##1. Preface
## In the previous articles I introduced how to analyze through Python Source code to crawl blogs, Wikipedia InfoBox and pictures, the article link is as follows:
[Python learning] Simple crawling of Wikipedia programming language message box [Python learning] Simple web crawler crawling blog articles and ideas introduction
[Python learning] Simply crawl the pictures in the picture website gallery
The core code is as follows: # coding=utf-8
import urllib
import re
#下载静态HTML网页
url='http://www.csdn.net/'
content = urllib.urlopen(url).read()
open('csdn.html','w+').write(content)
#获取标题
title_pat=r'(?<=<title>).*?(?=</title>)'
title_ex=re.compile(title_pat,re.M|re.S)
title_obj=re.search(title_ex, content)
title=title_obj.group()
print title
#获取超链接内容
href = r'<a href=.*?>(.*?)</a>'
m = re.findall(href,content,re.S|re.M)
for text in m:
print unicode(text,'utf-8')
break #只输出一个urlCopy after login
The output result is as follows:
>>>
CSDN.NET - 全球最大中文IT社区,为IT专业技术人员提供最全面的信息传播和服务平台
登录
>>>
Copy after login
The core code for image downloading is as follows:
import os
import urllib
class AppURLopener(urllib.FancyURLopener):
version = "Mozilla/5.0"
urllib._urlopener = AppURLopener()
url = "http://creatim.allyes.com.cn/imedia/csdn/20150228/15_41_49_5B9C9E6A.jpg"
filename = os.path.basename(url)
urllib.urlretrieve(url , filename)Copy after login
But the above method of analyzing HTML to crawl website content has many drawbacks, such as: 1. Regular expressions are constrained by the HTML source code, rather than depending on more abstract structures ;Small changes in the structure of the web page may cause program interruption. 2. The program needs to analyze the content based on the actual HTML source code. It may encounter HTML features such as character entities such as &, and needs to specify processing such as , icon hyperlinks, subscripts, etc. Different content.
3. Regular expressions are not completely readable, and more complex HTML codes and query expressions will become messy.
## Basic Tutorial (2nd Edition) uses two solutions: the first is to use Tidy (Python library) program and XHTML parsing ;The second is to use the BeautifulSoup library.
# 2. Installation and introduction Beautiful Soup library
##Beautiful Soup is an HTML/XML parser written in Python , which can handle irregular markup well and generate parse tree. It provides simple and commonly used operations for navigating, searching, and modifying parse trees. It can save your programming time greatly.
As the book says, "You didn't write those bad web pages, you just tried to get some data from them. Now you don't care what the HTML looks like , the parser helps you achieve it."
Download address: http://www .php.cn/
//m.sbmmt.com/
The installation process is as shown below: python setup.py install
 ## It is recommended to refer to Chinese for specific usage methods: //m.sbmmt.com/ Among them, the usage of BeautifulSoup is briefly explained, using the official example of "Alice in Wonderland":
## It is recommended to refer to Chinese for specific usage methods: //m.sbmmt.com/ Among them, the usage of BeautifulSoup is briefly explained, using the official example of "Alice in Wonderland":
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#获取BeautifulSoup对象并按标准缩进格式输出
soup = BeautifulSoup(html_doc)
print(soup.prettify())
Copy after login
Output contentThe structure output according to the standard indentation format
is as follows:
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
Elsie
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>Copy after login
'''获取title值'''
print soup.title
# <title>The Dormouse's story</title>
print soup.title.name
# title
print unicode(soup.title.string)
# The Dormouse's story
'''获取<p>值'''
print soup.p
# <p class="title"><b>The Dormouse's story</b></p>
print soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
'''从文档中找到<a>的所有标签链接'''
print soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
for link in soup.find_all('a'):
print(link.get('href'))
# //m.sbmmt.com/
# //m.sbmmt.com/
# //m.sbmmt.com/
print soup.find(id='link3')
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>Copy after login
If you want to get all the text content in the article, the code is as follows:
'''从文档中获取所有文字内容'''
print soup.get_text()
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
Copy after login
同时在这过程中你可能会遇到两个典型的错误提示:
1.ImportError: No module named BeautifulSoup
