


Catch all news inquiries from the official website of Sichuan University School of Public Administration ().
1. Determine the crawling target.
2. Develop crawling rules.
3. 'Write/Debug' crawling rules.
4. Obtain crawling data
The target we need to crawl this time is Sichuan All the news and information of the University School of Public Administration. So we need to know the layout structure of the official website of the School of Public Administration.
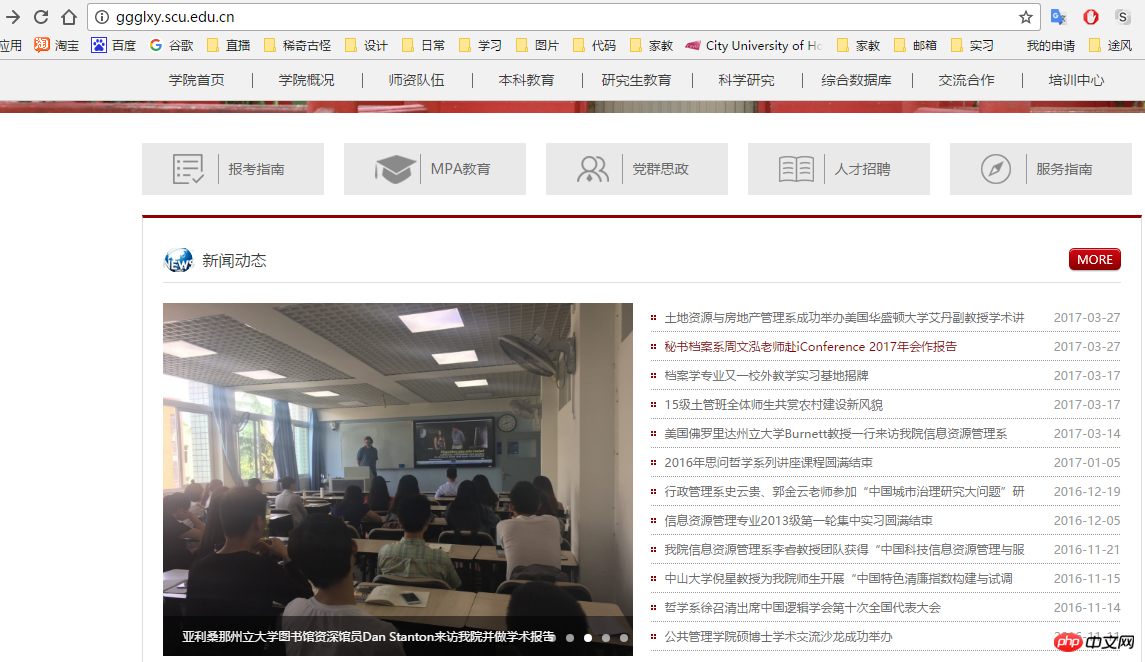
 ##Paste_Image .png
##Paste_Image .png
2. Formulate the crawling rules
 Paste_Image.png
Paste_Image.pngOkay , now we have a clear idea of grabbing a piece of news. But, how to crawl all the news content?
This is obviously not difficult for us.
So to sort out the ideas, we can think of An obvious crawling rule:
3.'Writing/Debugging' Crawl rules
2. Enter the news details through the crawled news link on the page to crawl the required data (mainly news content)1.Crawl out the basic data under a page.3 .Crawl all the news through a loop.
The corresponding knowledge points are:
2 .Crawl twice through the crawled data.3.Crawl all data on the web page through a loop.
Without further ado, let’s get started now.
3.1 Climb out all the news links under the news column on one page
 Paste_Image.png
Paste_Image.png Paste_Image.png
Paste_Image.pngWriting code
import scrapyclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first()) Paste_Image.png
Paste_Image.pngWriting code
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):item = GgglxyItem()item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()item['href'] = responseitem['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")item['content'] = data[0].xpath('string(.)').extract()[0]
yield itemimport scrapyfrom ggglxy.items import GgglxyItemclass News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())#调用新闻抓取方法yield scrapy.Request(url, callback=self.parse_dir_contents)#进入新闻详情页的抓取方法 def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]yield itemTest, passed!
 Paste_Image.png
Paste_Image.pngNEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUM
yield scrapy.Request(next_url, callback=self.parse)Add to the original code :
import scrapyfrom ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())yield scrapy.Request(URL, callback=self.parse_dir_contents)global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield itemTest:
 Paste_Image.png
Paste_Image.png抓到的数量为191,但是我们看官网发现有193条新闻,少了两条.
为啥呢?我们注意到log的error有两条:
定位问题:原来发现,学院的新闻栏目还有两条隐藏的二级栏目:
比如:

对应的URL为

URL都长的不一样,难怪抓不到了!
那么我们还得为这两条二级栏目的URL设定专门的规则,只需要加入判断是否为二级栏目:
if URL.find('type') != -1: yield scrapy.Request(URL, callback=self.parse)
组装原函数:
import scrapy
from ggglxy.items import GgglxyItem
NEXT_PAGE_NUM = 1class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = ["http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=1",
]def parse(self, response):for href in response.xpath("//div[@class='newsinfo_box cf']"):
URL = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())if URL.find('type') != -1:yield scrapy.Request(URL, callback=self.parse)yield scrapy.Request(URL, callback=self.parse_dir_contents)
global NEXT_PAGE_NUM
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1if NEXT_PAGE_NUM<11:
next_url = 'http://ggglxy.scu.edu.cn/index.php?c=special&sid=1&page=%s' % NEXT_PAGE_NUMyield scrapy.Request(next_url, callback=self.parse) def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0] yield item测试:

我们发现,抓取的数据由以前的193条增加到了238条,log里面也没有error了,说明我们的抓取规则OK!
<code class="haxe"> scrapy crawl <span class="hljs-keyword">new<span class="hljs-type">s_info_2 -o <span class="hljs-number">0016.json</span></span></span></code><br/><br/>
The above is the detailed content of Scrapy captures college news report examples. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



