


MySQL TutorialWhy use B Tree for the index introduced in the column

##Preface
The title of this article is a real problem I encountered during the interview process. An Internet crowdfunding company asked the first question when testing the interviewer's MySQL-related knowledge. , I was quite confused at the time. I didn’t expect that this young man didn’t follow martial arts ethics and didn’t play his cards according to routines. When people generally asked about MySQL-related knowledge, didn’t they always ask about index optimization, index failure and other related issues? Why did it come out? The storage files are different? Even if you examine the MVCC mechanism, it will do. So this time I will summarize this part of the knowledge points.Why you need to create an index
First of all, we all know that the purpose of creating an index is to improve the query speed, so why can the query speed be improved with an index? Let’s take a look at a schematic diagram of an index. 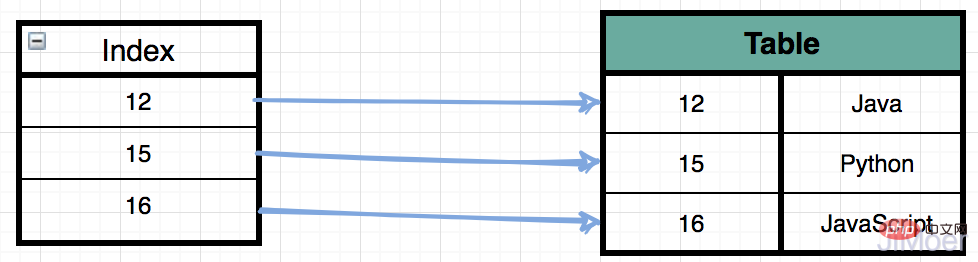 If I have a SQL statement:
If I have a SQL statement:
select * from Table where id = 15 Then in the absence of an index, a full table scan will actually be performed, that is, one by one Search until you find the record with id=15, the time complexity is O(n);
Why does MySQL index use B Tree
As we said above, index data is generally stored on disk, but calculated data must be in memory. If the index file is very large, it cannot be loaded into the memory at once, so when using the index for data search, multiple disk IOs will be performed to load the index data into the memory in batches, Therefore, a good index data structure must have the least number of disk IO times under the premise of obtaining correct results. <strong></strong>
Hash type
Currently, MySQL actually has two index data types to choose from, one is BTree (actually B Tree), A Hash. But why do most people choose BTree in actual use? Because if you use a Hash type index, MySQL will perform a Hash operation on the index data when creating the index, so that the disk pointer can be quickly located based on the Hash value, even if the amount of data is large. Data can also be located quickly and accurately., Hash type indexes cannot be handled. For this range query, the entire table will be directly Scanning, and Hash type indexes cannot be sorted.
Binary tree
Then why does MySQL not have a binary tree as its index data structure? We all know that binary trees locate data through binary search, so the effect is still good, and the time complexity is O(logn);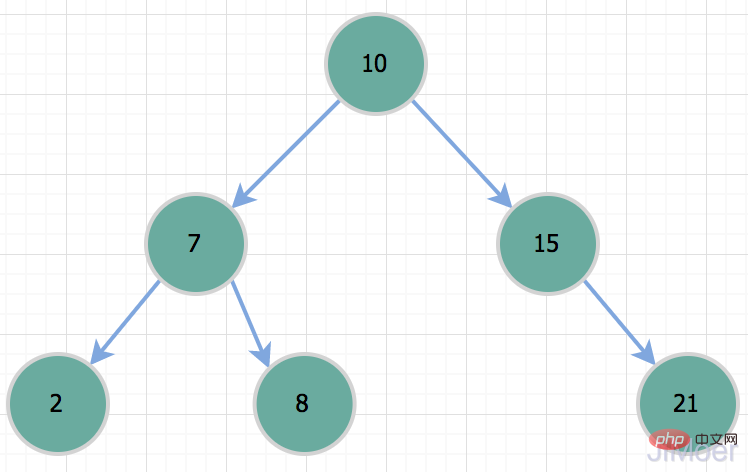 However, there is a problem with binary trees, that is, under special circumstances , it will degenerate into a stick, that is, a one-way linked list. At this time, its time complexity will degenerate to O(n);
However, there is a problem with binary trees, that is, under special circumstances , it will degenerate into a stick, that is, a one-way linked list. At this time, its time complexity will degenerate to O(n); 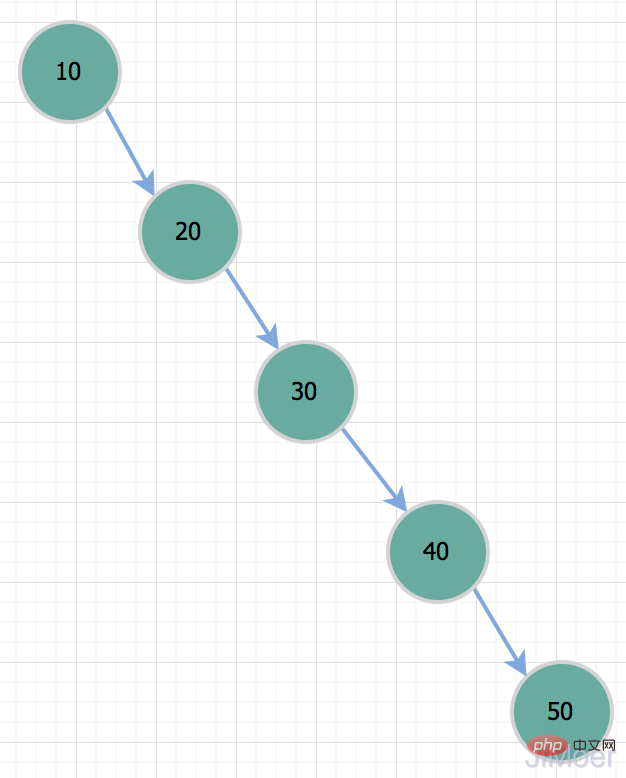 So when we want to query the record with id=50, it is actually the same as a full table scan. So because of this situation, the binary tree is not suitable as an index data structure.