当你成功安装BeautifulSoup 4库后,“from BeautifulSoup import BeautifulSoup”可能会遇到该错误。

其中的原因是BeautifulSoup 4库改名为bs4,需要使用“from bs4 import BeautifulSoup”导入。
2.TypeError: an integer is required
当你使用“print soup.title.string”获取title的值时,可能会遇到该错误。如下:
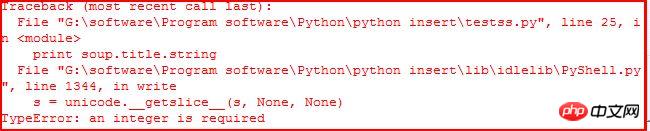
它应该是IDLE的BUG,当使用命令行Command没有任何错误。参考:stackoverflow。同时可以通过下面的代码解决该问题:
print unicode(soup.title.string)
print str(soup.title.string)
三. Beautiful Soup常用方法介绍
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment|
1.Tag标签
tag对象与XML或HTML文档中的tag相同,它有很多方法和属性。其中最重要的属性name和attribute。用法如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" id="start"><b>The Dormouse's story</b></p>
"""
soup = BeautifulSoup(html)
tag = soup.p
print tag
# <p class="title" id="start"><b>The Dormouse's story</b></p>
print type(tag)
# <class 'bs4.element.Tag'>
print tag.name
# p 标签名字
print tag['class']
# [u'title']
print tag.attrs
# {u'class': [u'title'], u'id': u'start'}Copy after login
使用BeautifulSoup每个tag都有自己的名字,可以通过.name来获取;同样一个tag可能有很多个属性,属性的操作方法与字典相同,可以直接通过“.attrs”获取属性。至于修改、删除操作请参考文档。
2.NavigableString
字符串常被包含在tag内,Beautiful Soup用NavigableString类来包装tag中的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且还支持包含在遍历文档树和搜索文档树中的一些特性,通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串。
print unicode(tag.string)
# The Dormouse's story
print type(tag.string)
# <class 'bs4.element.NavigableString'>
tag.string.replace_with("No longer bold")
print tag
# <p class="title" id="start"><b>No longer bold</b></p>Copy after login
这是获取“The Dormouse's story
”中tag = soup.p的值,其中tag中包含的字符串不能编辑,但可通过函数replace_with()替换。
NavigableString 对象支持遍历文档树和搜索文档树 中定义的大部分属性, 并非全部。尤其是一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
3.Beautiful Soup对象
该对象表示的是一个文档的全部内容,大部分时候可以把它当做Tag对象,它支持遍历文档树和搜索文档树中的大部分方法。
注意:因为BeautifulSoup对象并不是真正的HTML或XML的tag,所以它没有name和 attribute属性,但有时查看它的.name属性可以通过BeautifulSoup对象包含的一个值为[document]的特殊实行.name实现——soup.name。
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中:CData , ProcessingInstruction , Declaration , Doctype 。与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享。
4.Command注释
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有些特殊对象容易让人担心——注释。Comment对象是一个特殊类型的NavigableString对象。
markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
soup = BeautifulSoup(markup)
comment = soup.b.string
print type(comment)
# <class 'bs4.element.Comment'>
print unicode(comment)
# Hey, buddy. Want to buy a used parser?
Copy after login
介绍完这四个对象后,下面简单介绍遍历文档树和搜索文档树及常用的函数。
5.遍历文档树
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。BeautifulSoup提供了许多操作和遍历子节点的属性。引用官方文档中爱丽丝例子:
操作文档最简单的方法是告诉你想获取tag的name,如下:
soup.head# <head><title>The Dormouse's story</title></head>soup.title# <title>The Dormouse's story</title>soup.body.b# <b>The Dormouse's story</b>
Copy after login
注意:通过点取属性的放是只能获得当前名字的第一个Tag,同时可以在文档树的tag中多次调用该方法如soup.body.b获取标签中第一个标签。
如果想得到所有的标签,使用方法find_all(),在前面的Python爬取维基百科等HTML中我们经常用到它+正则表达式的方法。
soup.find_all('a')# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
Copy after login
子节点:在分析HTML过程中通常需要分析tag的子节点,而tag的 .contents 属性可以将tag的子节点以列表的方式输出。字符串没有.contents属性,因为字符串没有子节点。
head_tag = soup.head
head_tag
# <head><title>The Dormouse's story</title></head>
head_tag.contents
[<title>The Dormouse's story</title>]
title_tag = head_tag.contents[0]
title_tag
# <title>The Dormouse's story</title>
title_tag.contents
# [u'The Dormouse's story']
Copy after login
通过tag的 .children 生成器,可以对tag的子节点进行循环:
for child in title_tag.children:
print(child)
# The Dormouse's storyCopy after login
子孙节点:同样 .descendants 属性可以对所有tag的子孙节点进行递归循环:
for child in head_tag.descendants:
print(child)
# <title>The Dormouse's story</title>
# The Dormouse's storyCopy after login
父节点:通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,标签是标签的父节点,换句话就是增加一层标签。<br/> <span style="color:#ff0000">注意:文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的 .parent 是None。</span><br/></span></strong></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">title_tag = soup.titletitle_tag# <title>The Dormouse's story</title>title_tag.parent# <head><title>The Dormouse's story</title></head>title_tag.string.parent# <title>The Dormouse's story</title></pre><div class="contentsignin">Copy after login</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">兄弟节点</span>:因为<b>标签和<c>标签是同一层:他们是同一个元素的子节点,所以<b>和<c>可以被称为兄弟节点。一段文档以标准格式输出时,兄弟节点有相同的缩进级别.在代码中也可以使用这种关系。