

Note: This link mainly experiences the macro concept and processing process of the data analysis system, and initially understands the application links ofhadoopand other frameworks. Don’t pay too much attention. Code details
A widely used data analysis system:"webLog data mining"
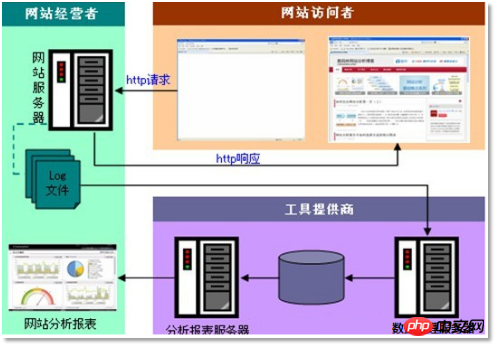
"Website orAPPClickstream Log Data Mining System".
“Web"Clickstream log" contains very important information for website operation. Through log analysis, we can know the number of visits to the website, which webpage has the most visitors, which webpage is the most valuable, advertising conversion rate, visitor source information, and visitor terminal information. wait.
The data of this case is mainly composed ofUser’s click behavior record
How to obtain: Pre-embed ajsprogram on the page for the page you want to monitor Label binding event, as long as the user clicks or moves to the label, it can trigger theajaxrequest to the backgroundservletprogram, uselog4jRecord event information to thewebserver (nginx,tomcat, etc.), a growing log file is formed.
Form:
This case is very similar to the typicalBIsystem, the overall process As follows:

handles massive amounts of data. Therefore, the technologies used in each link of the process are completely different from traditionalBI. Subsequent courses will explain them one by one:1)Data collection: Customized development of the collection program, or using the open source frameworkFLUME
2)Data preprocessing: Customized developmentmapreduce
hadoopCluster3)Data warehouse technology:
# based onhadoop##4)Data export:sqoop
data import and export tool based onhadoop5)Data visualization: Customized development ofwebprograms or the use of
kettleand other products6)The entire process Process scheduling:hadoop#oozie
tools in thehadoopecosystem or other similar open source products3.2.2
 3.2.3
3.2.3

Query data in

##c)
mysql
##./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-03
| ##58.215.204.118 - - [18/Sep/2013:06: 51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0" |
3.3
Final effect of the projectThe effect is as follows:
The above is the detailed content of Introduction to offline data analysis process. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