So when we want to query the record with id=50, it is actually the same as a full table scan. So because of this situation, the binary tree is not suitable as an index data structure.
Balanced Binary Tree
So since a binary tree will degenerate into a linked list under special circumstances, why can't a balanced binary tree be used?The height difference between the child nodes of a balanced binary tree cannot exceed 1. Like the binary tree in the figure below, the node with the key 15 has a height of 0 on its left child node and a height of 0 on its right child node. is 1, and the height difference does not exceed 1, so the tree below is a balanced binary tree. 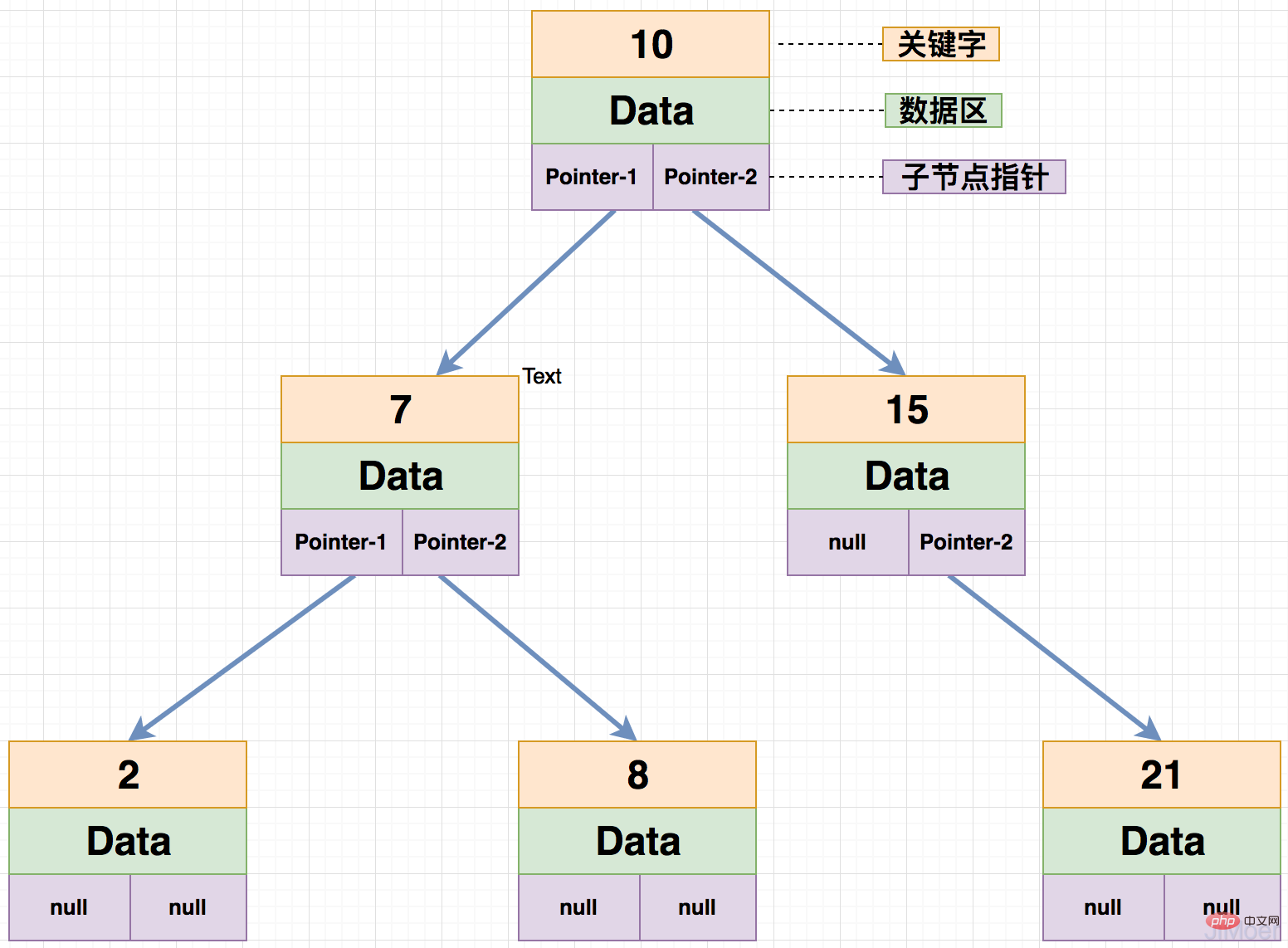 Because it can maintain balance, its query time complexity is O(logN). As for how to maintain balance, it mainly involves doing some left-hand rotation, right-hand rotation, etc. The specific details of maintaining balance are not in this article. If you want to know the main content, you can search it yourself.
