


1. python version 2.7.13. The blog codes are all this version
2. System environment: win7 64-bit system
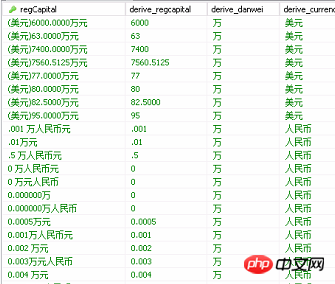
Some data screenshots are as follows. The first field is the original field, and the next three are the cleaned fields. Observing the aggregated fields in the database, at first glance, the data is relatively regular, similar to (currency amount Ten thousand yuan) In this way, I thought about using SQL to write conditional judgments and convert them uniformly into the unit of 'ten thousand yuan'. I could use a SQL script to intercept the string. However, I later found that the data was irregular and there were too many conditional judgments and the cleaning quality was not good. Of course, some do not have left brackets in front of them, some fields do not have currency in them, some numbers are not integers, and some do not have 10,000 characters. In this way, if the two fields are stored as numbers and '10,000 yuan' unit, it will be complicated to write the SQL script. I haven’t found a function in mysql that can extract numbers from text. Regular expressions are often used in where conditions. If anyone knows that mysql has a function similar to filtering text to extract numbers from text, can you tell me, so that you don’t have to spend so much money. For a lot of effort, just use Kettle as a tool. It is best to learn and use the tool flexibly.
Combined with the experience of using python, python has many functions for string filtering. This method is used in the later code to filter text.
When you get the data, don’t rush to write the code first. Think about the logic of cleaning first. This is very important. If you go in the right direction, you will get twice the result with half the effort. The rest of the time is code. The process of implementing logic and debugging code.
The final data cleaning I want to achieve is to convert the fund field into a combination of [amount + unit + each currency] or [amount + unit] + Unified RMB currency] (currency exchange rate conversion), it can be done in two or three steps
(Units are divided into tens of thousands and excluding ten thousand, currencies are divided into RMB and specific foreign currencies)
The unit in the first step is not The digital part of ten thousand/10000, the digital part of ten thousand remains unchanged
The currency is RMB, the first two fields remain unchanged, no The numerical part is changed to a number * the exchange rate of each foreign currency to RMB, the unit remains unchanged and is still the unified 'ten thousand' in the second step
From this Let’s dismantle the results step by step, first sort out the cleaning logic part
①Field value = " 2000 RMB", the first cleaning is 2000 not including 10,000 RMB
②Field value = "20 million RMB", the first cleaning is 2000 10,000 RMB
③ Field value = "20 million yuan in foreign currency", the first cleaning 2000 million foreign currency
#二次处理条件case when 单位=‘万’ then 金额 else 金额/10000 end as 第二次金额
①Field value = “2000 RMB”0.2 Ten thousand RMB
②Field value =”20 million RMB”2000 10,000 RMB
③Field value = "20 million yuan in foreign currency"2000 10,000 RMB in foreign currency
Note: If the above requirements are met, the cleaning will be completed. If If you want to convert the unit into RMB, perform the following three cleanings
If the final requirement is to convert into currency To unify the RMB, then we can just write the conditions based on the second cleaning,
#三次处理条件case when 币种=‘人民币’ then 金额 else 金额*币种和人民币的换算汇率 end as 第三次金额
①Field value = "2000 RMB"0.2 million RMB
②Field value = "20 million yuan" 2000 million yuan
③Field value = "20 million yuan in foreign currency"2000*Foreign currency exchange rate for RMB million yuan
Currency and unit are two situations, easy to write
This condition is simple. If the value of currency appears in the character, just make the new field equal to the value of this currency.
This condition is also simple. If the word ten thousand appears in the character, the unit variable ='ten thousand'. If it does not appear, let the unit variable equal to 'excluding ten thousand'. This is written to make it easier to write conditional judgments when performing secondary processing on numbers in the next step.
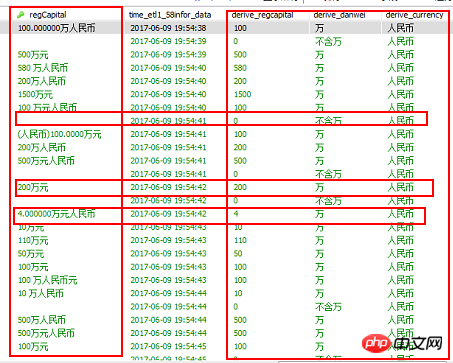
Ensure that the logical value after cleaning is the same as the original value. This means that if there is such a field, 300.01 million becomes 300.01 after cleaning. Ten thousand yuan is also correct.
