


This article brings you relevant knowledge aboutjavascript. It mainly introduces related issues about the JavaScript operating mechanism and principles, including parsing engines and other contents. Let’s take a look at it together. I hope everyone has to help.

[Related recommendations:javascript video tutorial,web front-end]
I have been writing js for more than two years , I have never understood its operating mechanism and principles very well. Today I specially recorded the theories of the masters and my own summary below:
Simply put, a JavaScript parsing engine is a program that can "read" JavaScript code and accurately provide the results of the code execution.
For example, when you write a piece of code like var a = 1 1;, what the JavaScript engine does is to understand (parse) your code and change the value of a to 2.
Those who have studied the principles of compilation know that for static languages (such as Java, C, C), the one that handles the above things is called a compiler (Compiler), and correspondingly for dynamic languages such as JavaScript, it is called a compiler. Interpreter. The difference between the two can be summarized in one sentence: the compiler compiles the source code into another type of code (such as machine code, or bytecode), while the interpreter directly parses and outputs the code running results. For example, Firebug's console is a JavaScript interpreter.
However, it is now difficult to define whether the JavaScript engine is an interpreter or a compiler, because, for example, V8 (Chrome's JS engine) actually uses the code to improve the running performance of JS. Before running, JS will be compiled into native machine code (native machine code), and then the machine code will be executed (this will be much faster).
The JavaScript engine is a program, and the JavaScript code we write is also a program. How to make the program understand the program? This requires defining rules. For example, the previously mentioned var a = 1 1;, it means:
The var on the left represents a declaration, which declares the variable a.
The one on the right represents the difference between 1 and 1 Do addition
The equal sign in the middle indicates that this is an assignment statement
The semicolon at the end indicates the end of the statement
These are the rules. With it, there is a standard of measurement, and the JavaScript engine will JavaScript code can be parsed according to this standard. Then the ECMAScript here defines these rules. Among them, the document ECMAScript 262 defines a complete set of standards for the JavaScript language. These include:
var, if, else, break, continue, etc. are JavaScript keywords
abstract, int, long, etc. are JavaScript reserved words
How to count it as a number and how to count it as a string Etc.
Defines operators ( , -, >, Defines JavaScript syntax
Defines standard processing algorithms for expressions, statements, etc., such as when encountering == How to deal with
⋯⋯
The standard JavaScript engine will be implemented according to this set of documents. Note that the standard is emphasized here, because there are also implementations that do not follow the standard, such as IE's JS engine. This is why JavaScript has compatibility issues. As for why IE's JS engine is not implemented in accordance with standards, it comes to the browser war. I won't go into details here. Google it yourself.
So, to put it simply, ECMAScript defines the standard of the language, and the JavaScript engine implements it according to it. This is the relationship between the two.
Simply put, the JavaScript engine is one of the components of the browser. Because the browser has to do a lot of other things, such as parsing pages, rendering pages, cookie management, history records, etc. Well, since it is a component, JavaScript engines are generally developed by browser developers themselves. For example: Chakra of IE9, TraceMonkey of Firefox, V8 of Chrome, etc.
It can also be seen that different browsers use different JavaScript engines. So, all we can say is which JavaScript engine to get a deeper understanding of.
One of the major features of the JavaScript language is that it is single-threaded, that is to say, it can only do one thing at the same time. So why can't JavaScript have multiple threads? This can improve efficiency.
The single thread of JavaScript is related to its purpose. As a browser scripting language, JavaScript's main purpose is to interact with users and manipulate the DOM. This determines that it can only be single-threaded, otherwise it will cause very complex synchronization problems. For example, suppose JavaScript has two threads at the same time. One thread adds content to a certain DOM node, and the other thread deletes the node. In this case, which thread should the browser use?
So, in order to avoid complexity, JavaScript has been single-threaded since its birth. This has become the core feature of this language and will not change in the future.