</span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>")print(sibling_soup.prettify())# <html># <body># <a># <b># text1# </b># <c># text2# </c># </a># </body># </html></pre><div class="contentsignin">Copy after login</div></div><p><strong><span style="font-size:18px"> <span style="color:#ff0000">在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点。<b>标签有.next_sibling 属性,但是没有.previous_sibling 属性,因为<b>标签在同级节点中是第一个。同理<c>标签有.previous_sibling 属性,却没有.next_sibling 属性:</span></span></strong><br/></p><div class="code" style="position:relative; padding:0px; margin:0px;"><pre style="overflow-x:auto; overflow-y:hidden; padding:5px; color:rgb(51,51,51); line-height:15.6000003814697px; border-top-width:1px; border-bottom-width:1px; border-style:solid none; border-top-color:rgb(170,204,153); border-bottom-color:rgb(170,204,153); background-color:rgb(238,255,204)">sibling_soup.b.next_sibling# <c>text2</c>sibling_soup.c.previous_sibling# <b>text1</b></pre><div class="contentsignin">Copy after login</div></div><p><strong><span style="font-size:18px"> 介绍到这里基本就可以实现我们的BeautifulSoup库爬取网页内容,而网页修改、删除等内容建议大家阅读文档。下一篇文章就再次爬取维基百科的程序语言的内容吧!希望文章对大家有所帮助,如果有错误或不足之处,还请海涵!建议大家阅读官方文档和《Python基础教程》书。</span><br><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px"> </span><span style="font-size:18px; font-family:Arial; line-height:26px"><span style="color:#ff0000"> (By:Eastmount 2015-3-25 下午6点</span></span><span style="font-size:18px; color:rgb(51,51,51); font-family:Arial; line-height:26px">
</span>//m.sbmmt.com/<span style="font-family:Arial; color:#ff0000"><span style="font-size:18px; line-height:26px">)</span></span></strong><br></p>
<p></p>
<p><br></p>
<p class="pmark"><br></p>
<p>
</p></span></p><p>The above is the detailed content of Python BeautifulSoup library installation and introduction. For more information, please follow other related articles on the PHP Chinese website!</p> </div>
</div>
<div style="height: 25px;">
<div class="wzconBq" style="display: inline-flex;">
<span>Related labels:</span>
<div class="wzcbqd">
<a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/search?word=beautifulsoup" target="_blank">beautifulsoup</a> <a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/search?word=python" target="_blank">python</a> <a onclick="hits_log(2,'www',this);" href-data="//m.sbmmt.com/search?word=knowledge" target="_blank">Knowledge</a> </div>
</div>
<div style="display: inline-flex;float: right; color:#333333;">source:php.cn</div>
</div>
<div class="wzconOtherwz">
<a href="//m.sbmmt.com/faq/355982.html" title="Detailed explanation of methods, properties, and iterators in Python">
<span>Previous article:Detailed explanation of methods, properties, and iterators in Python</span>
</a>
<a href="//m.sbmmt.com/faq/356004.html" title="Usage of functions map() and reduce() in Python">
<span>Next article:Usage of functions map() and reduce() in Python</span>
</a>
</div>
<div class="wzconShengming">
<div class="bzsmdiv">Statement of this Website</div>
<div>The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn</div>
</div>
<ins class="adsbygoogle"
style="display:block"
data-ad-format="autorelaxed"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="2507867629"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="wzconZzwz">
<div class="wzconZzwztitle">Latest Articles by Author</div>
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/faq/354750.html">Examples of html settings for bold, italic, underline, strikethrough and other font effects</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/faq/338018.html">Implement a Java version of Redis</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/faq/353509.html">The simplest WeChat applet Demo</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/faq/356272.html">Introduction to simple operation methods of pandas.DataFrame (create, index, add and delete) in python</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/faq/354839.html">WeChat Mini Program: Example of how to implement tabs effect</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/faq/354423.html">Python constructs custom methods to beautify dictionary structure output</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/faq/350853.html">HTML5: Use Canvas to process Video in real time</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/faq/346502.html">Asp.net uses SignalR to send pictures</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/faq/354842.html">WeChat Mini Program Development Tutorial-App() and Page() Function Overview</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots"></span>
