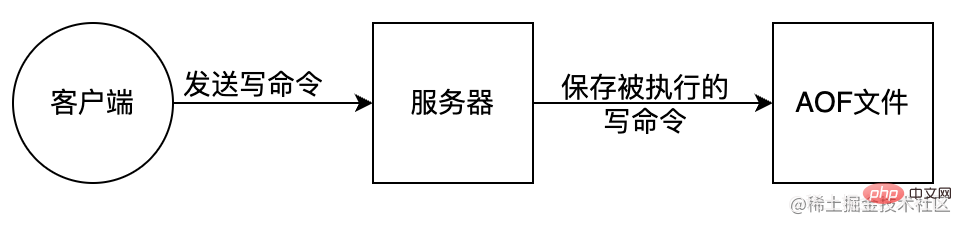
优点:
缺点:
被写入 AOF 文件的所有命令都是以 RESP 格式保存的,是纯文本格式保存在 AOF 文件中。
Redis 客户端和服务端之间使用一种名为
RESP(REdis Serialization Protocol)的二进制安全文本协议进行通信。
下面以一个简单的 SET 命令进行举例:
redis> SET mykey "hello" //客户端命令OK
客户端封装为以下格式(每行用\r\n分隔)
*3$3SET$5mykey$5hello
AOF 文件中记录的文本内容如下
*2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n //多出一个SELECT 0 命令,用于指定数据库,为系统自动添加 *3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$5\r\nhello\r\n
AOF 持久化方案进行备份时,客户端所有请求的写命令都会被追加到 AOF 缓冲区中,缓冲区中的数据会根据 Redis 配置文件中配置的同步策略来同步到磁盘上的 AOF 文件中,追加保存每次写的操作到文件末尾。同时当 AOF 的文件达到重写策略配置的阈值时,Redis 会对 AOF 日志文件进行重写,给 AOF 日志文件瘦身。Redis 服务重启的时候,通过加载 AOF 日志文件来恢复数据。
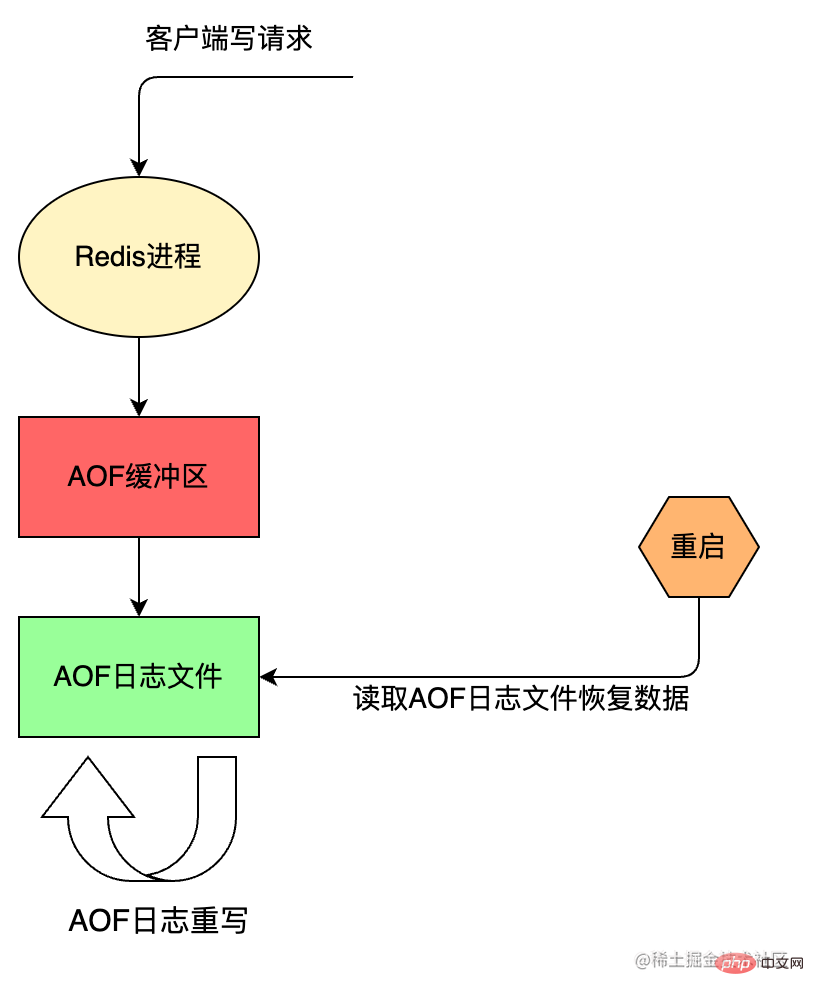
AOF 的执行流程包括:
命令追加(append)
Redis 先将写命令追加到缓冲区 aof_buf,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘 IO 成为 Redis 负载的瓶颈。
struct redisServer { //其他域... sds aof_buf; // sds类似于Java中的String //其他域...}
文件写入(write)和文件同步(sync)
根据不同的同步策略将 aof_buf 中的内容同步到硬盘;
Linux 操作系统中为了提升性能,使用了页缓存(page cache)。当我们将 aof_buf 的内容写到磁盘上时,此时数据并没有真正的落盘,而是在 page cache 中,为了将 page cache 中的数据真正落盘,需要执行 fsync / fdatasync 命令来强制刷盘。这边的文件同步做的就是刷盘操作,或者叫文件刷盘可能更容易理解一些。
AOF 缓存区的同步文件策略由参数 appendfsync 控制,有三种同步策略,各个值的含义如下:
