


The main content of this article is to use PHP multiple processes to cooperate with the ordered collection of redis to achieve large file deduplication. Interested friends can learn about it.
1. For a large file, for example, my file is
-rw-r--r-- 1 ubuntu ubuntu 9.1G Mar 1 17:53 2018-12-awk -uniq.txt
2. Use the split command to cut into 10 small files
split -b 1000m 2018-12-awk-uniq.txt -b Cut according to bytes, supported unit m and k
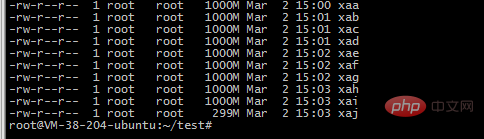
3. Use 10 php processes to read the file and insert it into the ordered set structure of redis. Repeated ones cannot be inserted. , so it can play the role of deduplication
<?php
$file=$argv[1];
//守护进程
umask(0); //把文件掩码清0
if (pcntl_fork() != 0){ //是父进程,父进程退出
exit();
}
posix_setsid();//设置新会话组长,脱离终端
if (pcntl_fork() != 0){ //是第一子进程,结束第一子进程
exit();
}
$start=memory_get_usage();
$redis=new Redis();
$redis->connect('127.0.0.1', 6379);
$handle = fopen("./{$file}", 'rb');
while (feof($handle)===false) {
$line=fgets($handle);
$email=str_replace("\n","",$line);
$redis->zAdd('emails', 1, $email);
}
4. View the acquired data in redis
zcard emails Get the number of elements
 Get elements in a certain range, such as starting from 100000 and ending at 100100
Get elements in a certain range, such as starting from 100000 and ending at 100100
zrange emails 100000 100100 WITHSCORES
If you want to learn PHP more efficiently, please pay attention to the
PHP video tutorialThe above is the detailed content of PHP combined with redis to achieve large file deduplication. For more information, please follow other related articles on the PHP Chinese website!


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



