


TodayMySQL Tutorial column will introduce to you the basic architecture that I understand.

As a serious CRUD engineer, interaction with the database plays a large part in daily work, such as adding, deleting, modifying, and processing historical data in daily iterations. , optimize SQL performance, etc. As the amount of project data increases, the deep pits I buried in order to keep up with the project progress are slowly revealing their power. This also forces me to learn MySQL comprehensively and in-depth, instead of just staying on the basic CRUD. .
The first article in the MySQL series mainly introduces the infrastructure of MySQL and the functions of each component, including the bin log of the server layer and the redo log unique to InnoDB.
According to the ranking of the most popular database management systems released by DB-Engines, MySQL is firmly in the second place.
As one of the most popular relational database management systems, MySQL uses a C/S architecture, that is, Client & Server architecture. For example, if a developer uses Navicat to connect to MySQL, then the former is the client and the latter is the server.
At the same time, MySQL is also a single-process, multi-threaded database. This is easy to understand. The running MySQL instance is the "single process", and there will be many threads in this process, such as the main thread Master Thread, IO Thread, etc. These threads are used to handle different tasks.
As mentioned earlier, MySQL uses a C/S architecture. Users connect to the MySQL server through the client, and then submit SQL statements to the server, and then the server will The execution results are returned to the client.
In this section, we mainly focus on the logical composition of the MySQL server. Let’s look at a picture first.
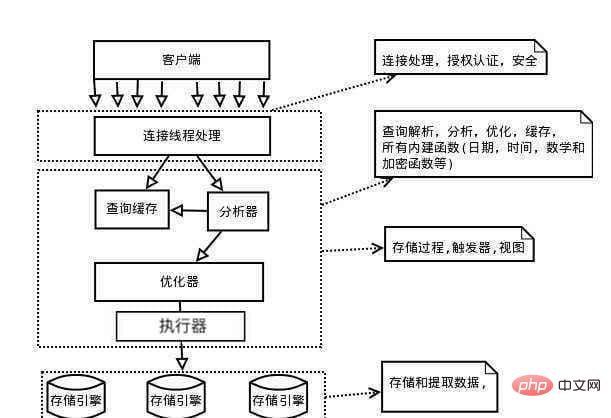
As you can see from the above figure, in the interaction with the client, the MySQL server passes through the connector, query cache, analyzer, optimizer, executor and These parts of the storage engine.
The following uses a simple query statement to describe the various components of the MySQL server and their functions.
Before the client submits a query statement, it needs to establish a connection with the server. So the first thing to come is the connector. The function of the connector is to be responsible for establishing and managing the connection with the client, and at the same time querying the user's permissions.
It should be noted that:
After establishing a connection through the connector and obtaining user permissions, the user can submit query statements.
The first thing to pass is the query cache part. As you can guess from its name, the function of the query cache is to query whether MySQL has executed the query statement submitted by the client. If this If the SQL has been executed before, and the user has permission to execute the statement on the table, the results of the previous execution will be returned directly.
So at some point, executing a SQL statement multiple times cannot get its average execution time. Because of the query cache, subsequent execution times are often shorter than the first execution time.
If you don’t want to use caching, you can use the update statement to update the table after each query. Of course, this is a very troublesome and silly method. MySQL also provides the corresponding configuration item - query_cache_type. You can set query_cache_type to 0 in the my.cnf file to turn off the query cache.
It should be noted that:
key-value, where key is the query statement and value is the query result. MySQL 8.0, the query cache function has been removed. The MySQL version I use is 5.7.21, so the query statement submitted by the client will go to the query cache. If there is no hit, it will continue to go down. , come to the analyzer.
The analyzer will perform lexical analysis (parsing the statement) and syntax analysis (determining whether the statement conforms to MySQL's grammatical rules) on the submitted statement, so the role of the analyzer is to parse the SQL statement and check its legality.
It should be noted that:
For example:
select * form user_info limit 1;复制代码
There are two errors in the above SQL statement. The first is a misspelling of from, and the second is that the user_info table does not exist. After execution, MySQL will only remind you of an error. The following shows the result information of executing SQL three times.