always:命令写入 aof_buf 后立即调用系统 write 操作和系统 fsync 操作同步到 AOF 文件,fsync 完成后线程返回。这种情况下,每次有写命令都要同步到 AOF 文件,硬盘 IO 成为性能瓶颈,Redis 只能支持大约几百TPS写入,严重降低了 Redis 的性能;即便是使用固态硬盘(SSD),每秒大约也只能处理几万个命令,而且会大大降低 SSD 的寿命。可靠性较高,数据基本不丢失。no:命令写入 aof_buf 后调用系统 write 操作,不对 AOF 文件做 fsync 同步;同步由操作系统负责,通常同步周期为30秒。这种情况下,文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证。everysec:命令写入 aof_buf 后调用系统 write 操作,write 完成后线程返回;fsync 同步文件操作由专门的线程每秒调用一次。everysec 是前述两种策略的折中,是性能和数据安全性的平衡,因此是 Redis 的默认配置,也是我们推荐的配置。文件重写(rewrite)
定期重写 AOF 文件,达到压缩的目的。
AOF 重写是 AOF 持久化的一个机制,用来压缩 AOF 文件,通过 fork 一个子进程,重新写一个新的 AOF 文件,该次重写不是读取旧的 AOF 文件进行复制,而是读取内存中的Redis数据库,重写一份 AOF 文件,有点类似于 RDB 的快照方式。
文件重写之所以能够压缩 AOF 文件,原因在于:
前面提到 AOF 的缺点时,说过 AOF 属于日志追加的形式来存储 Redis 的写指令,这会导致大量冗余的指令存储,从而使得 AOF 日志文件非常庞大,比如同一个 key 被写了 10000 次,最后却被删除了,这种情况不仅占内存,也会导致恢复的时候非常缓慢,因此 Redis 提供重写机制来解决这个问题。Redis 的 AOF 持久化机制执行重写后,保存的只是恢复数据的最小指令集,我们如果想手动触发可以使用如下指令:
bgrewriteaof
文件重写时机
相关参数:
同时满足下面两个条件,则触发 AOF 重写机制:
AOF重写流程如下:
bgrewriteaof 触发重写,判断是否存在 bgsave 或者 bgrewriteaof 正在执行,存在则等待其执行结束再执行
子进程遍历 Redis 内存快照中数据写入临时 AOF 文件,同时会将新的写指令写入 aof_buf 和 aof_rewrite_buf 两个重写缓冲区,前者是为了写回旧的 AOF 文件,后者是为了后续刷新到临时 AOF 文件中,防止快照内存遍历时新的写入操作丢失
子进程结束临时 AOF 文件写入后,通知主进程