In order to take advantage of the computing power of multi-core CPUs, HTML5 proposes the Web Worker standard, which allows JavaScript scripts to create multiple threads, but the child threads are completely controlled by the main thread and must not operate the DOM. Therefore, this new standard does not change the single-threaded nature of JavaScript.
A process is the smallest unit of CPU resource allocation, and a process can contain multiple threads. Browsers are multi-process, and each opened browser window is a process.
Thread is the smallest unit of CPU scheduling. The memory space of the program is shared between threads in the same process.
The process can be regarded as a warehouse, and the thread is a truck that can be transported. Each warehouse has its own multiple trucks to serve the warehouse (carrying goods). Each warehouse can be pulled by multiple vehicles at the same time. Cargo, but each vehicle can only do one thing at a time, which is to transport this cargo.
Core point:
The process is the smallest unit of CPU resource allocation (the smallest unit that can own resources and run independently)
The thread is the CPU The smallest unit of scheduling (a thread is a program running unit based on a process, and there can be multiple threads in a process)
Different processes can also communicate, but at a higher cost.
Browsers are multi-process
After understanding the difference between processes and threads, let’s understand the browser to a certain extent: (Let’s look at the simplified understanding first)
The reason why the browser can run is because the system allocates resources (cpu, memory) to its process
To understand simply, every time you open a Tab page, it is equivalent to creating a A separate browser process.
Take Chrome as an example. It has multiple tab pages, and then you can see multiple processes in Chrome's task manager (each Tab page has an independent process, and a main process. ), which can also be seen in the Windows Task Manager.
Note: The browser should also have its own optimization mechanism here. Sometimes after opening multiple tab pages, you can see in the Chrome Task Manager that some processes are merged (so each Tab label corresponds to A process is not necessarily absolute)
After knowing that the browser is a multi-process, let’s take a look at what processes it contains: (To simplify understanding, Only the main processes are listed)
(1) Browser process: There is only one main process of the browser (responsible for coordination and control). Role:
(2) Third-party plug-in process: Each type of plug-in corresponds to a process, which is only created when the plug-in is used
(3) GPU process: up to One, used for 3D drawing, etc.
(4) Browser rendering process (browser kernel, Renderer process, internally multi-threaded): By default, each Tab page has one process and does not affect each other. The main functions are: page rendering, script execution, event processing, etc.
Enhance memory: opening a web page in the browser is equivalent to starting a new process (the process has its own multi-threading)
Of course, browsers sometimes merge multiple processes (for example, after opening multiple blank tabs, you will find that multiple blank tabs are merged into one process)
Compared with single-process browsers, multi-process browsers have the following advantages:
Simple understanding:
If the browser is a single process, then the crash of a certain tab page will affect the entire browser, and the experience will be poor; similarly, if it is a single process, the crash of the plug-in will also affect the entire browser.
Of course, memory and other resource consumption will also be greater, which means that space is exchanged for time. No matter how large the memory is, it is not enough for Chrome. The memory leak problem has been improved a bit now. It is only an improvement, and it will also lead to increased power consumption.
Here comes the key point. We can see that there are so many processes mentioned above. So, for ordinary front-end operations, what is ultimately needed is what? The answer is the rendering process.
It can be understood that the rendering of the page, the execution of JS, and the event loop are all performed within this process. Next, focus on analyzing this process
Please keep in mind that the browser's rendering process is multi-threaded (the JS engine is single-threaded)
Then let's take a look at it Which threads are included (list some main resident threads):
Seeing this, first of all, you should have a certain understanding of the processes and threads in the browser, then Next, let’s talk about how the browser’s Browser process (control process) communicates with the kernel. After understanding this, we can connect this part of knowledge together to have a complete concept from beginning to end.
