



Free learning recommendation: python video tutorial
xpath – simple crawler example – extract Onmyoji original painting wallpaper
Article Directory
1. Preface
Many people have played Onmyoji. Among other things, the original paintings of Onmyoji are quite delicate. In my spare time, I can crawl them with a few simple lines of code. Wouldn't it be beautiful if you took it off?
2. Libraries that need to be used
import requestsfrom lxml import etreefrom fake_useragent import UserAgentimport os
For those who have no need to install the library, you can take a look at this article I wrote before, which contains many domestic sources. link to facilitate your download.
Portal
3. Implementation process
First open the official website, official website portal, click " Audio-Visual Center"In "Original Painting Wallpaper"
After entering the Original Painting Wallpaper page, select a wallpaper and check it.
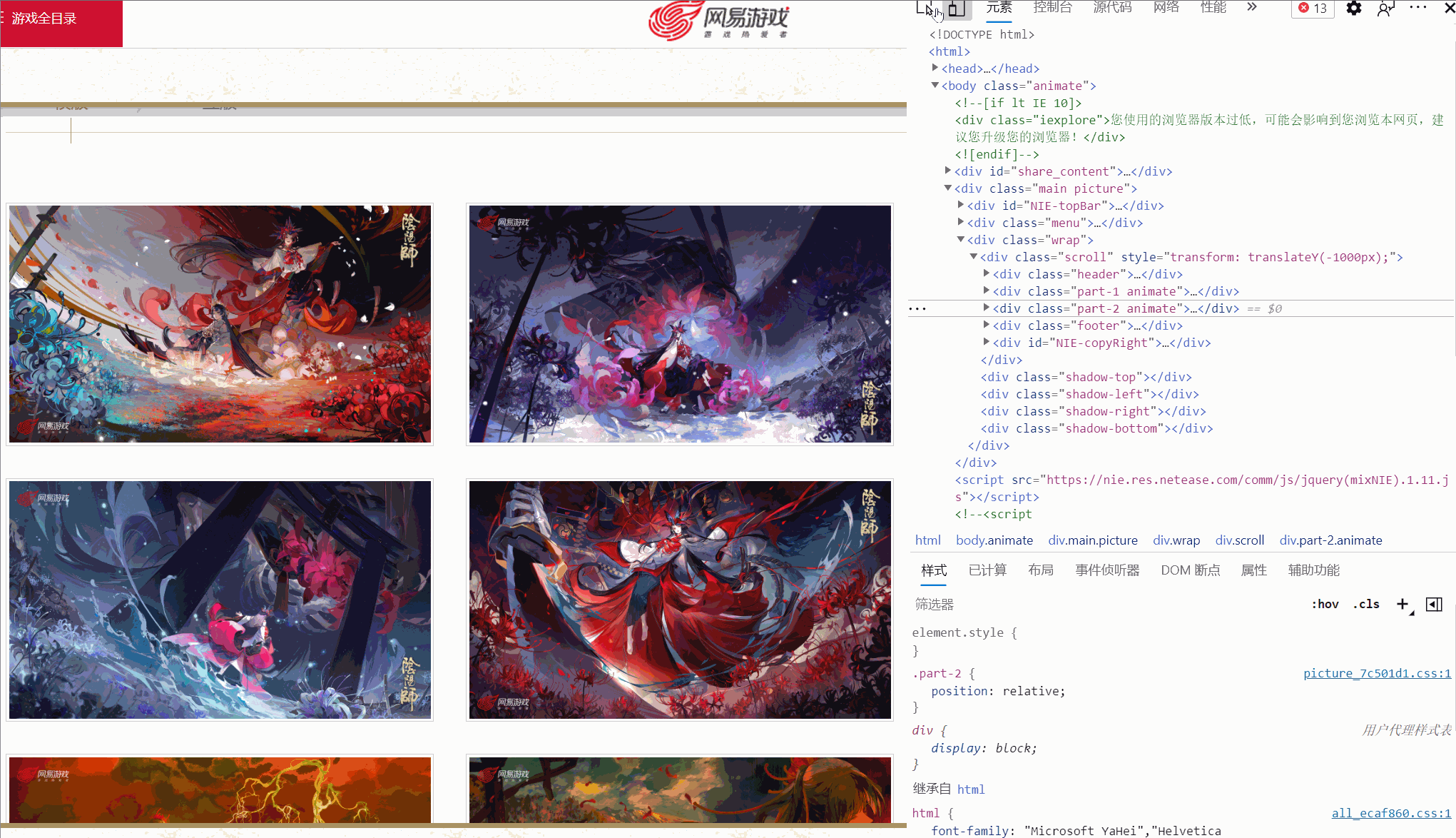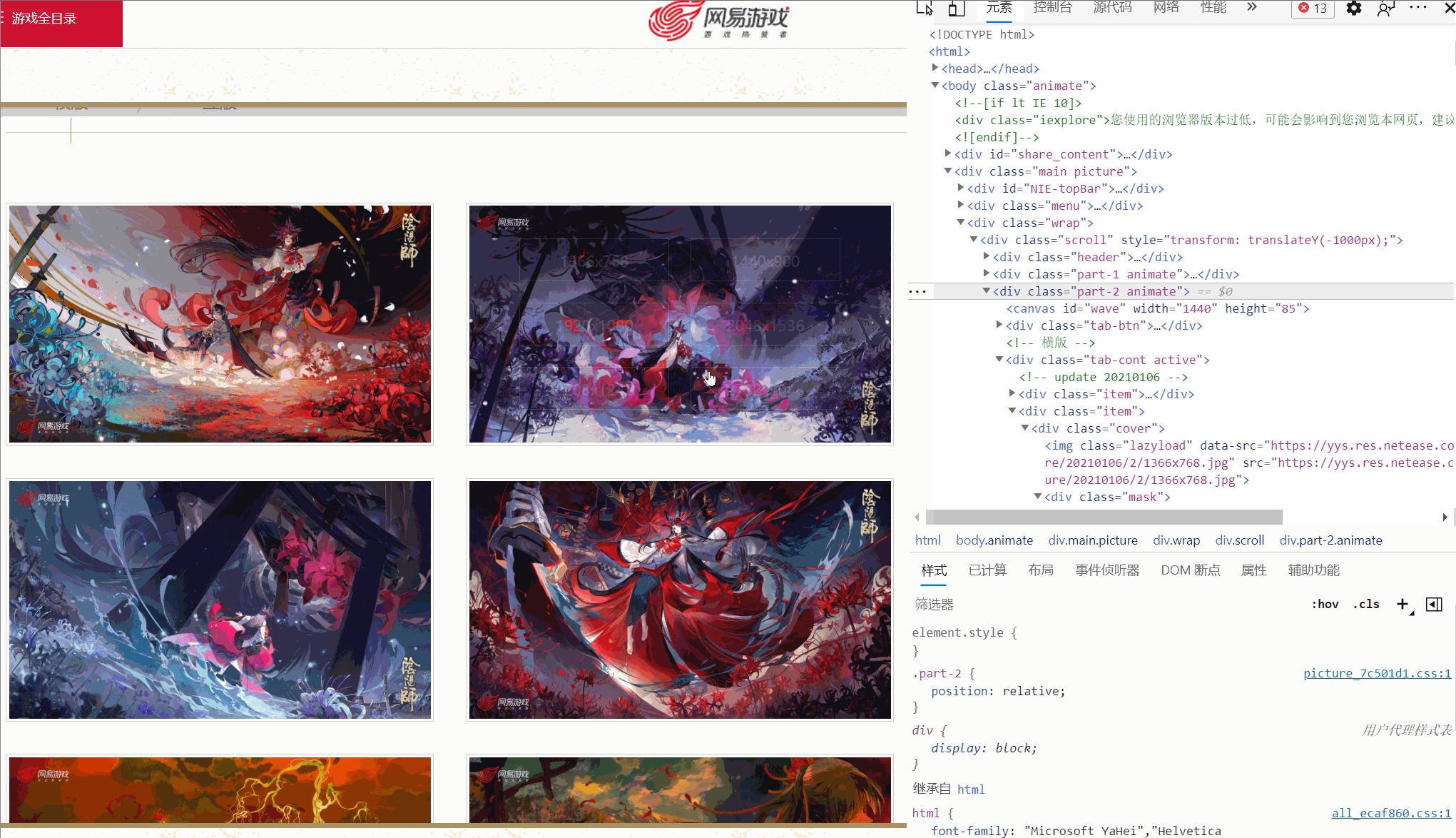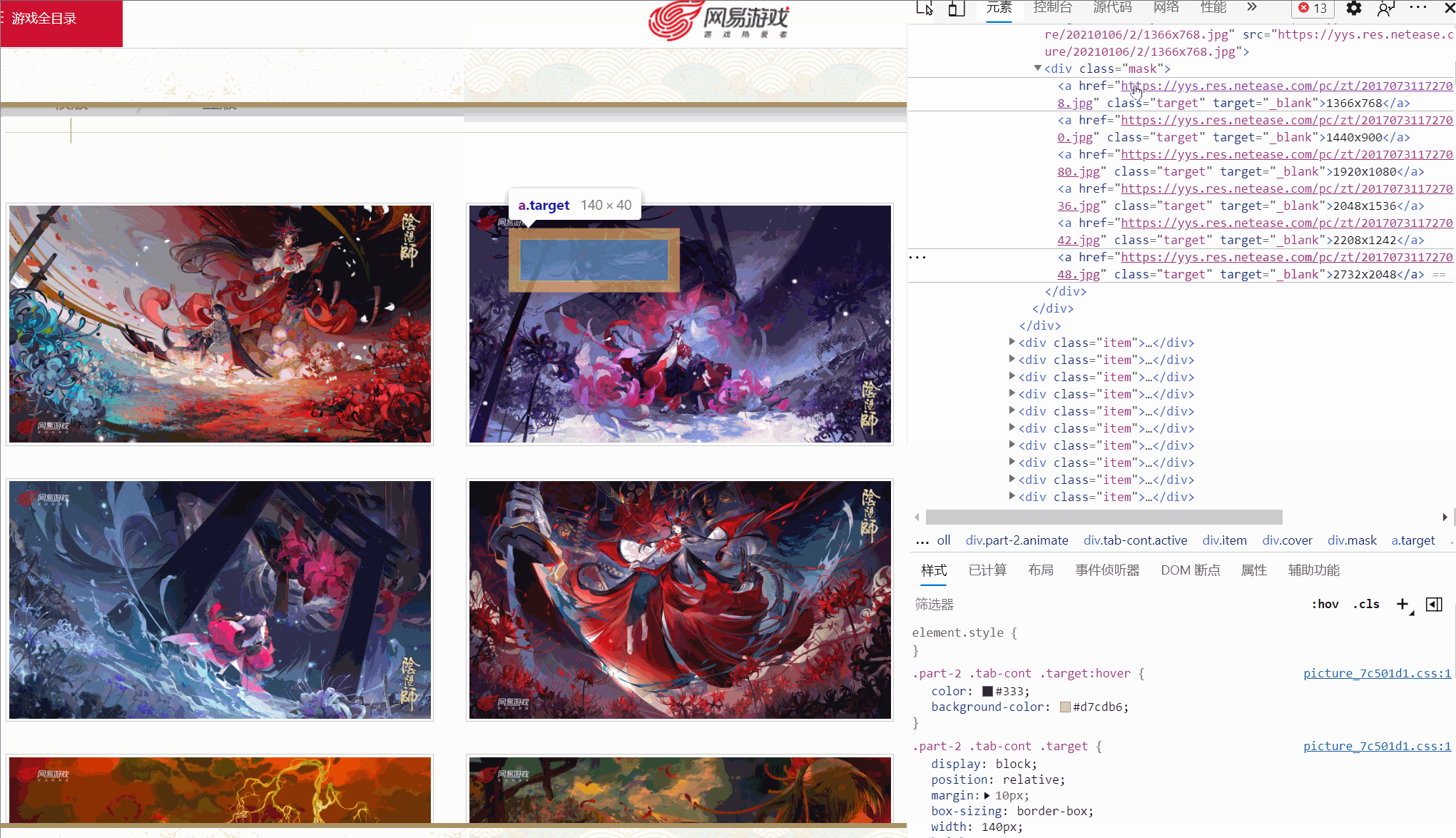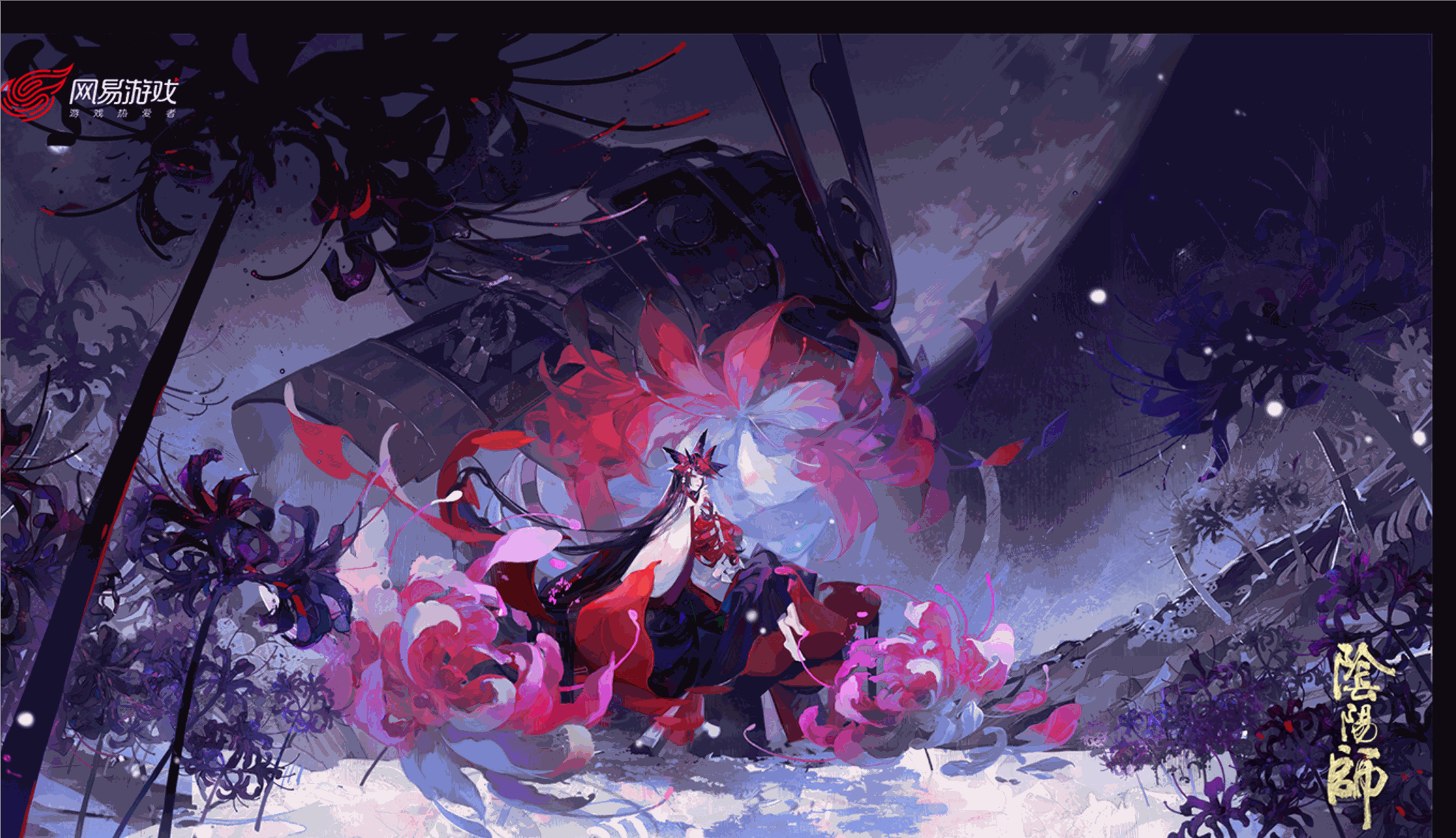
I found that there are different links corresponding to different resolutions, and the picture I checked has six resolutions. Are all pictures like this?