主进程会将上面 3 中的 aof_rewirte_buf 缓冲区中的数据写入到子进程生成的临时 AOF 文件中
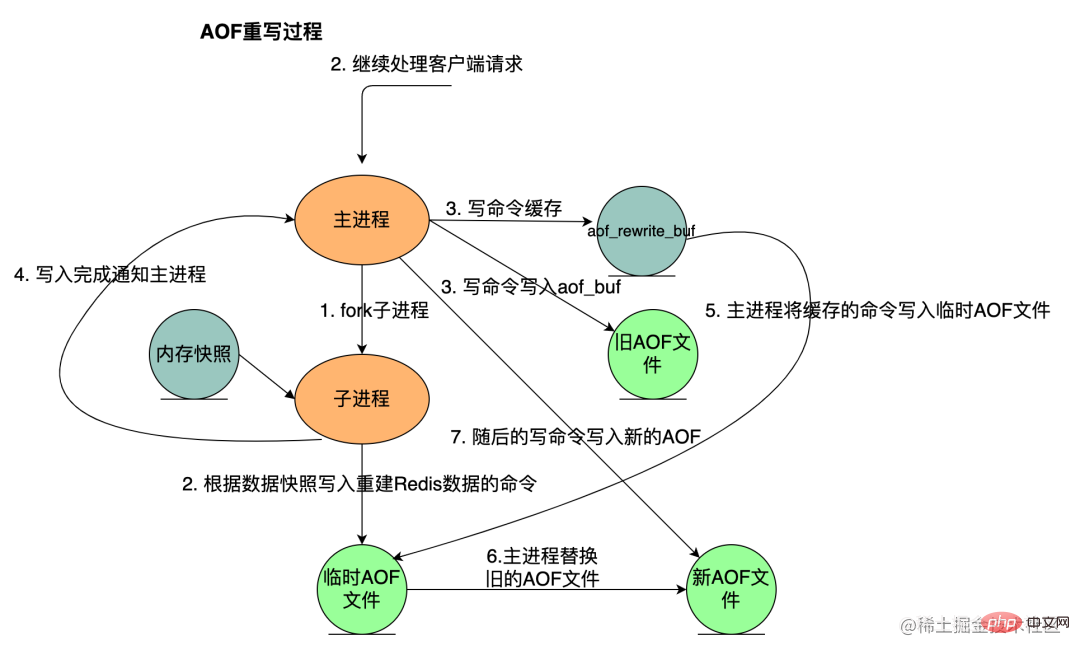
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序会检查集合元素数量是否超过 REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值,如果超过了,则会使用多个命令来记录,而不单单使用一条命令。
Redis 2.9版本中该常量为64,如果一个命令的集合键包含超过了64个元素,重写程序会拆成多个命令。

AOF重写是一个有歧义的名字,该功能是通过直接读取数据库的键值对实现的,程序无需对现有AOF文件进行任何读入、分析或者写入操作。
Redis 为什么考虑使用 AOF 而不是 WAL 呢?
很多数据库都是采用的 Write Ahead Log(WAL)写前日志,其特点就是先把修改的数据记录到日志中,再进行写数据的提交,可以方便通过日志进行数据恢复。
但是 Redis 采用的却是 AOF(Append Only File)写后日志,特点就是先执行写命令,把数据写入内存中,再记录日志。
If you let the system execute the command first, only the command that can be executed successfully will be recorded in the log. Therefore, Redis uses post-write logging to avoid recording incorrect commands.
Another reason is that AOF only records the log after the command is executed, so it will not block the current write operation.
In Redis with version number greater than or equal to 2.4, BGREWRITEAOF cannot be executed during the execution of BGSAVE. On the other hand, BGSAVE cannot be executed during the execution of BGREWRITEAOF. This prevents two Redis background processes from doing heavy I/O operations on the disk at the same time.