If you open the task manager and then open a browser, you can see: two processes appear in the task manager (one is the main control process, and the other is the rendering process that opens the Tab page) , and then under this premise, let’s take a look at the entire process: (It’s a lot simplified)
Here is a simple drawing Picture: (very simplified)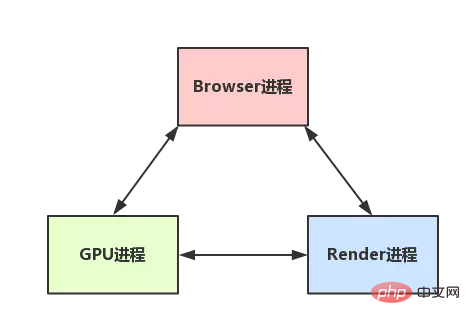
At this point, we have already learned about the operation of the browser An overall concept has been developed. Next, let’s briefly sort out some concepts
Since JavaScript can manipulate the DOM, if you modify the properties of these elements and render the interface at the same time (that is, the JS thread and the UI thread run at the same time), then the rendering thread before and after The obtained element data may be inconsistent.
Therefore, in order to prevent unexpected rendering results, the browser sets the GUI rendering thread and the JS engine to have a mutually exclusive relationship. When the JS engine is executed, the GUI thread will be suspended, and the GUI updates will be saved in Wait in a queue to be executed immediately when the JS engine thread is idle.
From the above mutually exclusive relationship, it can be deduced that JS will block the page if the execution time is too long.
For example, assume that the JS engine is performing a huge amount of calculations. Even if the GUI is updated at this time, it will be saved in the queue and wait for the JS engine to be idle for execution. Then, due to the huge amount of calculations, the JS engine is likely to be idle for a long, long time, and naturally it will feel extremely huge.
Therefore, try to avoid JS execution taking too long, which will cause the rendering of the page to be inconsistent, leading to the feeling that the page rendering and loading are blocked.
To solve this problem, in addition to placing the calculation on the backend, if it cannot be avoided and the huge calculation is related to the UI, then my idea is to use setTimeout to divide the task and give a little free time in the middle Time to let the JS engine handle the UI so that the page does not freeze directly.
If you decide directly on the minimum required HTML5 version, you can take a look at the WebWorker below.
As mentioned in the previous article, the JS engine is single-threaded, and if the JS execution time is too long, it will block the page, so the JS will really Is it powerless for CPU-intensive calculations?
So, Web Worker was later supported in HTML5.
MDN's official explanation is:
Web Worker provides a simple way to run scripts in a background thread for web content.
Threads can perform tasks without interfering with the user interface. A worker is an object created using a constructor (Worker()) that runs a named JavaScript file (this file contains the code that will be run in the worker thread ).
Workers run in another global context, different from the current window.
Therefore, using the window shortcut to obtain the current global scope (instead of self) will return an error within a Worker
Understand it this way:
When creating a Worker, JS The engine applies to the browser to open a sub-thread (the sub-thread is opened by the browser, is completely controlled by the main thread, and cannot operate the DOM)
The JS engine thread and the worker thread communicate through a specific method (postMessage API, which needs to be passed Serialize objects to interact with threads for specific data)
Therefore, if there is very time-consuming work, please open a separate Worker thread, so that no matter how earth-shaking it is, it will not affect the JS engine main thread, just wait for the results to be calculated Finally, just communicate the result to the main thread, perfect!
And please note that the JS engine is single-threaded. The essence of this has not changed. The Worker can be understood as a plug-in opened by the browser for the JS engine. , specially designed to solve those large computing problems.
Others, the detailed explanation of Worker is beyond the scope of this article, so I won’t go into details.
Now that we are here, let’s mention SharedWorker again (to avoid confusing these two concepts later)
WebWorker only Belongs to a certain page and will not be shared with the Render process (browser kernel process) of other pages
So Chrome creates a new thread in the Render process (each Tab page is a Render process) to run the JavaScript in the Worker program.
SharedWorker is shared by all pages of the browser and cannot be implemented in the same way as Worker because it is not affiliated with a Render process and can be shared by multiple Render processes
Therefore, the Chrome browser creates a separate SharedWorker A process to run a JavaScript program, there is only one SharedWorker process for each same JavaScript in the browser, no matter how many times it is created.
Seeing this, it should be easy to understand. Essentially, it is the difference between processes and threads. SharedWorker is managed by an independent process, and WebWorker is just a thread under the Render process.