第一次的执行信息: 1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'form user_info limit 1' at line 1, Time: 0.000000s 修改为from后第二次的执行信息:1146 - Table 'windfall.user_info' doesn't exist, Time: 0.000000s 修改为 user 表后第三次的执行信息: OK, Time: 0.000000s复制代码
After verifying the legality of the SQL statement, MySQL already knows what the statement submitted by the user is for, but before it is actually executed, it still needs to go through a very " Metaphysics" optimizer.

The function of the optimizer is to generate the optimal execution plan for the SQL statement.
The reason why the optimizer is said to be "metaphysical" is because in the process of optimizing SQL statements, it may generate execution plans that are unexpected by the user (index selection, multi-table association connection sequence, implicit function conversion, etc.). Of course, the optimizer sometimes "selects the wrong" index, which is related to factors such as data volume and index statistics.
It should be noted that:
Regarding the workflow of the MySQL optimizer, you can read this blog: This is how the MySQL optimizer originally works
The execution plan of MySQL is also a skill that must be mastered , this blog is very detailed and worth reading: I don’t know how to read the Explain execution plan. I advise you not to write in your resume that you are familiar with SQL optimization
The optimizer generates MySQL. I think After the optimal execution plan, we finally come to the executor. The role of the executor is of course to execute SQL statements.
But before execution, permission verification must be done first to verify whether the user has query permissions on the table. Then according to the engine type defined by the table, use the interface provided by the corresponding engine to perform conditional query on the table, and finally return all the data rows of the table that meet the conditions to the client as a result set, so that the execution of the entire SQL is over. .
It should be noted that:
MySQL supports many storage engines, such as: InnoDB, MyISAM, Memory, etc.
InnoDB is the most commonly used MySQL storage engine today and is also the default storage engine after MySQL 5.5.
InnoDB supports transactions, MVCC (Multiple Version Concurrency Control), foreign keys, row-level locks and auto-increment columns. However, InnoDB does not support full-text indexing, and it takes up more data space.
MyISAM is the default storage engine for MySQL 5.1 and earlier, supporting full-text indexing, compression, spatial functions, and table-level locks.
MyISAM's data is stored in a compact format so it takes up less space. It has high insertion and query speeds, but MyISAM does not support transactions and cannot be safely recovered after a crash.
All data in Memory is saved in memory. Since no disk I/O is required, its speed is an order of magnitude faster than MyISAM and InnoDB. But if the database is shut down or restarted, the Memory engine data will disappear.
Memory supports Hash index, but because it uses table-level locks, the performance of concurrent writes is relatively low.
It is worth mentioning that temporary tables in MySQL are generally saved in Memory tables. If the amount of data in the intermediate table is too large or contains fields of BLOB type or TEXT type, MyISAM tables will be used.
Regarding the storage engine, since I have relatively little contact with it, I will sort it out after reading "MySQL Technology Insider: InnoDB Storage Engine". I will just briefly mention it here.
The execution process mentioned above mainly describes the query statement. If it is an update statement, it also involves the MySQL log module.
The logical query statements and update statements from the client to the executor are the same, except that when reaching the executor layer, the update statement will interact with the MySQL log module. This is The difference between query statements and update statements.