Later I discovered that it was not! 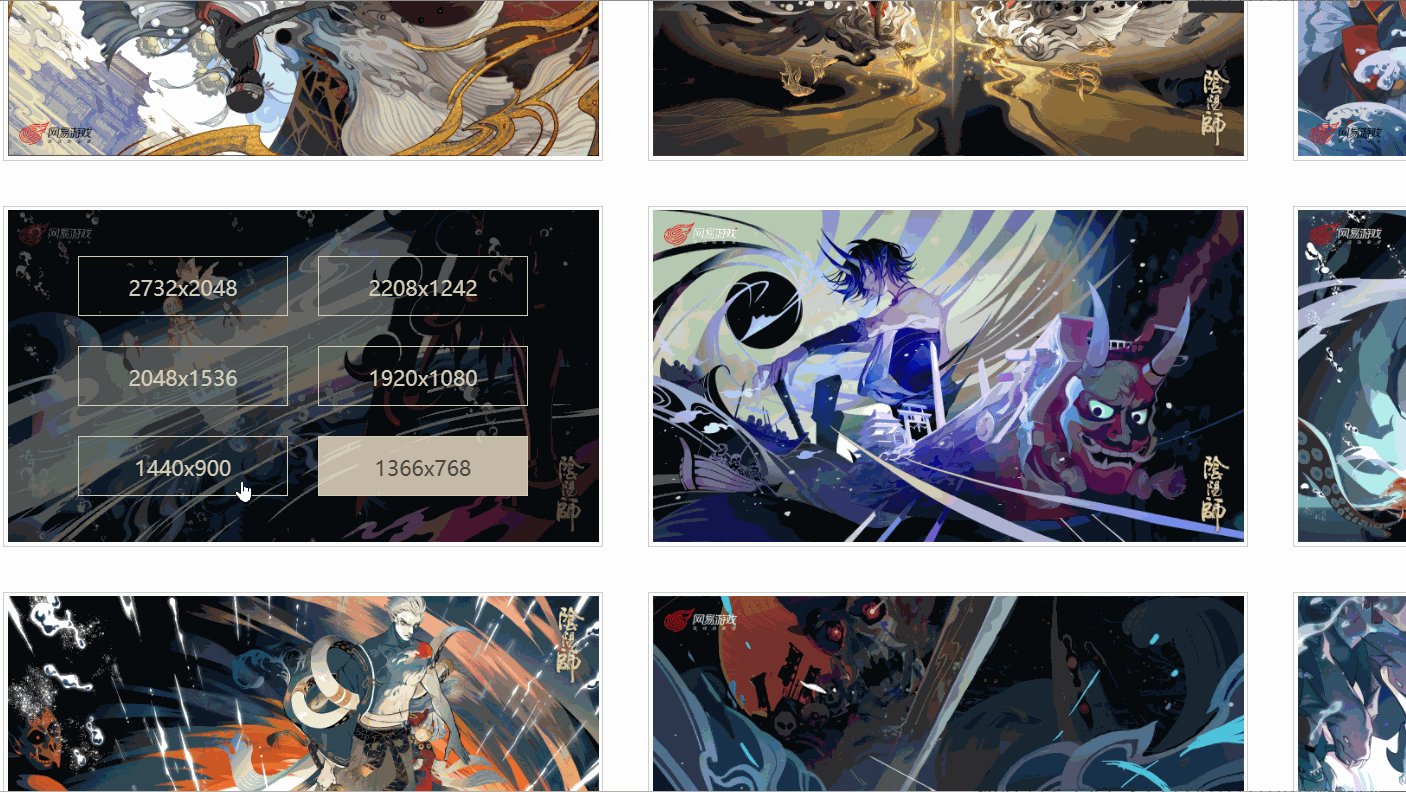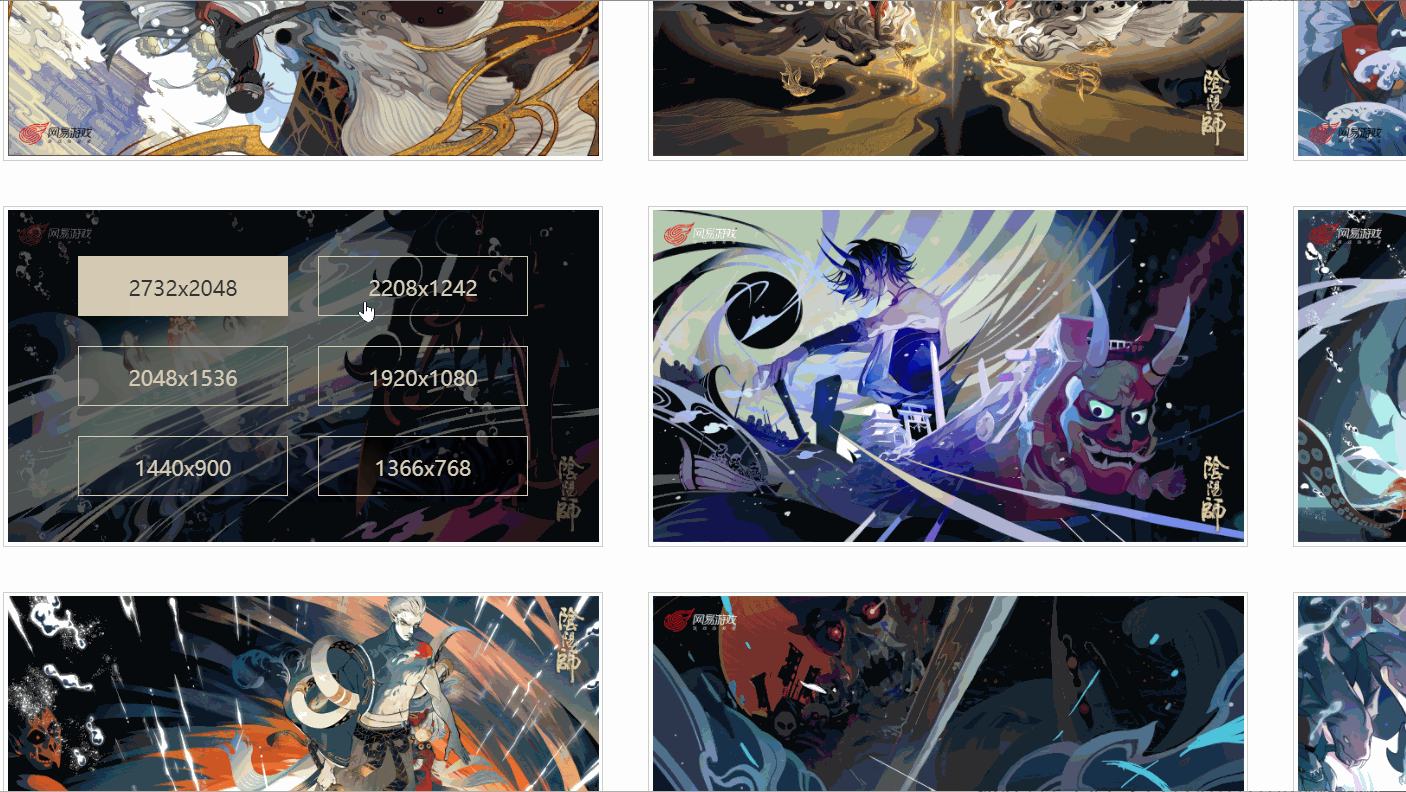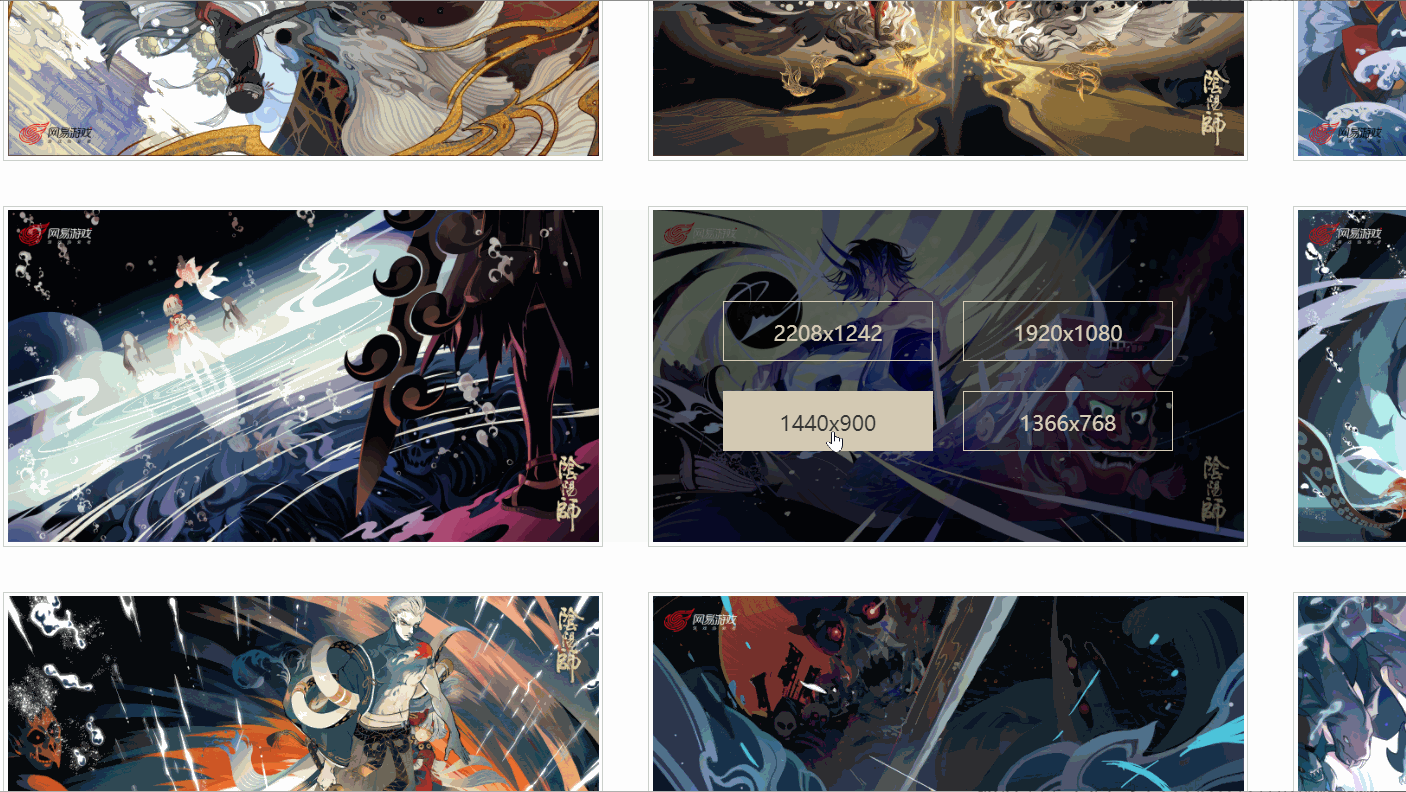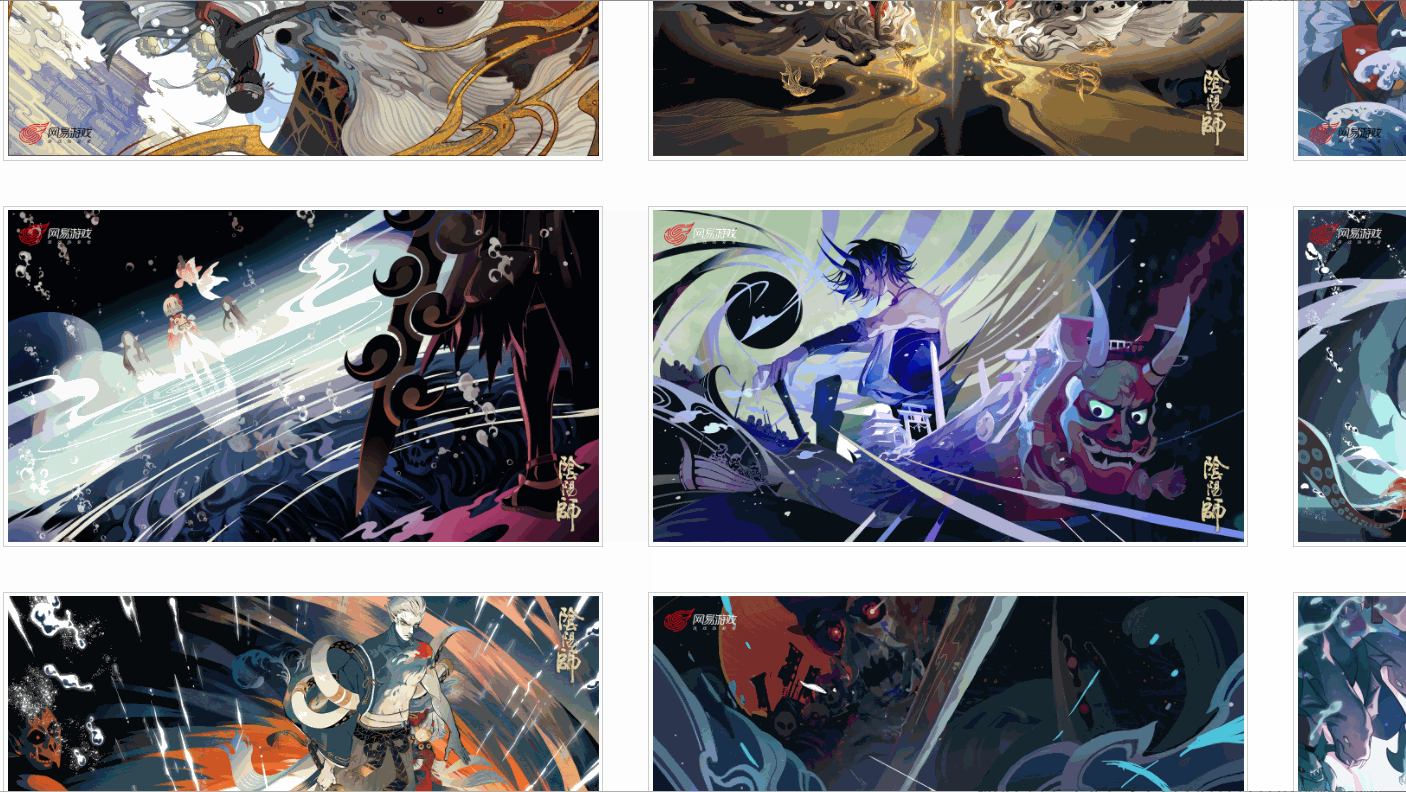
As shown above, one picture even only has four resolutions, and the resolution and position of each picture are not consistent. So how to extract the original painting link?
A: Use xpath to extract nodes based on text content
a = lists[i].xpath('./p/p/a[contains(text(), "1920x1080")]')[0]In this way, the a node with a resolution of "1920x1080" can be extracted.
Q:What is lists[i]?
A: You will know after reading the complete code.