Supplement the browser rendering process (simple version)
In order to simplify understanding, the preliminary work is omitted directly:
Browse The browser inputs the URL, the browser main process takes over, opens a download thread, and then makes an http request (omitting DNS query, IP addressing, etc.), then waits for the response, obtains the content, and then transfers the content to the Renderer process through the RendererHost interface.
The browser rendering process begins
After the browser kernel gets the content, rendering can be roughly divided into the following steps:
Parse html and build a dom tree
Parse css and build a render tree (parse the CSS code into a tree-shaped data structure, and then combine it with the DOM to merge into a render tree)
Layout the render tree (Layout/reflow), responsible for each Calculation of element size and position
Draw render tree (paint) and draw page pixel information
The browser will send the information of each layer to the GPU, and the GPU will composite each layer and display it on the screen.
All detailed steps have been omitted. After rendering is completed, it is the load event, and then it is your own JS logic processing.
Since some detailed steps have been omitted, let me mention some details that may need attention.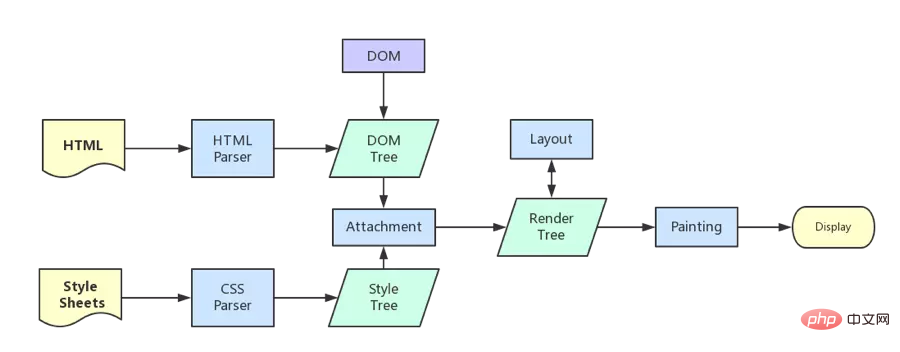
As mentioned above, the load event will be triggered after rendering is completed, so can you distinguish the sequence of load event and DOMContentLoaded event? ?
It's very simple, just know their definitions:
When the DOMContentLoaded event is triggered, only when the DOM is loaded, excluding style sheets, pictures, async scripts, etc.
When the onload event is triggered, all DOM, style sheets, scripts, and images on the page have been loaded, that is, rendered.
Therefore, the order is: DOMContentLoaded -> load
What we are talking about here is the situation where css is introduced in the header
First of all, we all know that css is downloaded asynchronously by a separate download thread.
Then let’s talk about the following phenomena:
This may also be an optimization mechanism of the browser. Because when you load css, you may modify the style of the DOM node below. If the css loading does not block the rendering of the render tree, then after the css is loaded, the render tree may have to be redrawn or reflowed, which causes some problems. There is no necessary loss.
So just parse the structure of the DOM tree first, complete the work that can be done, and then wait for your css to be loaded, and then render the render tree according to the final style. In terms of performance, this approach It will indeed be better.
The concept of composite is mentioned in the rendering step.
It can be simply understood that the layers rendered by the browser generally include two categories: ordinary layers and composite layers
First of all, the ordinary document stream can be understood as a composite layer (This is called the default composite layer. No matter how many elements are added to it, they are actually in the same composite layer)
Secondly, the absolute layout (the same is true for fixed), although it can be separated from the ordinary document flow, it Still belongs to the default composite layer.
