


In the first part, there is a brief introduction to the basic situation of MyCAT construction and configuration files. This article details some specific parameters of the schema and its actual function
Post it first In the schema file used for my own testing, the backslash before the double quotation mark will not be eliminated. Let’s pretend it does not exist...
<?xml version=\"1.0\"?>
<!DOCTYPE mycat:schema SYSTEM \"schema.dtd\">
<mycat:schema xmlns:mycat=\"http://org.opencloudb/\">
<schema name=\"mycat\" checkSQLschema=\"false\" sqlMaxLimit=\"100\">
<!-- auto sharding by id (long) -->
<table name=\"students\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule1\" />
<table name=\"log_test\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule2\" />
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<!--<table name=\"company\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3\" />
<table name=\"goods\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2\" />
-->
<table name=\"item_test\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3,dn4\" />
<!-- random sharding using mod sharind rule -->
<!-- <table name=\"hotnews\" primaryKey=\"ID\" dataNode=\"dn1,dn2,dn3\"
rule=\"mod-long\" /> -->
<!--
<table name=\"worker\" primaryKey=\"ID\" dataNode=\"jdbc_dn1,jdbc_dn2,jdbc_dn3\" rule=\"mod-long\" />
-->
<!-- <table name=\"employee\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\" />
<table name=\"customer\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\">
<childTable name=\"orders\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\">
<childTable name=\"order_items\" joinKey=\"order_id\"
parentKey=\"id\" />
<ildTable>
<childTable name=\"customer_addr\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\" /> -->
</schema>
<!-- <dataNode name=\"dn\" dataHost=\"localhost\" database=\"test\" /> -->
<dataNode name=\"dn1\" dataHost=\"localhost\" database=\"test1\" />
<dataNode name=\"dn2\" dataHost=\"localhost\" database=\"test2\" />
<dataNode name=\"dn3\" dataHost=\"localhost\" database=\"test3\" />
<dataNode name=\"dn4\" dataHost=\"localhost\" database=\"test4\" />
<!--
<dataNode name=\"jdbc_dn1\" dataHost=\"jdbchost\" database=\"db1\" />
<dataNode name=\"jdbc_dn2\" dataHost=\"jdbchost\" database=\"db2\" />
<dataNode name=\"jdbc_dn3\" dataHost=\"jdbchost\" database=\"db3\" />
-->
<dataHost name=\"localhost\" maxCon=\"100\" minCon=\"10\" balance=\"1\"
writeType=\"1\" dbType=\"mysql\" dbDriver=\"native\">
<heartbeat>select user()<beat>
<!-- can have multi write hosts -->
<writeHost host=\"localhost\" url=\"localhost:3306\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS1\" url=\"localhost:3307\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
<writeHost host=\"localhost1\" url=\"localhost:3308\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS11\" url=\"localhost:3309\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
</dataHost>
<!-- <writeHost host=\"hostM2\" url=\"localhost:3316\" user=\"root\" password=\"123456\"/> -->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"1\" balance=\"0\" writeType=\"0\" dbType=\"mongodb\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM\" url=\"mongodb://192.168.0.99/test\" user=\"admin\" password=\"123456\" ></writeHost>
</dataHost>
-->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"10\" balance=\"0\"
dbType=\"mysql\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM1\" url=\"jdbc:mysql://localhost:3306\"
user=\"root\" password=\"123456\">
</writeHost>
</dataHost>
-->
</mycat:schema># The first line of parameters<schema name="mycat" checkSQLschema="false" sqlMaxLimit="100"/>
In this line of parameters, schema name defines the name of the logical database that can be displayed on the MyCAT front-end,
When the checkSQLschema parameter is False, it indicates that MyCAT will automatically ignore the database name before the table name. For example, mydatabase1.test1 will be regarded as test1;
sqlMaxLimit specifies the limit on the number of rows returned by the SQL statement;
As you can see in the upper right corner, MyCAT itself is cached;
So, if the statement we execute needs to return more data rows, what will MyCAT do without modifying this limit?