If BGSAVE is executing and the user explicitly calls the BGREWRITEAOF command, the server will reply with an OK status to the user and inform the user that BGREWRITEAOF has been scheduled for execution: BGREWRITEAOF will officially start once BGSAVE is completed.
When Redis starts, if both RDB persistence and AOF persistence are turned on, the program will give priority to using AOF files to restore the data set, because the data saved in AOF files is usually the most complete.
After Redis 4.0, most usage scenarios will not use RDB or AOF alone as the persistence mechanism, but will take into account both. Advantages of mixed use. The reason is that although RDB is fast, it will lose a lot of data and cannot guarantee data integrity; although AOF can ensure data integrity as much as possible, its performance is indeed a criticism, such as replaying and recovering data.
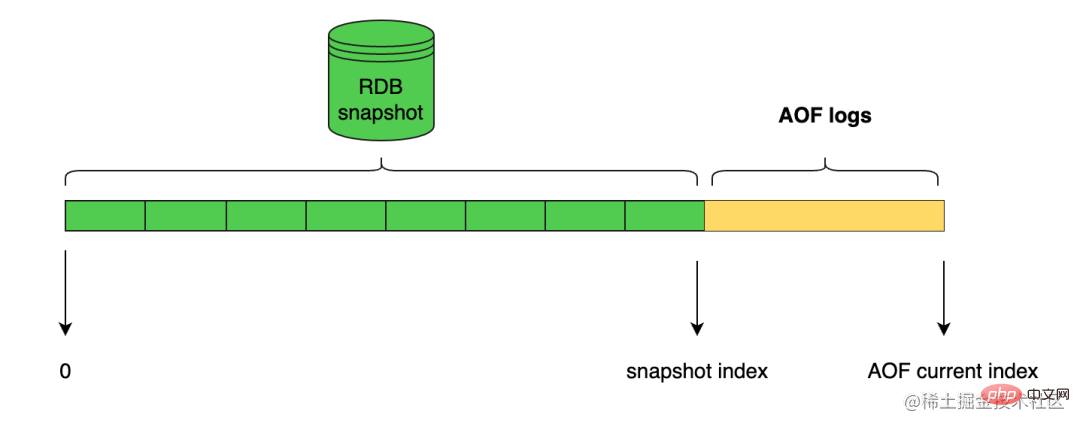
Redis has introduced the RDB-AOF hybrid persistence mode since version 4.0. This mode is built based on the AOF persistence mode. Hybrid persistence passesaof-use-rdb-preamble yesTurn on.
Then when the Redis server performs the AOF rewrite operation, it will generate the corresponding RDB data based on the current status of the database just like executing the BGSAVE command, and write these data into the newly created AOF file. As for Redis commands executed after AOF rewriting starts will continue to be appended to the end of the new AOF file in the form of protocol text, that is, after the existing RDB data.
In other words, after the RDB-AOF hybrid persistence function is turned on, the AOF file generated by the server will be composed of two parts. The data at the beginning of the AOF file is the RDB format data, and the RDB data that follows What follows is the data in AOF format.
When a Redis server that supports RDB-AOF hybrid persistence mode starts and loads an AOF file, it will check whether the beginning of the AOF file contains RDB format content.
The log file structure is as follows:
Finally To sum up the two, which one is better?
Recommended learning:Redis video tutorial
The above is the detailed content of A brief analysis of Redis persistence strategy. For more information, please follow other related articles on the PHP Chinese website!
 Commonly used database software
Commonly used database software What are the in-memory databases?
What are the in-memory databases? Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis? How to use redis as a cache server
How to use redis as a cache server How redis solves data consistency
How redis solves data consistency How do mysql and redis ensure double-write consistency?
How do mysql and redis ensure double-write consistency? What data does redis cache generally store?
What data does redis cache generally store? What are the 8 data types of redis
What are the 8 data types of redis






















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



