


In small and medium-sized Internet companies. MySQL clusters generally have the architecture shown above. The WEB node reads the dbproxy server when reading the database. The dbproxy server separates reading and writing of the database by judging SQL statements. Read requests are loaded to the slave library (the master library can also be added), and write requests are written to the master library.

The dbproxy here is the only outlet of the database cluster, so it also needs to be highly available.
drproxy is a commonly used software for database read-write separation. amoeba, mycat, and cobar are also commonly used. This kind of software not only has the function of separation of reading and writing, but also can realize load balancing and health check of back-end nodes.
In addition to realizing the separation of reading and writing in the database through this type of database middleware software, it can also be written in the program.
Usually our main library needs to be dual-master high-available, so that if the main library fails, the other main library will take over immediately. If dual master is not used, state migration will be required when the slave database takes over the master database, which will cause a delay.
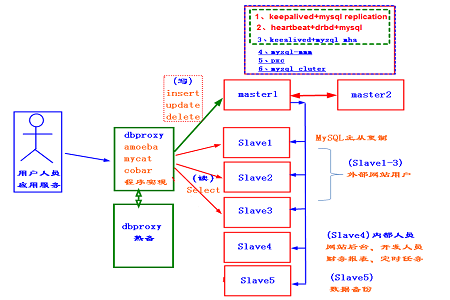
#The key point to consider for the high availability of the main database is data synchronization. The more commonly used high availability solutions are:
1, keepalived mysql replication. VIP elegance is achieved through keepalived, and data synchronization is achieved through replication, the synchronization solution provided by mysql.
2. hearbeat drbd. Dual-master data synchronization is achieved through DRBD. This data synchronization is based on block devices. Much faster than ordinary synchronization solutions. Realize VIP drift and DRBD resource switching management through heartbeat.
3. keepalived mha.
For slave libraries, it is best not to exceed 5. We can use three of them as nodes for users to access, and use the other one as a query node for insiders. Because when internal personnel query nodes, they usually query according to time periods without indexing, which takes up a lot of resources. Therefore, this node must be dedicated separately to avoid affecting customer access. Finally, we should leave a slave database for data backup of the database.
The data consistency of the slave database can be maintained through master-slave assistance directly from the master database, or master-slave replication from other slave databases (the advantage is to reduce the pressure on the master database, but the disadvantage is that the delay is slightly larger).
The above is the detailed content of What do large companies use for mysql clusters?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



