


This article mainly tells you about the principles of the Linux operating system. This is a very good basic tutorial on the Linux system. We have summarized all the relevant selected content, let’s study together. Hope it helps everyone.
1. The four eras of computers
1. The first generation:
Vacuum tube computers, input and output : Punch cards are very inconvenient to operate on computers. Doing one thing may require more than a dozen people to complete it together. The year is probably: 1945-1955. And it consumes a lot of power. If you had a computer at home at that time, the brightness of your light bulbs might dim as soon as you turn on the computer, haha~
2. Second generation:
Transistor computers, batch (serial mode operation) systems appear. It saves much more power than the first one. The typical representative is Mainframe. Approximate year: 1955-1965. At that time: Fortran language was born~a very old computer language.
3. The third generation:
The emergence of integrated circuits and the design of multi-channel processing programs (running in parallel mode). The more typical representatives are: time-sharing systems (dividing the operation of the CPU into time piece). The year is probably: around 1965-1980.
4. The fourth generation:
The PC appeared, probably around 1980. I believe the typical representatives of this era: Bill Gates, Steve Jobs.
2. Computer working system
Although computers have evolved through four eras, as of today, the computer working system is still relatively simple. Generally speaking, our computers have five basic components.
1.MMU (memory control unit, implements memory paging [memory page])
The computing mechanism is independent of the CPU (computing control unit). There is a unique chip in the CPU called MMU. It is used to calculate the correspondence between the thread address and the physical address of the process. It is also used for access protection, that is, if a process first accesses a memory address that is not its own, it will be rejected!
2. Storage (memory)
3. Display device (VGA interface, monitor, etc.) [belongs to IO device]
4. Input device (keyboard, keyboard device ) [Belongs to IO device]
5. Hard disk device (Hard dish control, hard disk controller or adapter) [Belongs to IO device]
Expand little knowledge:
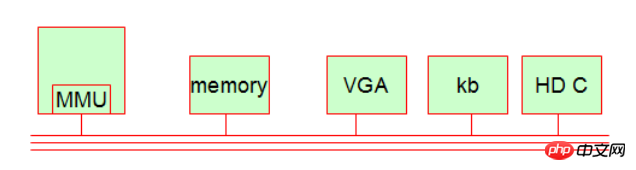
These hardware devices are linked on a bus, and they exchange data through this line. The leader inside is the CPU, which has the highest command authority. So how does it work?
A. Instruction fetching unit (fetching instructions from memory);
B. Decoding unit (complete decoding [converting data fetched from memory into instructions that the CPU can actually run]) ;
C. Execution unit (starts to execute instructions and calls different hardware to work according to the requirements of the instructions.);
We know from the above that MMU is part of the CPU, but the CPU Are there any other parts needed? Of course there are, such as instruction register chips, instruction counter chips, and stack pointers.
Instruction register chip: It is where the CPU takes out and stores the data in the memory;
Instruction counter chip: It is where the CPU records the last location where the data was fetched from the memory. It is convenient. Next value;
Stack pointer: Every time the CPU fetches an instruction, it will point the stack pointer to the location of the next instruction in memory.
Their working cycle is as fast as the CPU, and the working frequency of the CPU is at the same clock cycle, so its performance is very good, and data communication is completed on the CPU internal bus. Instruction register chip, instruction counter chip, stack pointer. These devices are usually called CPU registers.
The register is actually used to save the scene. This is especially evident in time multiplexing. For example, when the CPU is shared by multiple programs, the CPU will often terminate or suspend a process, and the operating system must save its current running status (so that the CPU can continue to process it when it comes back later). ) and then continue to run other processes (this is called a context switch of the computer).
3. Computer storage system.
1. Symmetric multiprocessor SMP
In addition to the MMU and registers (close to the CPU's working cycle), etc., the CPU also has a CPU core, which is specifically designed to process data. A CPU has multiple cores that can be used to run your code in parallel. Many companies in the industry use multiple CPUs. This structure is called a symmetric multiprocessor.