Because it can maintain balance, its query time complexity is O(logN). As for how to maintain balance, it mainly involves doing some left-hand rotation, right-hand rotation, etc. The specific details of maintaining balance are not in this article. If you want to know the main content, you can search it yourself.
What are the problems with using this data structure to index MySQL?
Although the binary tree solves the problem of balance, it also brings new problems, that is, due to the depth of its own tree, it will cause a series of efficiency problems.
So in order to solve the problem of balancing binary trees, balanced multi-tree (Balance Tree) has become a better choice.
Balance Tree–B-Tree
B-Tree means balanced multi-tree. Generally, a node in B-Tree has The number of child nodes is what we call a B-Tree of that order. Usually m is used to represent the order. When m is 2, it is a balanced binary tree.
Each node of a B-Tree can have at most m-1 keywords, and at least Math.ceil(m/2)-1 keywords must be stored. All The leaf nodes are all on the same layer. The picture below is a 4th order B-Tree. 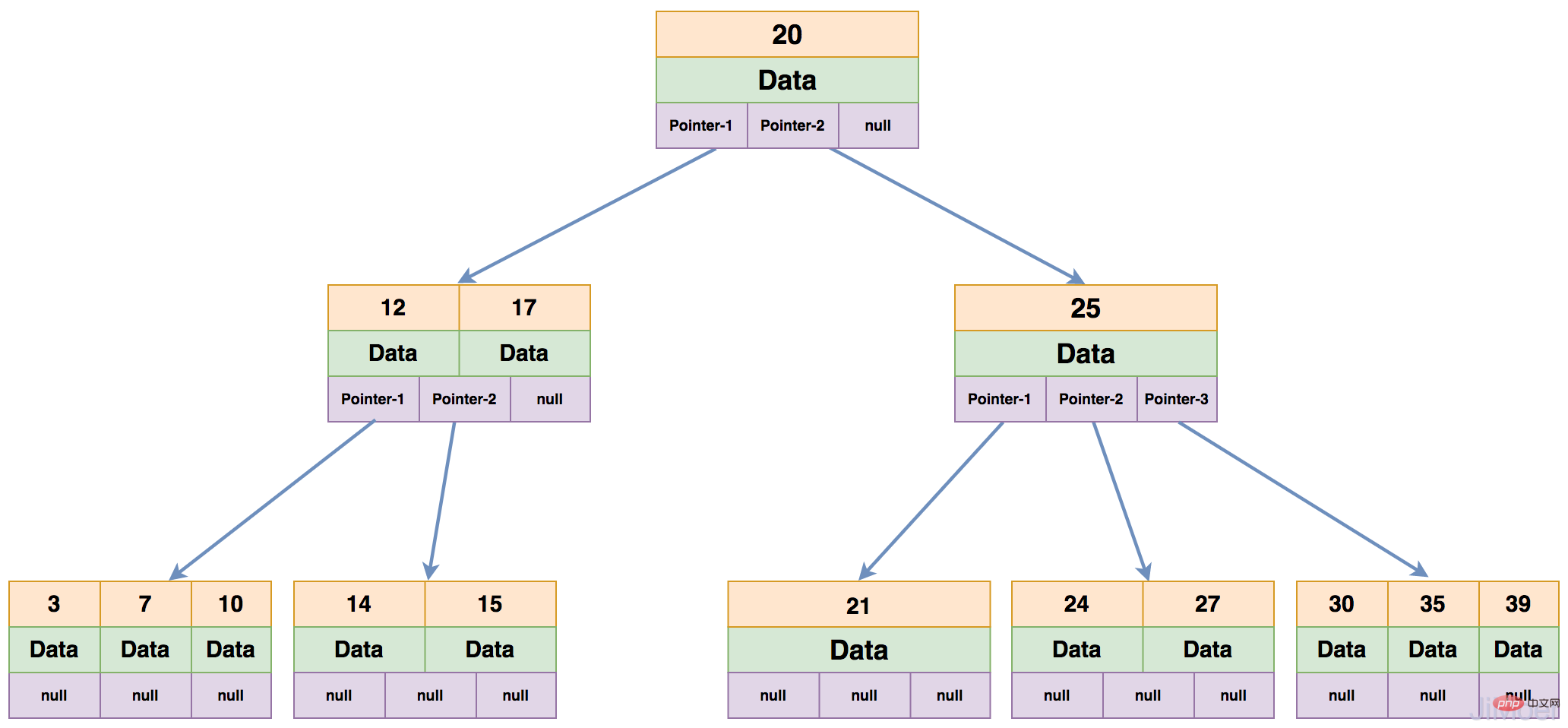
Then let’s take a look at how B-Tree searches for data:
In this way, the entire operation actually performs 3 IO operations, but in fact, a general B-Tree has many branches (usually greater than 100) in each layer.
