


The reason why HashSet and HashMap are explained together is because they have the same implementation in Java, and the former is just for The latter has a layer of packaging, which means that HashSet has a HashMap (adapter mode) inside. Therefore, this article will focus on analyzing HashMap.
HashMap implements the Map interface, allowing null elements to be put in. Except that this class does not implement synchronization, the rest is the same as Hashtable is roughly the same, but different from TreeMap, this container does not guarantee the order of elements. The container may re-hash the elements as needed, and the order of the elements will also be re-shuffled, so iterations at different times are the same. The order of a HashMap may vary.
According to different ways of handling conflicts, there are two ways to implement hash tables, one is the open addressing method (Open addressing), the other is the conflict linked list method (Separate chaining with linked lists). Java HashMap uses the conflict linked list method.
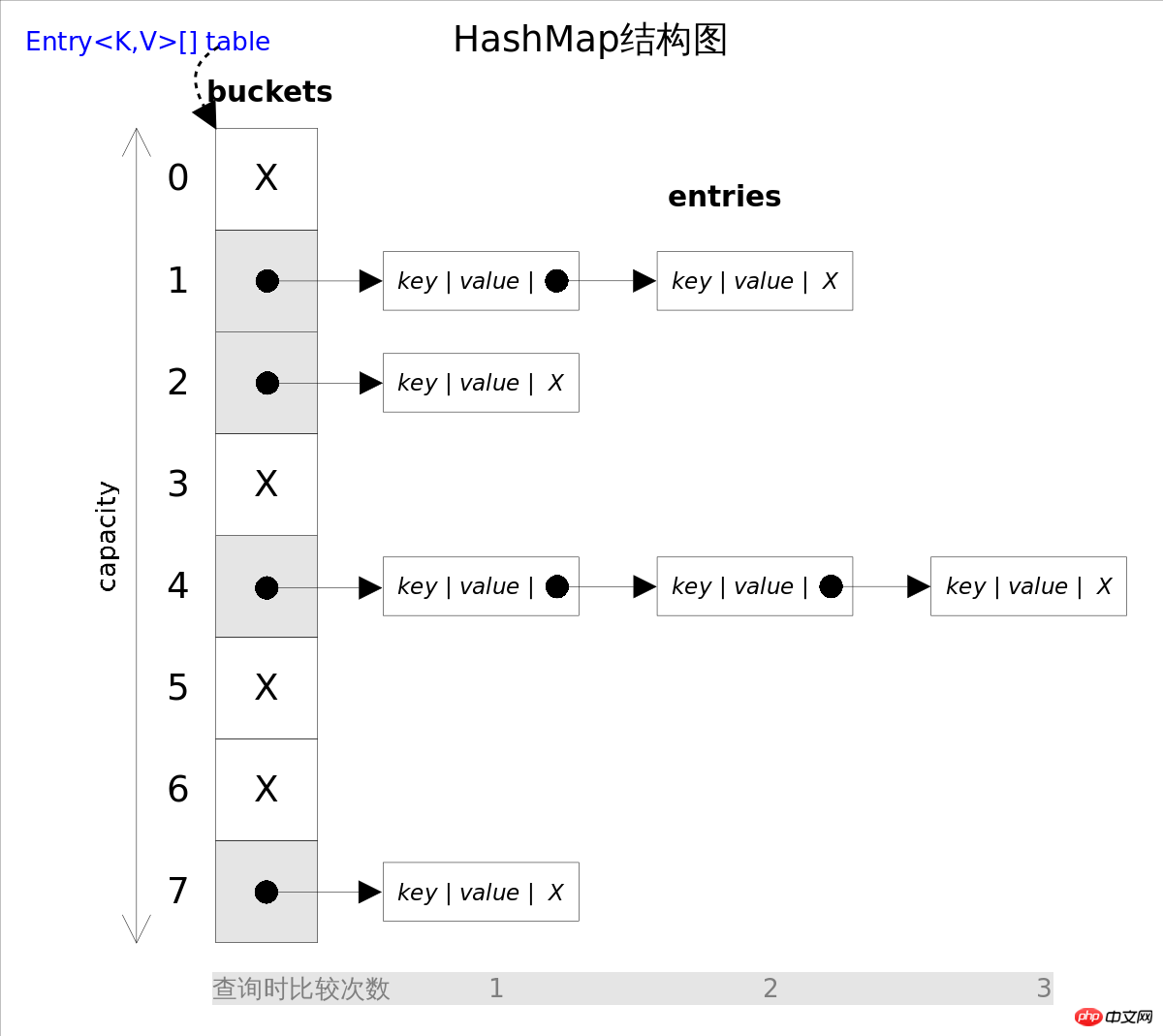
It is easy to see from the above figure that if you choose the appropriate hash function , put() and get ()Method can be completed in constant time. But when iterating HashMap, you need to traverse the entire table and the conflict linked list that follows. Therefore, for scenarios with frequent iterations, it is not appropriate to set the initial size of HashMap too large.