2. Principle of program locality
Spatial locality:
A program is composed of instructions and data. Spatial locality means that after one data is accessed, other data very close to the data may also be accessed subsequently.
Time locality:
Generally speaking, when a program is executed, it may be accessed soon. The same principle applies to data. Once a piece of data is accessed, it is likely to be accessed again.
It is precisely because of the existence of program locality that, generally speaking, we need to cache data whether it is considered from the perspective of spatial locality or temporal locality.
Expanded knowledge:
Since the register storage space inside the CPU is limited, memory is used to store data. However, since the speed of the CPU and the speed of the memory are not at the same level at all, so in processing Most of them are waiting when the data is returned (the CPU needs to fetch a piece of data from the memory, and it can be processed in one rotation of the CPU, while the memory may need to rotate 20 times). In order to improve efficiency, the concept of caching emerged.
Now that we know the principle of locality of the program, we also know that in order to obtain more space, the CPU actually uses time to exchange space, but the cache can directly let the CPU get the data, saving time, so When it comes to caching, it means using space to exchange time.
3. Even if you enter the storage system
uku\\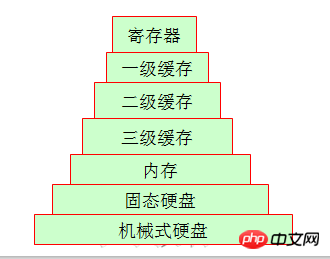
Friends who work during working hours may have seen tape drives, and now they are basically all Many companies are using hard disks to replace tape drives, so let’s look at the structure of the home computer we are most familiar with. The data is different from the last time it was stored. We can give a simple example. There is a big gap between their weekly storage cycles. Particularly obvious is the mechanical hard drive and memory. The gap between the two in terms of access is quite large.
Expand some knowledge:
Compared with your home desktop or laptop, you may have dismantled it yourself and talked about mechanical hard drives, solid-state drives or memory, etc. But maybe you haven't seen the cache physical device, but it is actually on the CPU. So there may be some blind spots in our understanding of it.
Let’s talk about the first-level cache and headphone cache. When their CPU fetches data there, the time period is basically not very long, because both the first-level cache and the second-level cache are internal resources of the CPU core. (Under the same hardware conditions, the market price of 128k L1 cache may be around 300 yuan, the market price of 256k L1 cache may be around 600 yuan, and the market price of 512k L1 cache may be over four digits. You can refer to JD.com for the specific price. This is enough to show that the cost of cache is very high!) At this time, you may ask what about the third-level cache? In fact, the third-level cache is the space shared by multiple CPUs. Of course, multiple CPUs also share memory.
die | 4. Non-uniform memory access (NUMA) 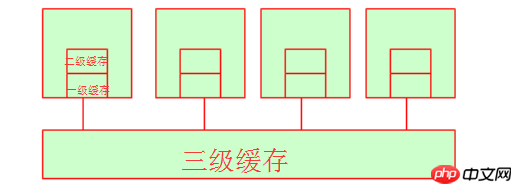
Yes, these hardware experts divide the three-level cache and let different CPUs occupy different memory addresses. In this way, we It is understandable that they all have their own level 3 cache area, and there will be no problem of resource grabbing, but it should be noted that they are still the same level 3 cache. Just like Beijing has Chaoyang District, Fengtai District, Daxing District, Haidian District, etc., but they are all part of Beijing. We can understand here. This is NUMA, and its characteristics are: non-uniform memory access, each has its own memory space. 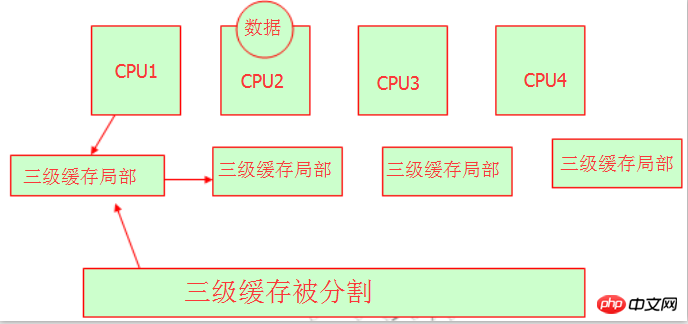