In order to better utilize the IO capability of the disk, MySQL sets the size of the operation page to 16K, that is, the size of each node is 16K. If the keywords in each node are of int type, then it is 4 bytes. If the size of the data area is 8 bytes, and the node pointer occupies another 4 bytes, then each node of the B-Tree The number of keywords that can be saved is: (16*1000) / (4 8 4)=1000. Each node can store up to 1000 keywords, and each node can have up to 1001 branch nodes. .
In this way, when querying index data, one disk IO operation can read 1000 keywords into the memory for calculation. One disk IO operation of B-Tree balances the binary data on top. N disk IO operations have been performed.
It should be noted that:B-Tree will perform a series of operations in order to ensure the balance of the data. This process of maintaining balance is relatively time-consuming. , so when creating an index, you must choose appropriate fields and do not create too many indexes. If you create too many indexes, the process of updating the index will be more time-consuming when updating the data.
Also Don’t choose low-discrimination field values as indexes, such as gender fields. There are only two values in total. Then it may cause the depth of the B-Tree to be too large and the index Efficiency is reduced.
B Tree
B-Tree has solved the problem of balanced binary trees very well, and can also ensure query efficiency, so why is there B What about Tree?
Let’s first look at what B Tree looks like.
B Tree is a variant of B-Tree. The relationship between each node keyword and the m-order formula of B Tree is different from that of B-Tree.
First of all, the ratio of the number of child nodes of each node and the keywords that can be stored in each node is 1:1. Secondly, when querying data, the left closed interval is used for query. There is also no data in the branch node. Only the keywords and child node points are saved, and the data is stored in the leaf nodes. 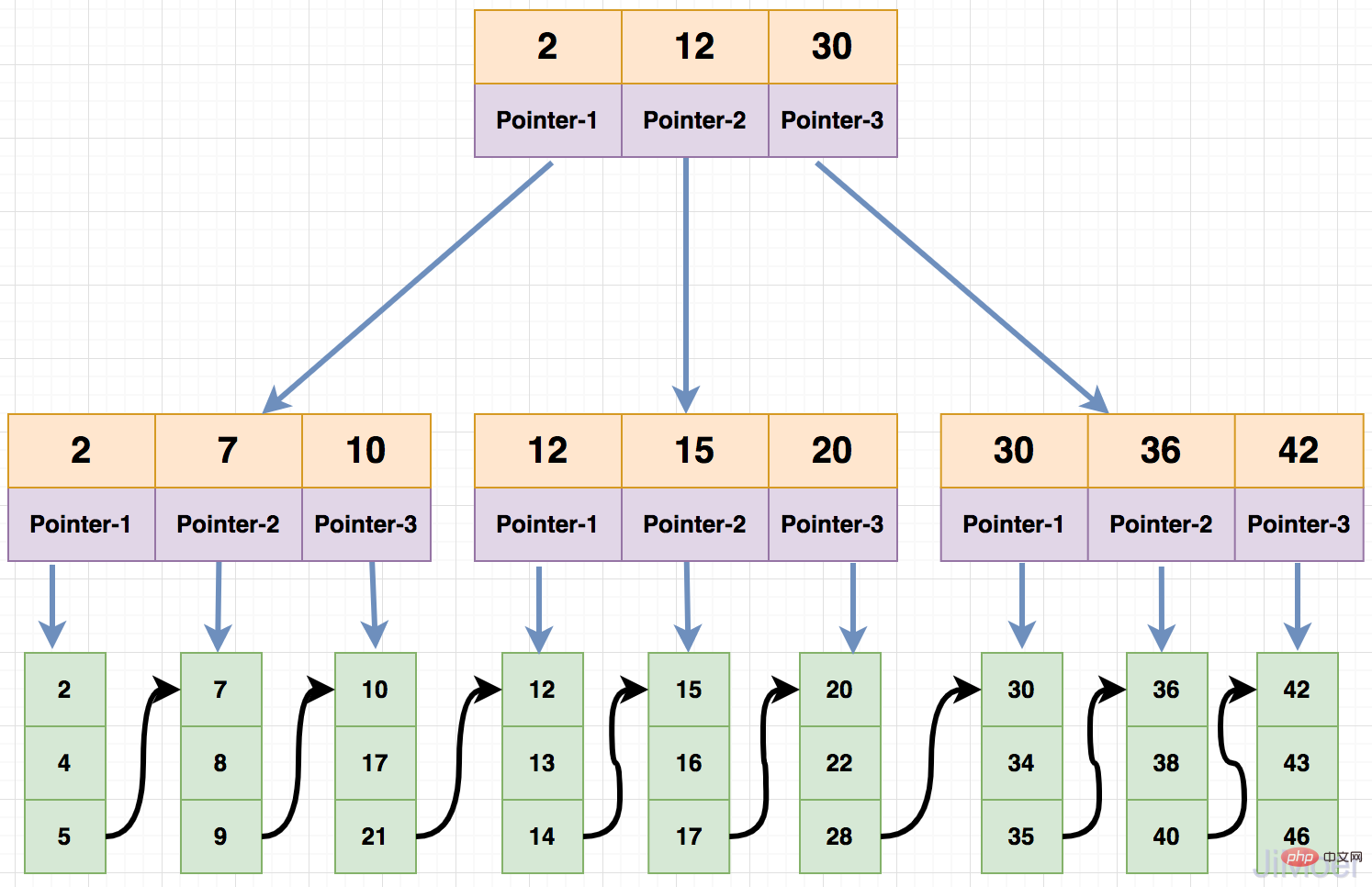
Then let’s take a look at how to perform data query in B Tree.