import requestsfrom lxml import etreefrom fake_useragent import UserAgentimport os
path = 'D:/阴阳师'if not os.path.exists(path):
os.mkdir(path)# 随机产生请求头ua = UserAgent(verify_ssl=False, path='fake_useragent.json')url = 'https://yys.163.com/media/picture.html' # 原画壁纸的页面链接response = requests.get(url=url).text
html = etree.HTML(response)lists = html.xpath('/html/body/p[2]/p[3]/p[1]/p[3]/p[2]/p')num = 1for i in range(len(lists)):
a = lists[i].xpath('./p/p/a[contains(text(), "1920x1080")]')[0] # 根据文本内容锁定节点a
image_url = a.xpath('./@href')[0] # 获取原画壁纸链接
image_data = requests.get(url=image_url).content
image_name = '{}.jpg'.format(num) # 给每张图片命名
save_path = path + '/' + image_name # 图片的保存地址
with open(save_path, 'wb') as f:
f.write(image_data)
print(image_name, '=======================>下载成功!!!')
f.close()
num += 1The running results are as follows:

4. Synthetic video
Through the synthesized video, you can slowly appreciate the crawled original painting, which is very comfortable.
The code is as follows:
import cv2import os# 输出视频的保存路径video_dir = 'D:/yinyangshi/result.mp4'# 帧率fps = 0.2# 图片尺寸img_size = (1920, 1080)fourcc = cv2.VideoWriter_fourcc('M', 'P', '4', 'V') # opencv3.0 mp4会有警告但可以播放videoWriter = cv2.VideoWriter(video_dir, fourcc, fps, img_size)img_files = os.listdir('D:/yinyangshi/')for i in range(1, 397):
img_path = 'D:/yinyangshi/tupian/' + '{}.jpg'.format(i)
frame = cv2.imread(img_path)
frame = cv2.resize(frame, img_size) # 生成视频 图片尺寸和设定尺寸相同
videoWriter.write(frame) # 写进视频里
print(f'======== 按照视频顺序第{i}张图片合进视频 ========')videoWriter.release() # 释放资源Note: When compositing a video, the image saving path and video generation path cannot contain Chinese! ! !
Onmyoji original painting collection
Related free learning recommendations: python tutorial(Video)
The above is the detailed content of Python simply implements a one-click method to extract the original paintings of Onmyoji. For more information, please follow other related articles on the PHP Chinese website!


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