The place where the CPU processes data is to modify it in the register. When the register does not have the data it is looking for, it will go to the first-level cache to find it. If there is no data in the first-level cache The data will be found in the second-level cache, searched sequentially until it is found on the disk, and then loaded into the register. When the third-level cache fetches data from memory and finds that the third-level cache is insufficient, it will automatically clear the space in the third-level cache. 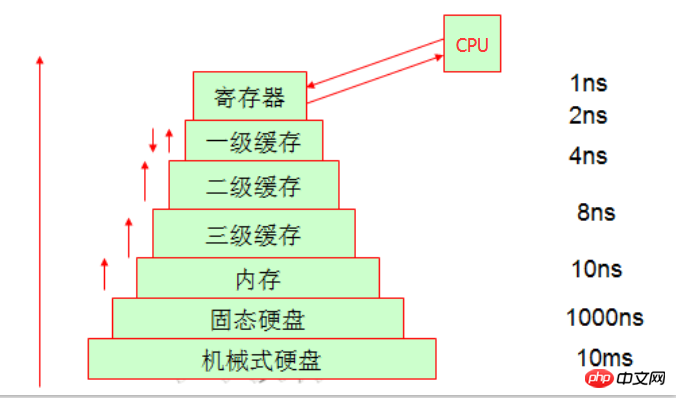
We know that the final location where data is stored is the hard disk, and this access process is completed by the operating system. When our CPU processes data, it writes data to different places through two writing methods, namely write-through (write to memory) and write-back (write to first-level cache). Obviously the write-back performance is good, but it will be embarrassing if the power is cut off, and the data will be lost, because it is written directly to the first-level cache, but other CPUs cannot access the first-level cache, so from the perspective of reliability From the perspective of writing, the general writing method will be more reliable. The specific method to use depends on your own needs.
4.IO device
1.IO device consists of the device controller and the device itself.
Device controller: a chip or a set of chips integrated on the motherboard. Responsible for receiving commands from the operating system and completing the execution of the commands. For example, it is responsible for reading data from the operating system.
The device itself: It has its own interface, but the interface of the device itself is not available, it is just a physical interface. Such as IDE interface.
Extended knowledge:
Each controller has a small number of registers for communication (ranging from a few to dozens). This register is integrated directly into the device controller. For example, a minimal disk controller will also be used to specify registers for disk addresses, sector counts, read and write directions, and other related operation requests. So any time you want to activate the controller, the device driver receives the operation instruction from the operating system, then converts it into the basic operation of the corresponding device, and places the operation request in the register to complete the operation. Each register behaves as an IO port. All register combinations are called the device's I/O address space, also called I/O port space,
2. Driver
The real hardware operation is completed by the driver operation. Drivers should usually be completed by the device manufacturer. Usually the driver is located in the kernel. Although the driver can run outside the kernel, few people do this because it is too inefficient!
3. Implement input and output
The I/O ports of the device cannot be assigned in advance because the models of each motherboard are inconsistent, so we need to dynamically assign them. When the computer is turned on, each IO device must register with the I/O port space of the bus to use the I/O port. This dynamic port is composed of all registers combined into the I/O address space of the device. There are 2^16 ports, that is, 65535 ports.