filter(str.isdigit, field value)In this code, I first know that the numbers in the text can be taken out, and the fields with decimal points can be taken out by group by aggregation of the fields. The value no longer has a decimal point, such as '200,100', filter(str.isdigit,'200,100')The number taken out is 2001. Obviously this number is incorrect, so you need to consider whether there is a decimal point If there is a decimal point, make sure it is the same as the original field
Extract about 10 outliers from the database for testing , info is the value of the regCapital field
#带小数点的以小数点分割 取出小数点前后部分进行拼接if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])
elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])
elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)#单位 以万和不含万 为统一if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万' #币种 第一次清洗 外币保留外币字段 聚合大量数据 发现数据中含有外币的情况大致有下面这些情况 如果有新外币出现 进行数据的update操作即可if '美元' in info:
derive_currency='美元'
elif '港币' in info:
derive_currency = '港币'
elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'
elif '澳元' in info:
derive_currency = '澳元'
elif '英镑' in info:
derive_currency = '英镑'
elif '加拿大元' in info:
derive_currency = '加拿大元'
elif '日元' in info:
derive_currency = '日元'
elif '港币' in info:
derive_currency = '港币'
elif '法郎' in info:
derive_currency = '法郎'
elif '欧元' in info:
derive_currency = '欧元'
elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'The fourth step is to test some of the data and verify that the code is correct. At this time The logic should be expanded from a macro perspective, and the info variable should be dynamically changed to all the values in the database for full cleaning
#coding:utf-8from class_mysql import Mysql
project=Mysql('s_58infor_data',[],0,conn_type='local')
p2=Mysql('etl1_58infor_data',[],24,conn_type='local')
field_list=p2.select_fields(db='local_db',table='etl1_58infor_data')print field_list
project2=Mysql('etl1_58infor_data',field_list=field_list,field_num=26,conn_type='local')#以上部分 看不懂没关系 由于我有两套数据库环境,测试和生产#不同的数据库连接和网段,因此要传递不同的参数进行切换数据库和数据连接 如果一套环境 连接一次数据库即可 数据处理需要经常做测试 方便自己调用
data_tuple=project.select(db='local_db',id=0)#data_tuple 是我实例化自己写的操作数据库的类对数据库数据进行全字段进行读取,返回值是一个不可变的对象元组tuple,清洗需要保留旧表全部字段,同时增加3个清洗后的数据字段
data_tuple=project.select(db='local_db',id=0)#遍历元组 用字典去存储每个字段的值 插入到增加3个清洗字段的表 etl1_58infor_datafor data in data_tuple:
item={}#old_data不取最后一个字段 是因为那个字段我想用当前处理的时间
#这样可以计算数据总量运行的时间 来调整二次清洗的时间去和和kettle定时任务对接#元组转换为列表 转换的原因是因为元组为不可变类型 如果有数据中有null值 遍历转换为字符串会报错
old_data=list(data[:-1])if data[-2]:if len(data[-2]) >0 :
info=data[-2].encode('utf-8')else:
info=''if '.' in info and int(filter(str.isdigit,info.split('.')[1]))>0:
derive_regcapital=filter(str.isdigit,info.split('.')[0])+'.'+filter(str.isdigit,info.split('.')[1])elif '.' in info and int(filter(str.isdigit,info.split('.')[1]))==0:
derive_regcapital = filter(str.isdigit, info.split('.')[0])elif filter(str.isdigit,info)=='':
derive_regcapital='0'else:
derive_regcapital=filter(str.isdigit,info)if '万' in info:
derive_danwei='万'else:
derive_danwei='不含万'if '美元' in info:
derive_currency='美元'elif '港币' in info:
derive_currency = '港币'elif '阿富汗尼' in info:
derive_currency = '阿富汗尼'elif '澳元' in info:
derive_currency = '澳元'elif '英镑' in info:
derive_currency = '英镑'elif '加拿大元' in info:
derive_currency = '加拿大元'elif '日元' in info:
derive_currency = '日元'elif '港币' in info:
derive_currency = '港币'elif '法郎' in info:
derive_currency = '法郎'elif '欧元' in info:
derive_currency = '欧元'elif '新加坡' in info:
derive_currency = '新加坡元'else:
derive_currency = '人民币'
time_58infor_data = p2.create_time()
old_data.append(time_58infor_data)
old_data.append(derive_regcapital)
old_data.append(derive_danwei)
old_data.append(derive_currency)#print len(old_data)for i in range(len(old_data)):if not old_data[i] :
old_data[i]=''else:pass
data2=old_data[i].replace('"','')
item[i+1]=data2print item[1] #插入测试环境 的表
project2.insert(item=item,db='local_db')
The red box part is the cleaning part, and other data has been desensitized
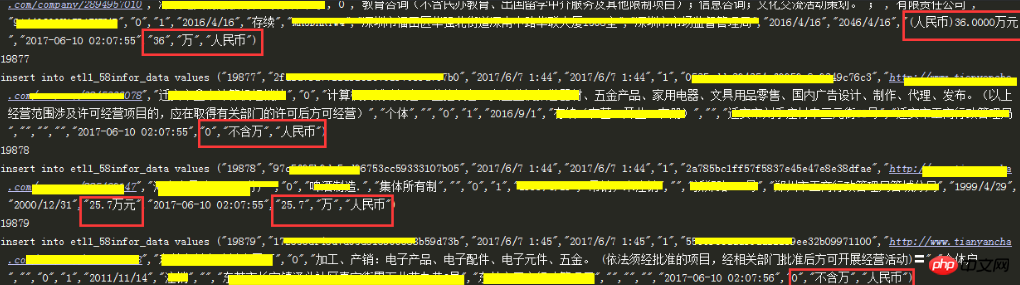
由于每天数据有增量进入,因此第一次执行完初始话之后,我们要根据表中的时间戳字段进行判断,读取昨日新的数据进行清洗插入,这部分留到下篇博客。
初步计划用下面函数 作为参数 判断增量 create_time 是爬虫脚本执行时候写入的时间,yesterday是昨日时间,在where条件里加以限制,取出昨天进入数据库的数据 进行执行 win7系统支持定时任务
import datetimefrom datetime import datetime as dt#%进行转义使用%%来转义#主要构造sql中条件“where create_time like %s%%“ % yesterday#写入脚本运行的当前时间
def create_time(self):
create_time = dt.now().strftime('%Y-%m-%d %H:%M:%S')return create_timedef yesterday(self):
yestoday= datetime.date.today()-datetime.timedelta(days=1)return yestodayThe above is the detailed content of Python processing examples of messy text data. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