Then, you can declare a new composite layer through hardware acceleration, which will allocate resources separately (of course it will also be separated from the ordinary document flow, so that no matter how the composite layer changes, It will not affect the reflow redraw in the default composite layer)
It can be understood simply: in the GPU, each composite layer is drawn separately, so it does not affect each other, which is why some scene hardware acceleration effects The first level is great
You can see it in Chrome DevTools --> More Tools --> Rendering --> Layer borders. The yellow one is the composite layer information
Turn this element into a composite layer, which is the legendary hardware acceleration technology
The most commonly used method: translate3d, translateZ
opacity attribute/transition Animation (the composition layer will be created during the execution of the animation, and the element will return to its previous state after the animation has not started or ended)
will-chang attribute (this is relatively remote), generally used in conjunction with opacity and translate, its function It is to tell the browser in advance that changes are to be made, so that the browser will start to do some optimization work (it is best to release this after use)
video, iframe, canvas, webgl and other elements
Others, such as the previous flash plug-in
The difference between absolute and hardware acceleration
It can be seen that although absolute can be separated from the ordinary document flow, it cannot be separated from the default composite layer. Therefore, even if the information in absolute changes, it will not change the render tree in the ordinary document flow. However, when the browser finally draws, the entire composite layer is drawn, so changes in the information in absolute will still affect the drawing of the entire composite layer. (The browser will redraw it. If there is a lot of content in the composite layer, the drawing information brought by absolute will change too much, and the resource consumption will be very serious)
And the hardware acceleration is directly in another composite layer ( Start from scratch), so its information changes will not affect the default composite layer (of course, it will definitely affect its own composite layer internally), but only trigger the final composition (output view)
Generally, an element will become a composite layer after hardware acceleration is turned on, which can be independent of the ordinary document flow. After modification, it can avoid redrawing of the entire page and improve performance, but try to Do not use a large number of composite layers, otherwise the page will become stuck due to excessive resource consumption.
When using hardware acceleration, use index as much as possible to prevent By default, the browser creates composite layer rendering for subsequent elements. The specific principle is as follows: In webkit CSS3, if this element has hardware acceleration added and the index level is relatively low, then other elements behind this element will (If the level is higher than this element, or the same, and the releative or absolute attributes are the same), it will become a composite layer rendering by default. If it is not handled properly, it will greatly affect the performance.
Simple understanding, in fact, it can It is considered to be an implicit composition concept: if a is a composite layer and b is on top of a, then b will also be implicitly converted into a composite layer. This requires special attention.
Talk about the running mechanism of JS from EventLoopNote that we do not talk about concepts such as executable context, VO, scop chain (these can be organized into another article). Here we mainly talk about how JS code is executed in combination with Event Loop.
The prerequisite for reading this part is that you already know that the JS engine is single-threaded, and several concepts mentioned above will be used here:
JS engine thread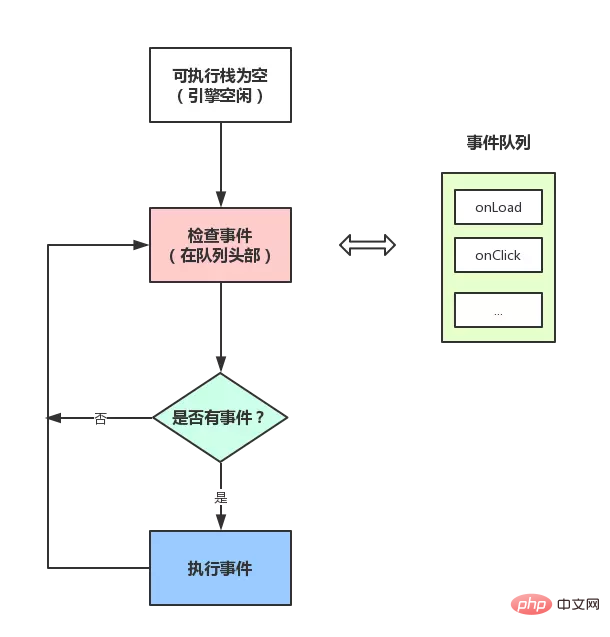 After seeing this, you should be able to understand: Why are events pushed by setTimeout sometimes not executed on time? Because the main thread may not be idle yet and is executing other code when it is pushed into the event list, so there will naturally be errors.