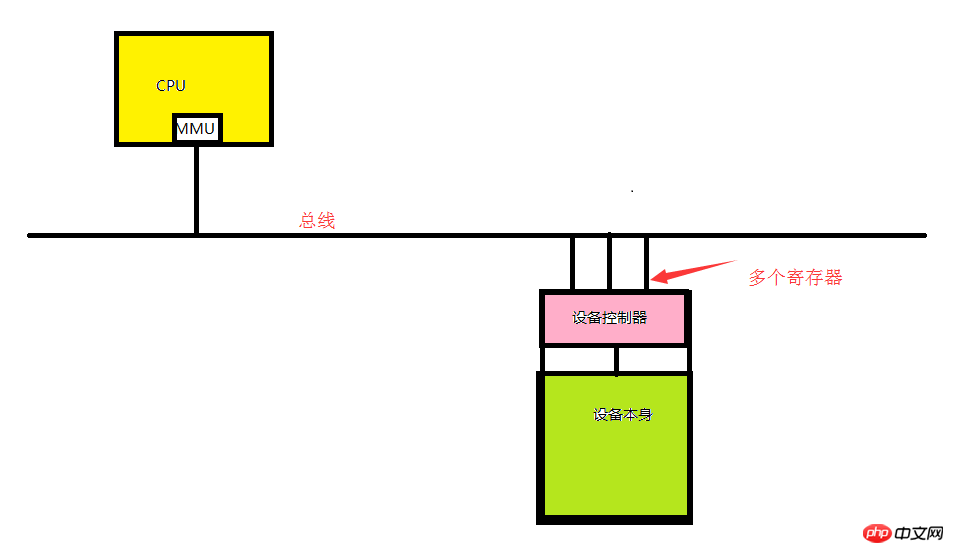
As shown in the figure above, if our CPU wants to deal with the specified device, it needs to pass the instructions to the driver, and then the driver will convert the CPU instructions into the device that can understand it. The signal is placed in a register (also called a socket). So the register (I/O port) is the address (I/O port) where the CPU interacts with the device through the bus.
Extended knowledge:
Three ways to implement input and output of I/O devices:
A..Polling:
Usually refers to The user program initiates a system call, and the kernel translates it into a procedure call corresponding to the kernel driver. Then the device driver starts I/O and checks the device in a continuous loop to see whether the device has completed its work. This is somewhat similar to busy waiting (that is, the CPU will use a fixed period to continuously check each I/O device through traversal to see if there is data. Obviously this efficiency is not ideal.),
B. .Interrupt:
Interrupt the program being processed by the CPU and interrupt the operation being performed by the CPU, thereby notifying the kernel to obtain an interrupt request. There is usually a unique device on our motherboard called a programmable interrupt controller. This interrupt controller can directly communicate with the CPU through a certain pin, and can trigger the CPU to deflect at a certain position, thereby letting the CPU know that a certain signal has arrived. There will be an interrupt vector on the interrupt controller (when each of our I/O devices starts, we want the interrupt controller to register an interrupt number. This number is usually unique. Usually each pin of the interrupt vector can identify multiple an interrupt number), which can also be called an interrupt number.
So when an interrupt actually occurs on this device, this device will not put data directly on the bus. This device will immediately issue an interrupt request to the interrupt controller. The interrupt controller identifies which request this request is through the interrupt vector. Sent by the device, it is then notified to the CPU in some way, letting the CPU know which device has reached the interrupt request. At this time, the CPU can use the I/O port number according to the device registration, so that the device data can be obtained. (Note that the CPU cannot directly fetch data, because it only receives the interrupt signal. It can only notify the kernel, let the kernel run on the CPU itself, and the kernel obtains the interrupt request.) For example, a network card receives For requests from external IPs, the network card also has its own cache area. The CPU takes the cache in the network card into the memory and reads it. It first determines whether it is its own IP. If it is, it starts to unpack the packet, and finally obtains a port number. Then the CPIU finds this port in its own interrupt controller and handles it accordingly.