For example:
id=2 exists in the root node because it stores data in the left closed interval. , so id are all on the first child node of the root node;
id=2 keyword, and it has reached the leaf node, then directly retrieve the data in the leaf node and return it. Now let’s look at the difference between B-Tree and B Tree
After the above layer-by-layer analysis, we can now summarize why MySQL chose B Tree as the data structure for its index. Woolen cloth.
First of all, compared with the balanced binary tree, the depth of the B Tree is lower, the nodes save more keywords, the number of disk IOs is fewer, and the query calculation efficiency is better.
B Tree has stronger global scanning capabilities. If you want to globally scan the data table based on index data, B-Tree will scan the entire tree. Then traverse layer by layer. As for B Tree, you only need to traverse the leaf nodes, because there is a sequential reference relationship between leaf nodes.
B Tree’s disk IO read and write capabilities are stronger, because only keywords are saved on each branch node of B Tree, so that every time the disk IO is When reading and writing, one page of 16K data can store more keywords, and each node can store more keywords than B-Tree. In this way, B Tree's disk IO loads much more data than B-Tree.
B Tree data structure has natural sorting ability, which is stronger than other data structures and sorting is done through branch nodes. If Branch nodes need to be loaded into memory for sorting, and more data can be loaded at one time.
B Tree's query effect is more stable, because all queries need to scan the leaf nodes before returning the data. The effect is only stable but not necessarily optimal. If the root node data of B-Tree is directly queried, B-Tree can directly return the data with only one disk IO, but the effect is optimal.
After analyzing the above points, MySQL finally chose B Tree as the data structure of its index.
What are the differences between InnDB’s data storage files and MyISAM’s?
The above summarizes the data structure of MySQL index. This time we can talk about the second question, because this question actually has a certain relationship with MySQL index.
Let's take a look, first find the directory where the server MySQL stores data:
Log in to MySQL, open the MySQL command line interface: enter show variables like '�tadir%';, and you can See the directory where the data is stored.
The directory where MySQL stores data in my server is:
/var/lib/mysql/
After entering this directory, you can see the directories of all databases and create a new database of study_test.
Then enter the directory
/var/lib/mysql/study_test
. Currently there is only one file. This file is used to record the contents of the character set configured when creating the database.
-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt
Now create two new tables, select InnoDB as the engine type of the first table, and select MyISAM as the engine type of the second table.
student_innodb:
CREATE TABLE `student_innodb` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='innodb引擎表';
student_myisam:
CREATE TABLE `student_myisam` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='myISAM引擎类型表';
After the two tables are created, we enter /var/lib/mysql/study_testTake a look:
-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt-rw-r----- 1 mysql mysql 8650 1月 31 10:41 student_innodb.frm-rw-r----- 1 mysql mysql 114688 1月 31 10:41 student_innodb.ibd-rw-r----- 1 mysql mysql 8650 1月 31 10:58 student_myisam.frm-rw-r----- 1 mysql mysql 0 1月 31 10:58 student_myisam.MYD-rw-r----- 1 mysql mysql 1024 1月 31 10:58 student_myisam.MYI
Through the files in the directory, you can see that there are several more files after creating the table. This also shows that the InnoDB engine type table File differences with MyISAM engine type tables.
Each of these files has its own function:
MyISAM data storage engine, index and data storage structure
When the MyISAM storage engine stores the index, it The data is stored separately, and the indexed B Tree ultimately points to the physical address where the data exists, not the specific data. Then find the specific data in the data file (*.MYD) according to the physical address.