There are two parameters that can affect the performance of HashMap: initial capacity and load factor. The initial capacity specifies the size of the initial table, and the load factor is used to specify the critical value for automatic expansion. When the number of entry exceeds capacity*load_factor, the container will automatically expand and rehash. For scenarios where a large number of elements are inserted, setting a larger initial capacity can reduce the number of rehashes.
When putting the object into HashMap or HashSet, there are two methods that require special attention: hashCode() and equals(). hashCode()The method determines which bucket the object will be placed in. When the hash values of multiple objects conflict, The equals() method determines whether these objects are "the same object" . Therefore, if you want to put a custom object into HashMap or HashSet, you need @Override hashCode() and equals()method.
get(<a href="//m.sbmmt.com/wiki/60.html" target="_blank">Object</a> <a href="//m.sbmmt.com/wiki/1051.html" target="_blank">key</a>)The method is based on the specified The key value returns the corresponding value. This method calls getEntry(Object key) to get the corresponding entry, and then returns entry.getValue(). Therefore getEntry() is the core of the algorithm.
The algorithm idea is to first obtain the subscript corresponding to bucket through the hash() function, and then traverse the conflict linked list in sequence, and pass key.equals(k) Method to determine whether it is the one you are looking for entry.
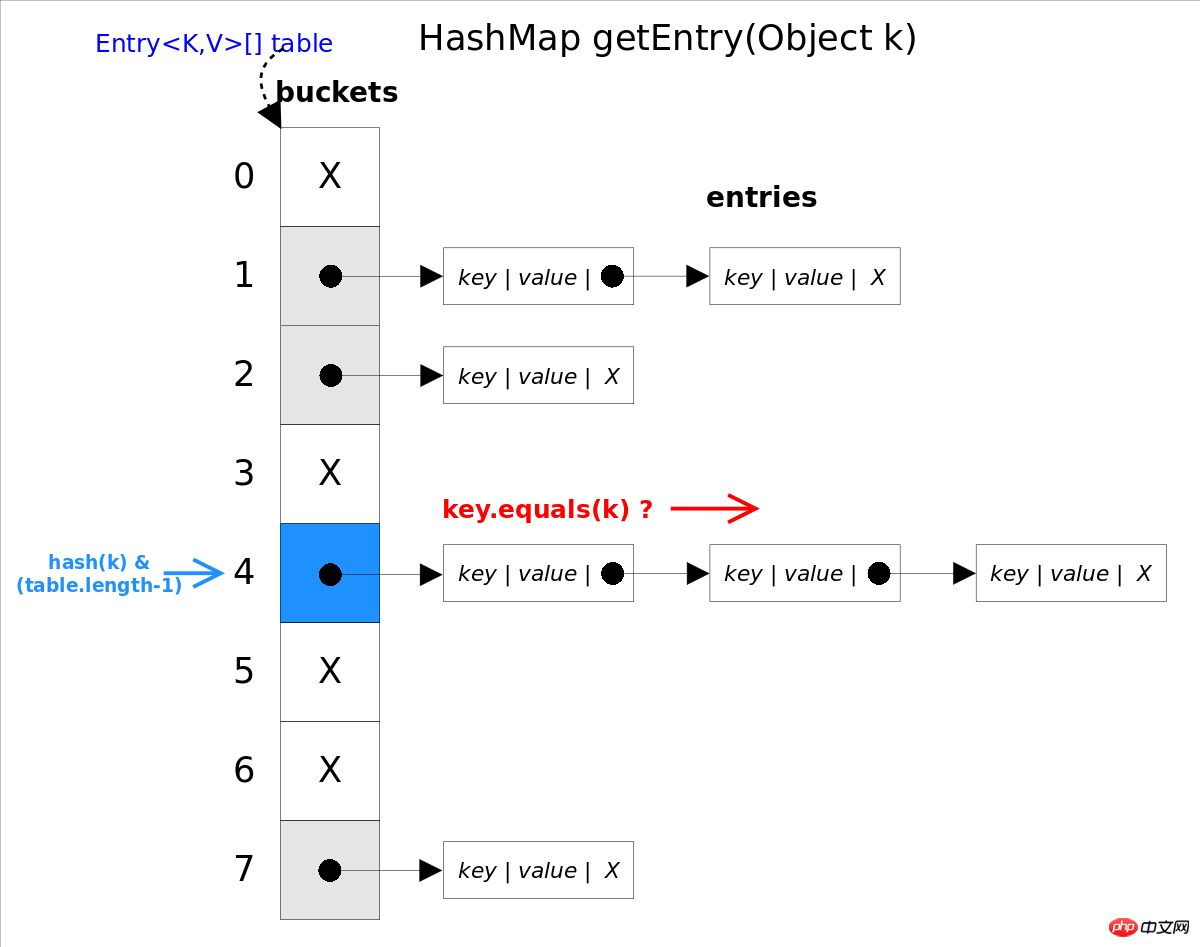
In the above figure, hash(k)&(table.length-1) is equivalent to hash(k)%table.length , the reason is that HashMap requires that table.length must be an exponent of 2, so table.length-1 means that the binary low bits are all 1, followed by hash(k)The addition will erase all the high bits of the hash value, and the remainder is the remainder.
//getEntry()方法
final Entry<K,V> getEntry(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[hash&(table.length-1)];//得到冲突链表
e != null; e = e.next) {//依次遍历冲突链表中的每个entry
Object k;
//依据equals()方法判断是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}put(K key, V value)The method is to add the specified key, value pair to map. This method will first search map to see if it contains the tuple. If it is included, it will return directly. The search process is similar to the getEntry() method; if it is not found, then A new entry will be inserted through the addEntry(int hash, K key, V value, int bucketIndex) method, and the insertion method is head insertion method.
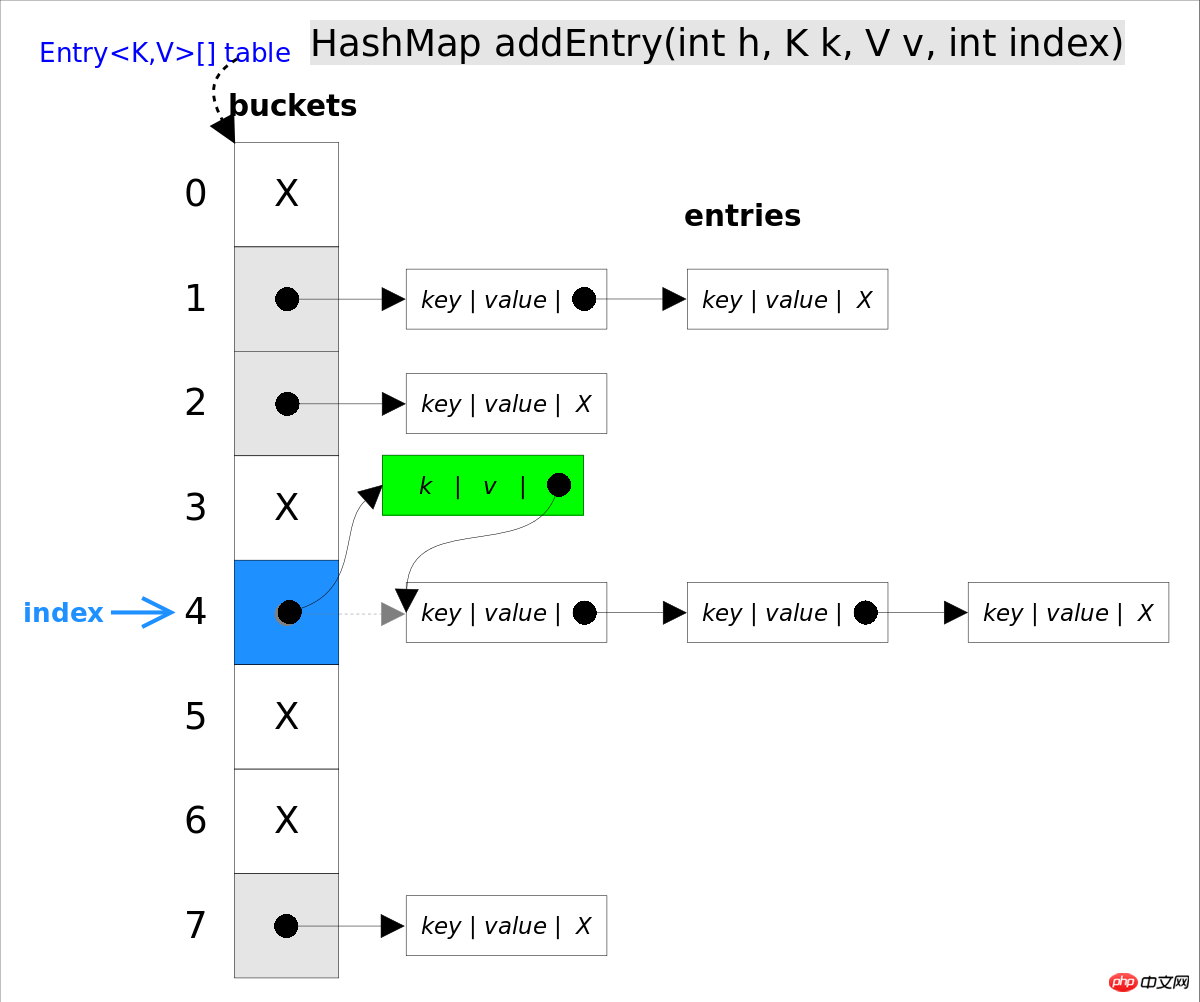
//addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//自动扩容,并重新哈希
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);//hash%table.length
}
//在冲突链表头部插入新的entry