Kernel interrupt processing is divided into two steps: the first half of the interrupt (processed immediately) and the second half of the interrupt (not necessarily). Let's take the example of receiving data from the network card. When the user request reaches the network card, the CPU will command the data in the network card cache area to be directly fetched into the memory. That is, the data will be processed immediately after receiving the data (the processing here is to transfer the data from the network card to the memory). It is just read into the memory without further processing to facilitate later processing.), this is called the upper part of the interrupt, and the part that actually processes the request is called the second half
C.DMA:
Direct memory access. Everyone knows that data transmission is implemented on the bus. The CPU is the user who controls the bus. Which I/O devices are using the bus at a certain time? It is determined by the CPU controller. The bus has three functions: address bus (to complete the addressing function of the device), control bus (to control the function of each device address using the bus) and data bus (to realize data transmission).
It is usually an intelligent control chip that comes with the I/O device (we call it the direct memory access controller). When the first half of the interrupt needs to be processed, the CPU will notify the DMA device to accept the The bus is used by the DMA device, and it is informed of the memory space that can be used to read the data of the I/O device into the memory space. When the DMA I/O device completes reading the data, it will send a message to tell the CPU that the reading operation has been completed. At this time, the CPU will notify the kernel that the data has been loaded. The specific processing of the second half of the interrupt will be handed over to the kernel. Dealt with it. Most devices now use DMA controllers, such as network cards, hard drives, etc.
5. Operating system concept
Through the above study, we know that a computer has five basic components. The operating system mainly abstracts these five components into a relatively intuitive interface, which is used directly by upper-level programmers or users. So what are the things that are actually abstracted in the operating system?
1.CPU (time slice)
In the operating system, the CPU is abstracted into time slices, and then the program is abstracted into processes, and the program is run by allocating time slices. The CPU has an addressing unit that identifies the collective memory address where the variable is stored in memory.
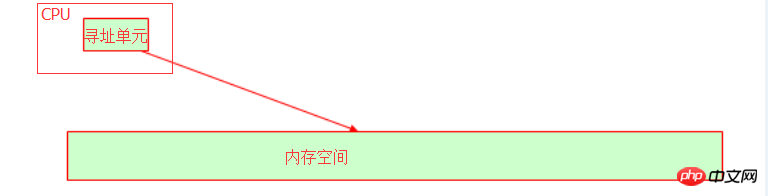
The internal bus of our host depends on the bit width (also called word length) of the CPU. For example, the 32-bit address bus can represent 2 to the 32nd power. The memory address, converted into decimal, is 4G memory space. At this time, you should understand why the 32-bit operating system can only recognize 4G memory, right? Even if your physical memory is 16G, the available memory is still 4G. Therefore, if you find that your operating system can recognize memory addresses above 4G, then your operating system must not be 32-bit!
2. Memory
In the operating system, memory is implemented through the virtual address space.
3.I/O device
In the operating system, the core I/O device is the disk. Everyone knows that the disk provides storage space. In the kernel, it is abstracted into file.
4. Process
To put it bluntly, isn’t the main purpose of a computer’s existence just to run programs? When the program runs, we call it a process (we don't need to worry about threads for the time being). If multiple processes are running at the same time, it means that these limited abstract resources (cpu, memory, etc.) are allocated to multiple processes. We refer to these abstract resources collectively as resource sets.
The resource set includes:
1>.cpu time;
2>. Memory address: abstracted into a virtual address space (such as a 32-bit operating system, supporting 4G space, The kernel occupies 1G of space, and the process will default to 3G of available space. In fact, there may not be 3G of space, because your computer may have less than 4G of memory)
3>.I/O: Everything is a file. To open multiple files, open the specified file through fd (file descriptor). We divide files into three categories: normal files, device files, and pipeline files.
Each process has its own job address structure, namely: task struct. It is a data structure maintained by the kernel for each process (a data structure is used to save data. To put it bluntly, it is the memory space, which records the resource set owned by the process, and of course its parent process, which saves the scene [ Used for process switching], memory mapping wait). The task struct simulates linear addresses and allows the process to use these linear addresses, but it records the mapping relationship between linear addresses and physical memory addresses.