对于 InnoDB 存储引擎来说,它有一个特有的日志模块——物理日志(重做日志)redo log,它是 InnoDB 存储引擎的日志,它所记录的是数据页的物理修改。
举个例子,现在有一张 user 表,有一条主键 id=1,age=18 的数据,然后用户提交了下面这条 SQL,执行器准备执行。
update user set age=age+1 where id=1;复制代码
对于这条 SQL,在 redo log 中记录的内容大致是:将 user 表中主键 id=1 行的 age 字段值修改为19。
MySQL 的更新持久化逻辑运用到了 WAL(Write-Ahead Logging,写前日志记录) 的思想:先写日志,再写磁盘。
需要注意的是这里的写日志也是写到磁盘中,但由于日志是顺序写入的,所以速度很快。而如果没有 redo log,直接更新磁盘中的数据,那么首先需要找到那条记录,然后再把新的值更新进入,由于查询和读写I/O,就相对会慢一些。
最后,当 InnoDB 引擎空闲的时候,它会去执行 redo log 中的逻辑,将数据持久化到磁盘中。
redo log 日志文件大小是固定的,我把它理解为一个One of my understanding of MySQL: infrastructure,链表的每个节点都可以存放日志,在这个链表中有两个指针:write(黑) 和 read(白)。
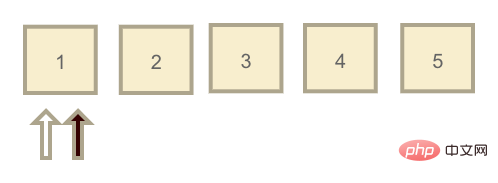
最开始这两个指针都指向同一个节点,且节点日志元素都为空,表示此时 redo log 为空。当用户开始提交更新语句,write 节点开始往前移动,假设移动到3的位置。而此时的情况就是 redo log 中有1-3这三个日志元素需要被持久化到磁盘中,当 InnoDB 空闲时,read 指针往前移动,就代表着将 redo log 持久化到磁盘。
但这里有一种特殊情况,就是 InnoDB 一直没有空闲,write 指针一直在写入日志,直到它写到5的位置,再往前写又回到了最开始1的位置(也就是上图的位置,但不同的是链表节点中都存在日志数据)。
此时发现1的位置已经有日志数据了,同时 read 指针也在。那么这时候 write 指针就会暂停写入,InnoDB 引擎开始催动 read 指针移动,把 redo log 清空掉一部分之后再让 write 指针写入日志文件。
我们已经知道,redo log 中记录的是数据页的物理修改,所以 redo log 能够保证在数据库发生异常重启时,记录尚未写入磁盘,但是在重启后可以通过 redo log 来“redo”,从而不会发生记录丢失的情况,保证了事务的持久性。
这一能力也被称作 crash-safe。
前面说到 redo log 是 InnoDB 特有的日志,而 bin log 则是属于 MySQL Server 层的日志,在默认的 Statement Level 下它记录的是更新语句的原始逻辑,即 SQL 本身。
另外需要注意的是:
与 redo log 不同的是,bin log 常用于恢复数据,比如说主从复制,从节点根据父节点的 bin log 来进行数据同步,实现主从同步。
为了让 redo log 和 bin log 的状态保持一致,MySQL 使用两阶段提交的方式来写入 redo log 日志。
在执行器调用 InnoDB 引擎的接口将写入更新数据时,InnoDB 引擎会将本次更新记录到 redo log 中,同时将 redo log 的状态标记为 prepare,表示可以提交事务。
随后执行器生成本次操作的 bin log 数据,并写入 bin log 的日志文件中。
最后执行器调用 InnoDB 的提交事务接口,存储引擎把刚写入的 redo log 记录状态修改为 commit,本次更新结束。
在这个过程中有三个步骤 add redo log and mark as prepare -> add bin log -> commit,即:
If in the second step, also That is, the system crashes or restarts before writing the bin log. After startup, since there is no record in the bin log, the records in the redo log will be rolled back to before the execution of this update statement.
If the system crashes or restarts before the third step, that is, before submission, even if there is no commit but the record in the redo log is in prepare status and there is a complete record in the bin log, it will be automatically committed after the restart. It will not be rolled back.
This article mainly introduces the infrastructure of MySQL and the functions of each component. Finally, it introduces the bin log of the MySQL Server layer and the redo log unique to InnoDB.
The following questions are to question the content described in this article and consolidate knowledge. As the saying goes, "Reviewing the past and learning the new can become a teacher."
What is the difference between redo log and bin log?
More related free learning recommendations: mysql tutorial(Video)
The above is the detailed content of One of my understanding of MySQL: infrastructure. For more information, please follow other related articles on the PHP Chinese website!


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