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}remove(Object key) is used to delete the key corresponding to the key value entry, the specific logic of this method is implemented in removeEntryForKey(Object key). The removeEntryForKey() method will first find the entry corresponding to the key value, and then delete the entry (modify the corresponding pointer of the linked list). The search process is similar to the getEntry() process.

//removeEntryForKey()
final Entry<K,V> removeEntryForKey(Object key) {
......
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);//hash&(table.length-1)
Entry<K,V> prev = table[i];//得到冲突链表
Entry<K,V> e = prev;
while (e != null) {//遍历冲突链表
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {//找到要删除的entry
modCount++; size--;
if (prev == e) table[i] = next;//删除的是冲突链表的第一个entry
else prev.next = next;
return e;
}
prev = e; e = next;
}
return e;
}前面已经说过HashSet是对HashMap的简单包装,对HashSet的函数调用都会转换成合适的HashMap方法,因此HashSet的实现非常简单,只有不到300行代码。这里不再赘述。
//HashSet是对HashMap的简单包装
public class HashSet<E>
{
......
private transient HashMap<E,Object> map;//HashSet里面有一个HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
......
public boolean add(E e) {//简单的方法转换
return map.put(e, PRESENT)==null;
}
......
}The above is the detailed content of Detailed analysis of Java collection framework HashSet and HashMap source code (picture). For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