As shown in the figure below: 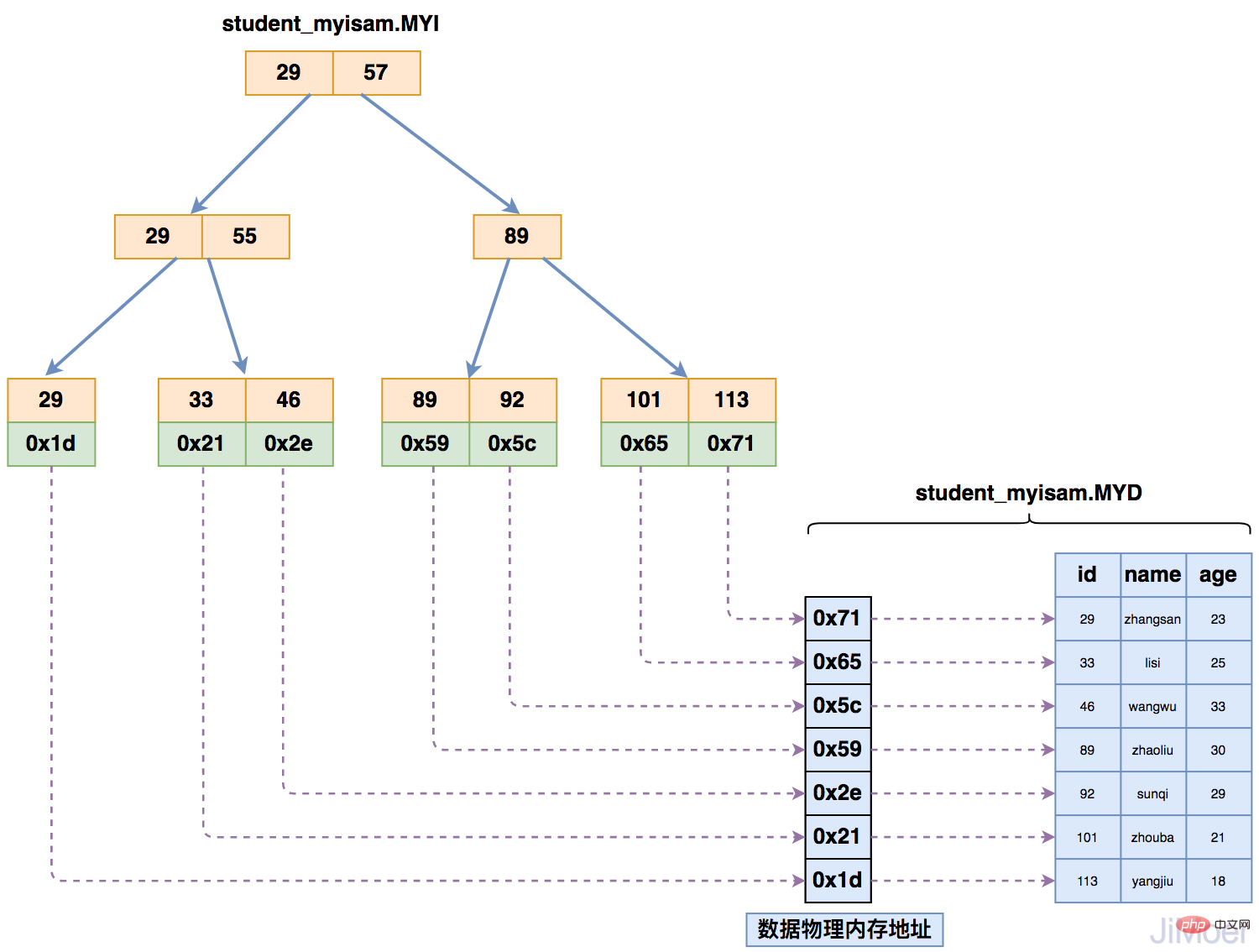
Then when there are multiple indexes, multiple indexes point to the same physical address.
As shown in the figure below: 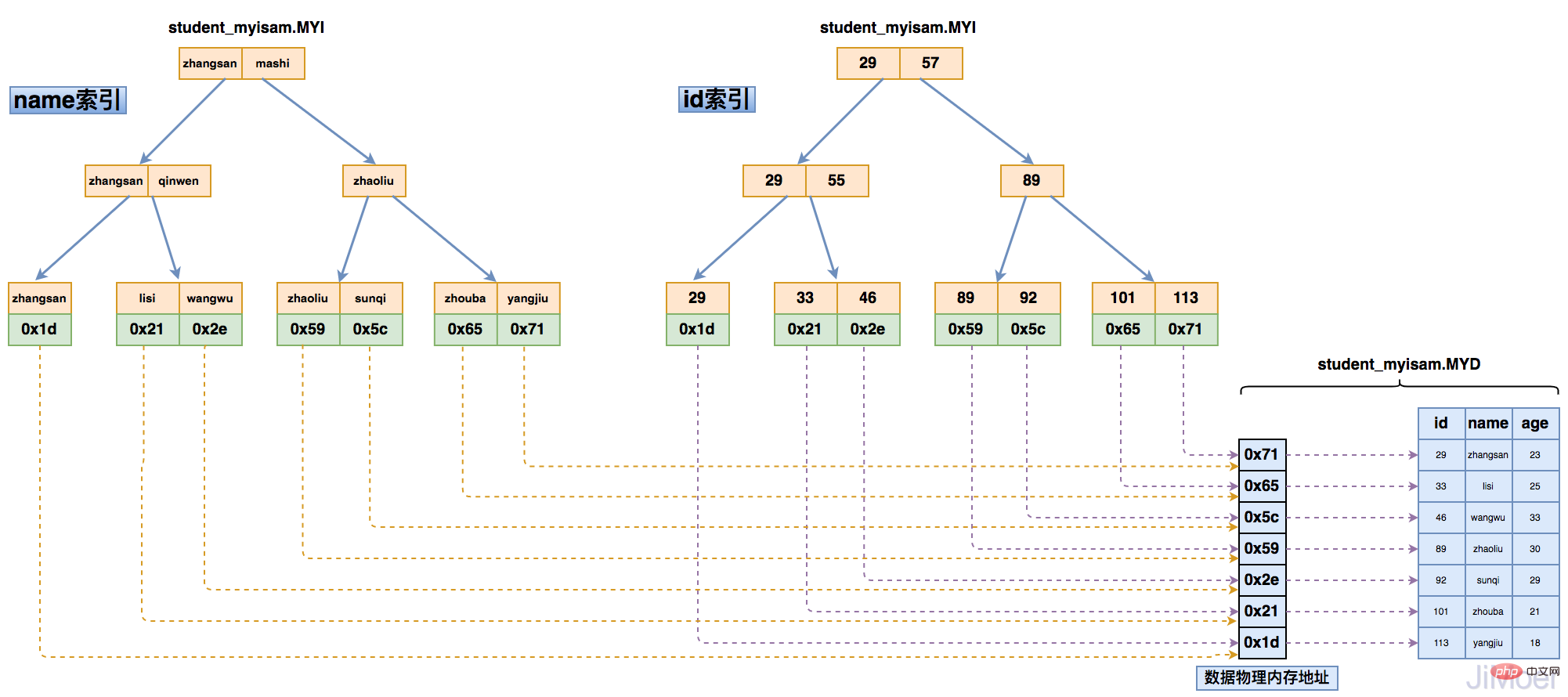
Through this structure, we can see that the indexes of MyISAM's storage engine are all at the same level, and the primary key and non-primary key index structures and query methods are exactly the same.
InnoDB data storage engine, index and data storage structure
First of all, InnoDB’s index is divided into clustered index and non-clustered index. Clustered index saves key Words save data, keywords are saved on each branch node of B Tree, and data are saved on leaf nodes.
"Clustering" means that the data rows are stored closely together one by one in a certain order. A table can only have one clustered index, because there is only one way to