After seeing this, you should be able to understand: Why are events pushed by setTimeout sometimes not executed on time? Because the main thread may not be idle yet and is executing other code when it is pushed into the event list, so there will naturally be errors.
The event loop mechanism is further supplemented
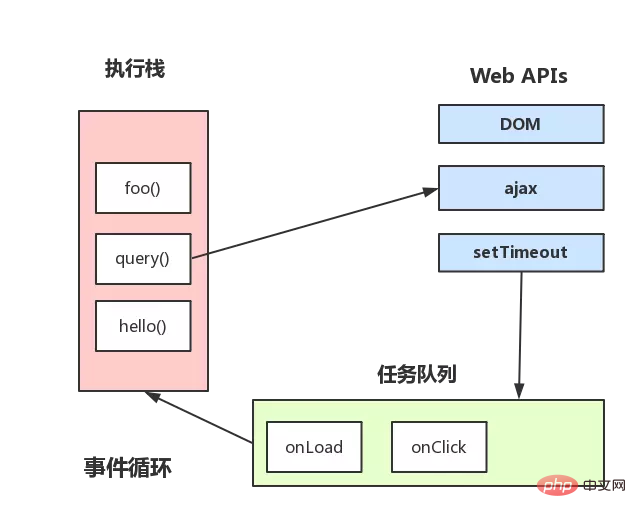 The above figure roughly describes:
The above figure roughly describes:
Let’s talk about timers separately
But there are some hidden details in the event, for example, after calling setTimeout, How to wait for a specific time before adding to the event queue?
Is it detected by the JS engine? Of course not. It is controlled by the timer thread (because the JS engine itself is too busy and has no time to spare)
Why do we need a separate timer thread? Because the JavaScript engine is single-threaded, if it is in a blocked thread state, it will affect the accuracy of timing, so it is necessary to open a separate thread for timing.
When will the timer thread be used? When using setTimeout or setInterval, it requires the timer thread to time, and after the time is completed, the specific event will be pushed into the event queue.
setTimeout instead of setInterval
Because each time setTimeout is executed, it will be executed, and then setTimeout will continue after a period of execution. There will be errors in the middle (the error is related to the code execution time)
And setInterval It is to push an event accurately every time. However, the actual execution time of the event may not be accurate. It is possible that the next event will come before the event is completed.
And setInterval has some fatal problems:
Cumulative effect, if the setInterval code has not completed execution before being added to the queue again, it will cause the timer code to run several times continuously without any interval. Even if they are executed at normal intervals, the execution time of multiple setInterval codes may be shorter than expected (because the code execution takes a certain amount of time)
For example, browsers such as iOS webview or Safari have a feature that when scrolling If you do not execute JS, if you use setInterval, you will find that it will be executed multiple times after the scrolling. Because the scrolling does not execute JS, the accumulated callbacks will cause the container to freeze and cause some unknown errors if the callback execution time is too long ( This section will be supplemented later. SetInterval’s built-in optimization will not add callbacks repeatedly)
And when the browser is minimized and displayed, setInterval does not not execute the program, it will put the callback function of setInterval in the queue. , when the browser window is opened again, it will all be executed in an instant
Therefore, in view of so many problems, the best solution currently generally considered is: use setTimeout to simulate setInterval, or directly use requestAnimationFrame
for special occasions. : As mentioned in JS Elevation, the JS engine will optimize setInterval. If there is a setInterval callback in the current event queue, it will not be added repeatedly.
The above has sorted out the JS event loop mechanism, which is sufficient in the case of ES5 , but now that ES6 is prevalent, you will still encounter some problems, such as the following question:
console.log('script start'); setTimeout(function() { console.log('setTimeout'); }, 0); Promise.resolve().then(function() { console.log('promise1'); }).then(function() { console.log('promise2'); }); console.log('script end');
Hmm, the correct execution order is like this:
script start script end promise1 promise2 setTimeout
Why? ? Because there is a new concept in Promise: microtask
Or, further, JS is divided into two task types: macrotask and microtask. In ECMAScript, microtask is called jobs, and macrotask can be called task.
