

1. ASII
American (national) Information Interchange Standard (code) code.
There are only numbers in the computer. Everything is represented by numbers, and the characters displayed on the screen are no exception.
The number that can be represented by one byte is 0-255, which is enough to display all the characters on the keyboard. For example, a is 97 and b is 98. This encoding rule corresponding to numbers and characters is called Asc11 code. The highest bits of ASC11 code are all 0, that is to say, the values of ASC11 code are between 0-127.
2. GB2312 and GBK (China’s local character set)
Mainland China uses 2 bytes to represent each Chinese character, and the Chinese character The highest bits of each section are all 1. This encoding format is called (gb2312) national standard code. Then the numbers corresponding to the gb2312 code are negative numbers.
On the basis of gb2312, some more are added, such as traditional Chinese characters, called GBK
Attachment:
GB18030 encoding is an expansion based on GBK encoding, because There are more Chinese characters, and only using two-digit encoding can no longer accommodate the required Chinese characters, so a 2\4-bit mixed method is adopted to support more Chinese character encodings.
3. ANSI
In order to expand ASCII coding to display the national language, different countries and regions have formulated different standards, resulting in GB2312 , BIG5, JIS and other respective coding standards. These various Chinese extended encoding methods that use 2 bytes to represent a character are called ANSI encoding, also known as "MBCS (Muilti-Bytes Charecter Set, multi-byte character set)". Under the Simplified Chinese system, ANSI encoding represents GB2312 encoding. Under the Japanese operating system, ANSI encoding represents JIS encoding. Therefore, to transcode to gb2312 under Chinese windows, gbk only needs to save the text as ANSI encoding. Different ANSI encodings are incompatible with each other.
4. Local character set
On the computer system used in mainland China, GBK and GB2312 are called the local character set of the system.
The Chinese character for "中国" is encoded in hexadecimal D6D0 in mainland China, and A4A4 in Taiwan. The encoding in Taiwan is called BIG5 Big Five code. When a character appears in the localization system of one country and is transmitted to the localization system of another country via email, what you see is not the original character, but the characters or garbled characters of another country.
5. Unicode encoding
The ISO organization has unified the symbols around the world and calls it Unicode encoding.
The symbol "中" is the hexadecimal 4e2d all over the world. If all computers use Unicode encoding, the word "中" will be displayed as "中" on computers all over the world. Unicode-encoded characters occupy two bytes, and the AC11 code represents The character simply adds a byte with all bits equal to 0 in front of the byte originally occupied by the AS11 code. The number of characters it represents will not exceed 65535. In fact, it still retains more than 2,000 Values are not used for encoding.
Unicode has not yet formed a unified world. For a long time, localized character encoding will coexist with Unicode encoding.
The characters in Java all use Unicode encoding.
Java also supports local platform character sets on the premise of ensuring cross-platform features through Unicode.
6. UTF-8
In the development process of Java language and other programs, especially XML also involves UTF-8 UTF-16. Unicode in a broad sense also includes UTF8 and utf-16
UTF-8
--ASC11 code characters remain intact and only occupy one byte.
--For characters from other countries, UTF-8 uses 2 or three bytes to represent them.
--Using UTF-8 encoded files, usually use EF BB BF as the three bytes of data at the beginning of the file.
7. Conversion rules between UTF-8 and unicode encoding
-- 0001-007f (one byte)
0xxxxxx
-- 0000 or its characters ranging from 0080 to 07ff,
110xxxxx 10xxxxxx (11 valid bits) (between 0080-07ff) A unicode has 16 bits, actually There are only 11 valid bits, the rest are flags.
-- Characters between 0800 and ffff, 1110xxxx 10xxxxxx 10xxxxxx (16 significant bits), the software can easily determine the occupied space of a character based on the fixed bit values in UTF-8 encoding One byte, two bytes, or three bytes.