<a target="_blank" href="//m.sbmmt.com/faq/356574.html">Detailed explanation of how to use python redis</a>
</div>
<div>1970-01-01 08:00:00</div>
</li>
</ul>
</div>
<div class="wzconZzwz">
<div class="wzconZzwztitle">Latest Issues</div>
<div class="wdsyContent">
<div class="wdsyConDiv flexRow wdsyConDiv1">
<div class="wdcdContent flexColumn">
<a href="//m.sbmmt.com/wenda/175783.html" target="_blank" title="How to scrape specific Google Weather text using BeautifulSoup?" class="wdcdcTitle">How to scrape specific Google Weather text using BeautifulSoup?</a>
<a href="//m.sbmmt.com/wenda/175783.html" class="wdcdcCons">How to find the course text "New York City, USA" in Python using BeautifulSoup? ...</a>
<div class="wdcdcInfo flexRow">
<div class="wdcdcileft">
<span class="wdcdciSpan"> From 2024-04-01 14:06:14</span>
</div>
<div class="wdcdciright flexRow">
<div class="wdcdcirdz flexRow ira"> <b class="wdcdcirdzi"></b>0 </div>
<div class="wdcdcirpl flexRow ira"><b class="wdcdcirpli"></b>1</div>
<div class="wdcdcirwatch flexRow ira"><b class="wdcdcirwatchi"></b>308</div>
</div>
</div>
</div>
</div>
<div class="wdsyConLine wdsyConLine2"></div>
</div>
</div>
<div class="wzconZt" >
<div class="wzczt-title">
<div>Related Topics</div>
<a href="//m.sbmmt.com/faq/zt" target="_blank">More>
</a>
</div>
<div class="wzcttlist">
<ul>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/faq/pythonkfgj"><img src="https://img.php.cn/upload/subject/202407/22/2024072214424826783.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python development tools" /> </a>
<a target="_blank" href="//m.sbmmt.com/faq/pythonkfgj" class="title-a-spanl" title="python development tools"><span>python development tools</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/faq/pythondb"><img src="https://img.php.cn/upload/subject/202407/22/2024072214312147925.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python packaged into executable file" /> </a>
<a target="_blank" href="//m.sbmmt.com/faq/pythondb" class="title-a-spanl" title="python packaged into executable file"><span>python packaged into executable file</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/faq/pythonnzsm"><img src="https://img.php.cn/upload/subject/202407/22/2024072214301218201.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="what python can do" /> </a>
<a target="_blank" href="//m.sbmmt.com/faq/pythonnzsm" class="title-a-spanl" title="what python can do"><span>what python can do</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/faq/formatzpython"><img src="https://img.php.cn/upload/subject/202407/22/2024072214275096159.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="How to use format in python" /> </a>
<a target="_blank" href="//m.sbmmt.com/faq/formatzpython" class="title-a-spanl" title="How to use format in python"><span>How to use format in python</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/faq/pythonjc"><img src="https://img.php.cn/upload/subject/202407/22/2024072214254329480.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python tutorial" /> </a>
<a target="_blank" href="//m.sbmmt.com/faq/pythonjc" class="title-a-spanl" title="python tutorial"><span>python tutorial</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/faq/pythonhjblbz"><img src="https://img.php.cn/upload/subject/202407/22/2024072214252616529.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="Configuration of python environment variables" /> </a>
<a target="_blank" href="//m.sbmmt.com/faq/pythonhjblbz" class="title-a-spanl" title="Configuration of python environment variables"><span>Configuration of python environment variables</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/faq/pythoneval"><img src="https://img.php.cn/upload/subject/202407/22/2024072214251549631.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="python eval" /> </a>
<a target="_blank" href="//m.sbmmt.com/faq/pythoneval" class="title-a-spanl" title="python eval"><span>python eval</span> </a>
</li>
<li class="ul-li">
<a target="_blank" href="//m.sbmmt.com/faq/scratchpyt"><img src="https://img.php.cn/upload/subject/202407/22/2024072214235344903.jpg?x-oss-process=image/resize,m_fill,h_145,w_220" alt="The difference between scratch and python" /> </a>
<a target="_blank" href="//m.sbmmt.com/faq/scratchpyt" class="title-a-spanl" title="The difference between scratch and python"><span>The difference between scratch and python</span> </a>