5. Memory mapping - page frame
As long as it is not the physical memory space used by the kernel, we call it user space. The kernel will cut the physical memory of the user space into a fixed-size page frame (page frame). In Huanju words, it is a fixed-size storage unit, which is smaller than the default single storage unit (the default is one byte, that is, 8bit ) should be large. Typically one storage unit per 4k. Each page frame is allocated outward as an independent unit, and each page frame is also numbered. [For example: Assume that there is 4G space available, each page frame is 4K, and there are 1M page frames in total. 】These page frames are allocated to different processes.
We assume that you have 4G of memory, the operating system occupies 1G, and the remaining 3G of physical memory is allocated to user space. After each process is started, it will think that it has 3G space available, but in fact it cannot use up 3G at all. The memory written by the process is stored discretely. Wherever there is free memory, access it. Don't ask me about the specific access algorithm, I haven't studied it yet.
Process space structure:
1>.Reserved space
2>.Stack (variable storage place)
3>.Shared library
4>. Heap (open a file, where the data stream in the file is stored)
5>. Data segment (global static variable storage)
6>. Code Section
The storage relationship between processes and memory is as follows:
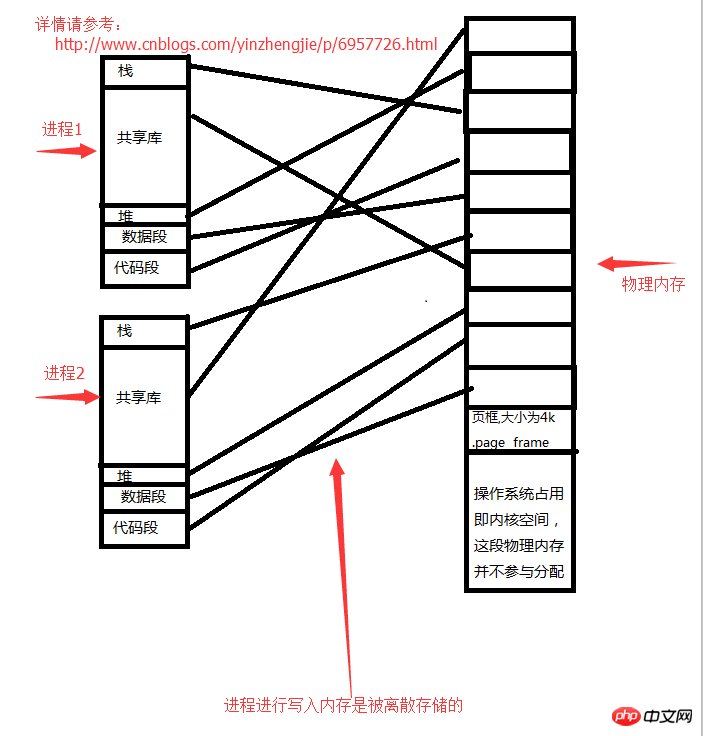
Each process space has reserved space. When a process finds that the data it has opened has been It is not enough, it needs to open a new file (opening a new file requires storing data in the address space of the process). Obviously, the process address space in the above picture is linear and not in the true sense. When a process actually applies for a memory, it needs to initiate a system call to the kernel. The kernel finds a physical space in the physical memory and tells the process the memory address that can be used. For example, if a process wants to open a file on the heap, it needs to apply for memory space from the operating system (kernel), and within the range allowed by physical memory (that is, the requested memory needs to be less than the free physical memory), the kernel will allocate it to the process. memory address.
Each process has its own linear address. This address is virtualized by the operating system and does not really exist. It needs to map this virtual address to the real physical memory, as shown in the figure "Process "Storage relationship with memory", the final storage location of process data is still mapped to the memory. This means that when a process runs to the CPU for execution, it tells the CPU its own linear address. At this time, the CPU will not directly find the linear address (because the linear address is virtual and does not really exist. The address process stores the physical memory address. ), it will first find the "task struct" of the process and load the page table [which records the mapping relationship between linear addresses and physical memory. Each corresponding relationship is called A page table entry. ] to read the real physical memory address corresponding to the linear address owned by the process.