8. Advantages of UTF-8
-- ox00 does not appear (in C language, \0 represents the end of the string, indicating that the character has been reached The end of the string) Unicode For ACS11 characters, it takes up two bytes, adding a byte with empty content (0x00), which is wasteful, and this byte has special applications in C language and other programs.
-- It is convenient for applications to check whether errors have occurred during data transmission. It can check whether errors have occurred during data transmission.
-- Directly process documents using ASC11
9. China Unicom, Lenovo and United
Enter Unicom Lenovo, United, View in Notepad .You will see some error situations respectively

Unicom (or contact) garbled characters
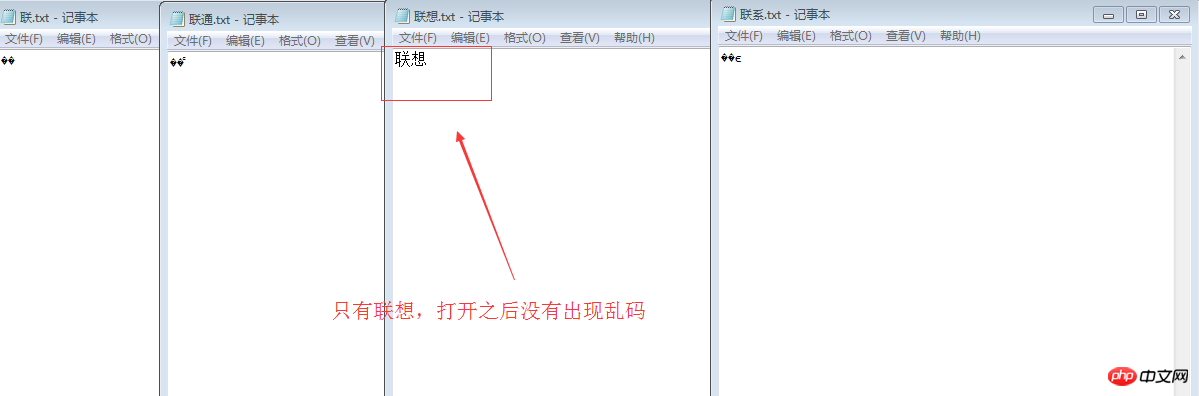
Open with ue, check the hexadecimal, they are C1AA CDA8 C1AA CFE8 //These are all using GB2312 encoding. If it is medium, it is D6D0, that is, C1AA is the link CDA8 is the same as CFE8. The binary representation of it can be obtained in the following way:
int x=0xCDA8; System.out.println(Integer.toBinaryString(x) );
//11000001 10101010 Link 11001101 10101000 Through the file in
Notepad, the default is the Chinese character set GB2312 is used to store Zhu, so the character "Lian" is parsed into 1100 0001 1010 1010, and the character "通" is stored as 1100 1101 1010 1000. When the Notepad document is opened, these binary forms happen to correspond. UTF-8 rules, so the system thinks this is a UTF-8 encoded file and interprets it according to UTF-8. Garbled characters appear. The solution: when saving, press UTF-8 directly to save and it will not appear. .
10. Use the program to check the character encoding
View the GB2312 code of Chinese characters
View the UTF-8 code of Chinese characters
View the Unicode code of Chinese characters
public static void main(String[] args) throws UnsupportedEncodingException {
String str="中国"; //查看字符的unicode码,将一个字符转成整数,得到的就是unicode值/* for(int i=0;i<str.length();i++){
int unicodeCode=str.charAt(i);
System.out.println(unicodeCode); // 20013,22269
System.out.println(Integer.toHexString(unicodeCode)); //对应的16进制 4e2d,56fd
}*///查看字符的gb2312码byte [] buff =str.getBytes("gb2312"); for(int i=0;i<buff.length;i++){
System.out.println(buff[i]); // -42,-48, -71,-6System.out.println(Integer.toHexString(buff[i])); //ffffffd6 ,ffffffd0 ffffffb9,fffffffa }
}
The above is the detailed content of Character encoding for basic introduction to Java. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