store data in a table. Generally, the primary key is used as a clustered index. If there is no primary key, InnoDB will generate a hidden column as the primary key by default.
As shown in the figure below: 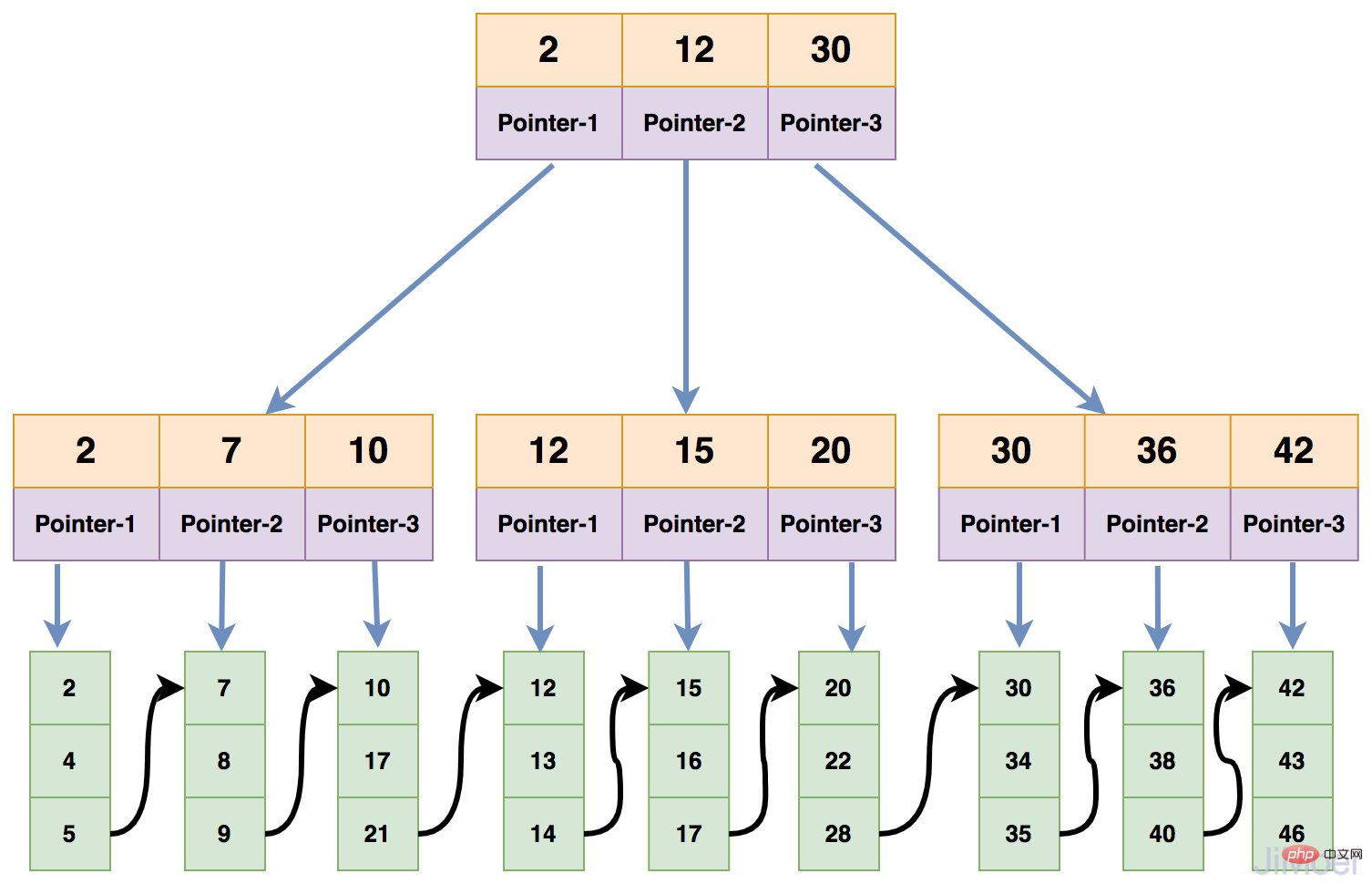
Non-clustered index, also known as secondary index, although it also saves keywords on each branch node of B Tree, but the leaf node Not the saved data, but the saved primary key value. Querying data through the secondary index will first query the primary key corresponding to the data, and then query the specific data row based on the primary key.
As shown in the figure below: 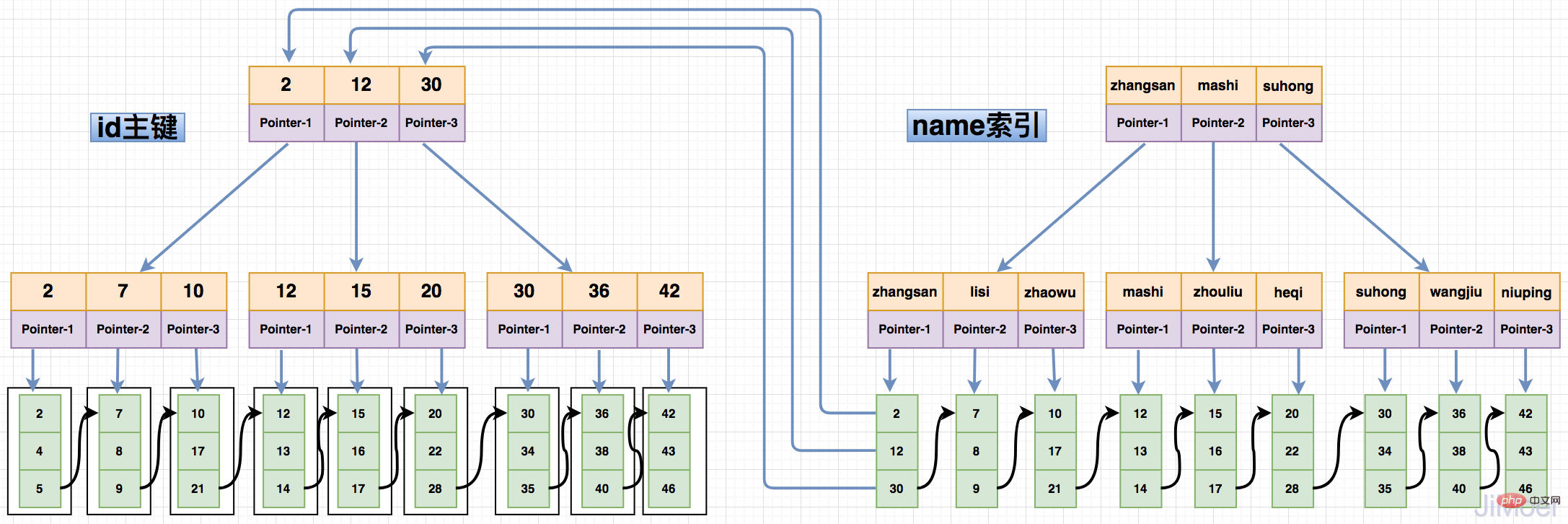
Due to the design structure of the non-clustered index, the non-clustered index needs to perform two index retrievals when querying. This design The advantage is that once data migration occurs, only the primary key index needs to be updated, and the non-clustered index does not need to be moved. It also avoids the need to store physical addresses like MyISAM indexes, which need to be re-maintained during data migration. All indexing issues.
Summary
This time I have clearly summarized the data structure of MySQL index and the file storage structure. Later, in the actual work process, when designing the index I can think more comprehensively. By understanding the data structure of the index, I can also consider when writing SQL, which situations are indexed and which are not.
Related free learning recommendations: mysql video tutorial
The above is the detailed content of InnoDB data storage files are different from MyISAM. For more information, please follow other related articles on the PHP Chinese website!















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