Extended knowledge:
When the CPU accesses the address of a process, it first obtains the linear address of the process. It hands this linear address to its own chip MMU for calculation to obtain the real Physical memory address to achieve the purpose of accessing the process memory address. In other words, as long as he wants to access the memory address of a process, he must go through MMU operation, which results in very low efficiency. Therefore, they have introduced a cache to store frequently accessed data, so that the efficiency can be improved. The MMU performs calculations and gets the data directly for processing. We call this buffer: TLB: conversion back-up buffer (caching the query results of the page table)
Note: In a 32-bit operating system, Mapping of wire addresses to physical memory. In 64bit operating systems it is exactly the opposite!
6. User mode and kernel mode
In order to achieve coordinated multi-tasking when the operating system is running, the operating system is divided into two segments, one of which is close to the hardware and has privileged permissions. Kernel space, while the process runs in user space. Therefore, when an application needs to use privileged instructions or access hardware resources, it requires system calls.
As long as it is developed into an application program and does not exist as part of the operating system itself, we call it a user space program. Their running state is called user mode.
Programs that need to run in the kernel (we can think of it as the operating system) space, we call them running in the kernel space, and the state they run in is user mode, also called core mode. Note: The kernel is not responsible for completing the specific work. Available in kernel space to perform any privileged operations.
For every program to actually run, it must ultimately initiate a system call to the kernel, or some programs do not require the participation of the kernel and can be completed with our application. Let's use an analogy. If you want to calculate the result of 2 raised to the power of 32, do you need to run it in the kernel state? The answer is no. We know that the kernel is not responsible for completing specific work. We just want to calculate an operation result and do not need to call any privileged mode. Therefore, if you write some code about calculating values, you only need to This code can be handed over to the CPU to run.
If an application needs to call the function of the kernel instead of the function of the user program, the application will find that it needs to perform a privileged operation, and the application itself does not have this ability. The application will make an application to the kernel and ask the kernel to help. Complete privileged operations. The kernel finds that the application has permission to use privileged instructions. The kernel will run these privileged instructions and return the execution results to the application. Then the application will continue with subsequent code after getting the execution results of the privileged instructions. This is a paradigm shift.
Therefore, if a programmer wants to make your program productive, he should try to make your code run in user space. If most of your code runs in kernel space, it is estimated that your application will not It won’t bring you much productivity. Because we know that kernel space is not responsible for productivity.
Expanded knowledge:
We know that the operation of the computer is to run the specified. Instructions are also divided into privileged instruction level and non-privileged instruction level. Friends who know about computers may know that the CPU architecture of X86 is roughly divided into four levels. There are four rings from the inside to the outside, which are called ring 0, ring 1, ring 2, and ring 3. We know that the instructions in ring 0 are privileged instructions, and the instructions in ring 3 are user instructions. Generally speaking, the privileged instruction level refers to operating hardware, controlling the bus, etc.
The execution of a program requires the coordination of the kernel, and it is possible to switch between user mode and kernel mode. Therefore, the execution of a program must be scheduled by the kernel to the CPU for execution. Some applications are run during the operation of the operating system to complete basic functions. We let them run automatically in the background. This is called a daemon process. But some programs are only run when the user needs them. So how do we notify the kernel to run the applications we need? At this time, you need an interpreter, which can deal with the operating system and initiate the execution of instructions. To put it bluntly, it means that the user's running request can be submitted to the kernel, and then the kernel can open the basic conditions required for its operation. The program is then executed.
Related recommendations:
Understanding of threads in operating system knowledge
CPU interrupts under the Linux operating system
An example tutorial on security hardening of Linux operating system
The above is the detailed content of Basic principles of linux operating system. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