# can be seen from the screenshot, mycat does not ignore the actual needs of the front end, 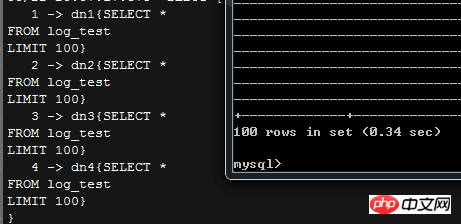
This is honest back 100 pieces of data This #, so if a large amount of data needs to be returned in an actual application, you may have to manually change the logic In version 1.4 of MyCAT, the user’s Limit parameter will overwrite the default MyCAT setting
------------------------------------------------ -------------------------------------------------- -------------------------------------------------- ----------------------------------
#table
name
=
"students" dataNode="dn1,dn2,dn3,dn4" rule="rule1" /> This line represents What table names will be displayed on the MyCAT front-end? Similar lines all represent the same meaning. The emphasis here is on the table, and MyCAT does not define the table structure in the configuration file. If you use show create table on the front-end, MyCAT will display normally. Table structure information, observe the Debug log, It can be seen that MyCAT distributes the command to the database represented by dn1, and then returns the query result of dn1 to the front end
It can be judged that some similar query instructions at the database level may be distributed to a certain node separately. Then return the information of a certain node to the front end; Specific segmentation strategy, currently MyCAT only supports segmentation according to a special column and following some special rules, such as modulo, enumeration, etc. The details will be discussed later
----- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- --------------------
name
=
"item_test" primaryKey="ID" type ="global" dataNode="dn1,dn2,dn3,dn4" /> This row represents the global table, which means that the item_test table will save complete data copies in the four dataNodes, then Will the query be distributed to all databases? The query of the table will only be distributed to a certain node -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------I have not actually used childtable in the test, but it is mentioned in the design document of MyCAT that childtable is a structure that depends on the parent table.
This means that the joinkey of the childtable will follow the parentKey strategy of the parent table. Split together, when the parent table and child table are connected, and the connection condition is childtable.joinKey=parenttable.parentKey, cross-database connection will not be performed. -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -----------------------
The parameters of dataNode have been introduced in the previous chapter, so skip here~
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- --------------------------
dataHost configures the actual back-end database cluster. Most of the parameters are simple and easy to understand. Here are I will not introduce them one by one. I will only introduce the two more important parameters, writeType and balance. From the
cluster configuration
The test process here is more troublesome, so I will post the conclusion directly:
) 2.bALANCE = 1, read operations will be randomly scattered on LocalHost1 and two Readhost (
LocalHost failed, the writing operation will be in
Localhost1, if If localhost1 fails again, the write operation will not be possible. #localhost1,
localhost1 and two readhosts (same as above) 4. When writeType=0, the write operation will be on localhost. If localhost fails, it will automatically Switch to localhost1. After localhost is restored, it will not switch back to localhost for write operations. On
localhost and localhost1, a single point of failure will not affect the write operation of the cluster. However, the back-end slave library will not be able to obtain updates from the failed main library, and will fail when reading data. Data inconsistency occurs
## , but localhost’s slave library cannot obtain updates from localhost, localhost’s slave library has data inconsistency with other libraries
------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------In fact, MyCAT's own read-write separation is based on the synchronization of the back-end cluster, and MyCAT itself provides the statement distribution function. Of course, The sqlLimit restriction also causes MyCAT to have some impact on the logic of the front-end application layer.
The configuration from schema to table shows that the logical structure of MyCAT itself includes the characteristics of sub-database and sub-table (can be Specify that different tables exist in different databases without having to be divided into all databases)
The above is the detailed content of MySQL distributed cluster MyCAT (2) schema code detailed explanation. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