What are their definitions? the difference? To put it simply, it can be understood as follows:
It can be understood that the code executed by the execution stack each time is a macro task (including each time from the event Obtain an event callback from the queue and put it into the execution stack for execution)
It can be understood that it is a task that is executed immediately after the execution of the current task ends
Addition: In the node environment, process.nextTick has a higher priority than Promise, which can be simply understood as: after the macro task ends, the nextTickQueue part of the microtask queue will be executed first. Then the Promise part of the microtask will be executed.
Let’s understand it based on threads:
(1) Events in macrotask are placed in an event queue, and this queue is maintained by the event triggering thread
(2) All microtasks in the microtask are added to the microtask queue (Job Queues), waiting for execution after the current macrotask is completed, and this queue is maintained by the JS engine thread (this is inferred from my own understanding, because it It is executed seamlessly under the main thread)
So, to summarize the operating mechanism:
As shown in the picture: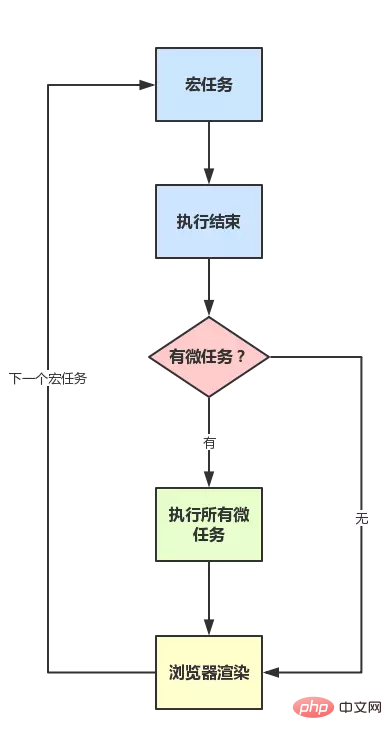
In addition, please pay attention to the difference between the Promise polyfill and the official version:
In the official version, it is the standard microtask form
Polyfill is generally simulated through setTimeout, so it is in the form of macrotask
Note that some browsers have different execution results (because they may execute microtask as macrotask), but for the sake of simplicity, some differences will not be described here. Scenario under standard browsers (but remember, some browsers may not be standard)
补充:使用MutationObserver实现microtask
MutationObserver可以用来实现microtask (它属于microtask,优先级小于Promise, 一般是Promise不支持时才会这样做)
它是HTML5中的新特性,作用是:监听一个DOM变动, 当DOM对象树发生任何变动时,Mutation Observer会得到通知
像以前的Vue源码中就是利用它来模拟nextTick的, 具体原理是,创建一个TextNode并监听内容变化, 然后要nextTick的时候去改一下这个节点的文本内容, 如下:
var counter = 1 var observer = new MutationObserver(nextTickHandler) var textNode = document.createTextNode(String(counter)) observer.observe(textNode, { characterData: true }) timerFunc = () => { counter = (counter + 1) % 2 textNode.data = String(counter) }
不过,现在的Vue(2.5+)的nextTick实现移除了MutationObserver的方式(据说是兼容性原因), 取而代之的是使用MessageChannel (当然,默认情况仍然是Promise,不支持才兼容的)。
MessageChannel属于宏任务,优先级是:MessageChannel->setTimeout, 所以Vue(2.5+)内部的nextTick与2.4及之前的实现是不一样的,需要注意下。
【相关推荐:javascript视频教程、web前端】
The above is the detailed content of Completely master the operating mechanism and principles of JavaScript. For more information, please follow other related articles on the PHP Chinese website!






















![JavaScript in-depth analysis [Web front-end must know basic skills]](https://img.php.cn/upload/course/000/000/041/61d3ff1c83b43350.jpg)
![TypeScript introductory video [can be understood even without learning JavaScript]](https://img.php.cn/upload/course/000/000/068/6242c0fc4be39373.png)






![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



