

The following editor will bring you an article [The Road to a JS Master] on how to interpret HTML tags into DOM nodes. The editor thinks it’s pretty good, so I’ll share it with you now and give it as a reference. Let’s follow the editor to take a look.
I’ve been encapsulating an open source framework recently. I have written 500 lines. It already has most of the common functions of jquery. It will also expand a large number of tool functions and MVVM two-way driver functions later. . The usage method is exactly the same as jquery. Almost all jquery selectors are supported. Why does this have anything to do with the theme of this article? Because what this article is going to talk about is a problem I encountered in the process of writing a framework. It encapsulates the after method of jquery and supports two usages of DOM and html tags. The html tag passes parameters. I want to interpret html into a DOM structure. Use DOM method insertion.
First, we write a general html tag:
this is a test string
This html includes events, styles, attributes, and content.
We then use regular expressions to convert this html To match each part, what we need is:
1. Tag name, because
2 is needed when creating a dom node. Attributes and content must be separated separately
In order to facilitate the creation of dom, we use a json to save it, such as this tag. The final result we want to process is:
##
{
id:"test
inner:"this is a test string
name:"test"
onclick:"test();"
style:"color:red;background:green;"
tag:"p"
}##
var o = document.createElement( obj['tag'] );
o.innerHTML = obj['inner'];
delete obj['inner'];
delete obj['tag'];
for( var key in obj ){
o.setAttribute( key, obj[key] );
}
document.body.appendChild( o );var re = /<(\w+\s*)(\w+[=][\'\"](.*)?[\'\"]\s*)*>(.*)?<\/\w+>/; var str = '<p onclick="test();" name="test" id="test">this is a test string</p>'; var res = str.match(re);
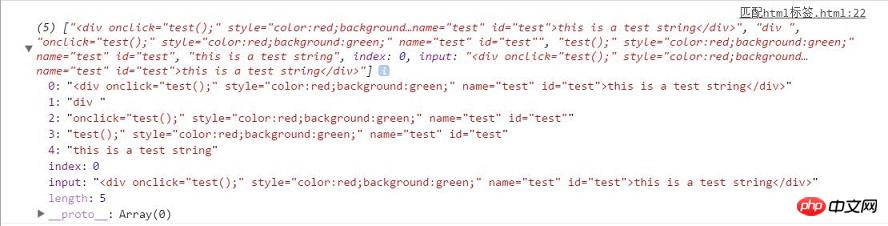 Well, this is the result of our matching, as can be seen from the picture,
Well, this is the result of our matching, as can be seen from the picture,
res[1] stores the label name. You only need to remove the spaces on both sides.
res[2] stores the attributes and values. We use the split function to cut it once by spaces, and then use The split function cuts once by '=' and it can be decomposed
res[4] stores the content of the string
The above three parts can be processed slightly with loops and strings You can get the target result
Then the complete processing code is:
var re = /<(\w+\s*)(\w+[=][\'\"](.*)?[\'\"]\s*)*>(.*)?<\/\w+>/;
var str = '<p onclick="test();" name="test" id="test">this is a test string</p>';
var res = str.match(re);
var tagName = null, attrList = [], arr = [], obj = {};
if( res[1] ) {
tagName = res[1].trim();
obj['tag'] = tagName;
}
if( res[4] ) {
obj['inner'] = res[4];
}
if ( res[2] ) {
attrList = res[2].split( /\s+/ );
for( var i = 0, len = attrList.length; i < len; i++ ){
arr = attrList[i].split("=");
// console.log( arr );
obj[arr[0]] = arr[1].replace( /(^[\'\"]+|[\'\"]$)/g, function(){
return '';
} );
}
}
var o = document.createElement( obj['tag'] );
o.innerHTML = obj['inner'];
delete obj['inner'];
delete obj['tag'];
for( var key in obj ){
o.setAttribute( key, obj[key] );
}
document.body.appendChild( o );The above is the detailed content of Examples to explain the interpretation of HTML tags into DOM nodes. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