</li>
</ul>
</div>
</div>
</div>
</div>
<div class="phpwzright">
<ins class="adsbygoogle"
style="display:block"
data-ad-client="ca-pub-5902227090019525"
data-ad-slot="3653428331"
data-ad-format="auto"
data-full-width-responsive="true"></ins>
<script>
(adsbygoogle = window.adsbygoogle || []).push({});
</script>
<div class="wzrOne">
<div class="wzroTitle">Popular Recommendations</div>
<div class="wzroList">
<ul>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="What does eval mean in python?" href="//m.sbmmt.com/faq/419793.html">What does eval mean in python?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="How to read txt file content in python" href="//m.sbmmt.com/faq/479676.html">How to read txt file content in python</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="py file?" href="//m.sbmmt.com/faq/418747.html">py file?</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="What does str mean in python" href="//m.sbmmt.com/faq/419809.html">What does str mean in python</a>
</div>
</li>
<li>
<div class="wzczzwzli">
<span class="layui-badge-dots wzrolr"></span>
<a style="height: auto;" title="How to use format in python" href="//m.sbmmt.com/faq/471817.html">How to use format in python</a>
</div>
</li>
</ul>
</div>
</div>
<script src="https://sw.php.cn/hezuo/cac1399ab368127f9b113b14eb3316d0.js" type="text/javascript"></script>
<div class="wzrThree">
<div class="wzrthree-title">
<div>Popular Tutorials</div>
<a target="_blank" href="//m.sbmmt.com/course.html">More>
</a>
</div>
<div class="wzrthreelist swiper2">
<div class="wzrthreeTab swiper-wrapper">
<div class="check tabdiv swiper-slide" data-id="one">Related Tutorials <div></div></div>
<div class="tabdiv swiper-slide" data-id="two">Popular Recommendations<div></div></div>
<div class="tabdiv swiper-slide" data-id="three">Latest courses<div></div></div>
</div>
<ul class="one">
<li>
<a target="_blank" href="//m.sbmmt.com/course/812.html" title="The latest ThinkPHP 5.1 world premiere video tutorial (60 days to become a PHP expert online training course)" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/041/620debc3eab3f377.jpg" alt="The latest ThinkPHP 5.1 world premiere video tutorial (60 days to become a PHP expert online training course)"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="The latest ThinkPHP 5.1 world premiere video tutorial (60 days to become a PHP expert online training course)" href="//m.sbmmt.com/course/812.html">The latest ThinkPHP 5.1 world premiere video tutorial (60 days to become a PHP expert online training course)</a>
<div class="wzrthreerb">
<div>1427566 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="812">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/74.html" title="PHP introductory tutorial one: Learn PHP in one week" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/6253d1e28ef5c345.png" alt="PHP introductory tutorial one: Learn PHP in one week"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="PHP introductory tutorial one: Learn PHP in one week" href="//m.sbmmt.com/course/74.html">PHP introductory tutorial one: Learn PHP in one week</a>
<div class="wzrthreerb">
<div>4277973 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="74">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/286.html" title="JAVA Beginner's Video Tutorial" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a2bacfd9379.png" alt="JAVA Beginner's Video Tutorial"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="JAVA Beginner's Video Tutorial" href="//m.sbmmt.com/course/286.html">JAVA Beginner's Video Tutorial</a>
<div class="wzrthreerb">
<div>2578507 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="286">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/504.html" title="Little Turtle's zero-based introduction to learning Python video tutorial" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a67ce3a6655.png" alt="Little Turtle's zero-based introduction to learning Python video tutorial"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Little Turtle's zero-based introduction to learning Python video tutorial" href="//m.sbmmt.com/course/504.html">Little Turtle's zero-based introduction to learning Python video tutorial</a>
<div class="wzrthreerb">
<div>510352 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="504">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/2.html" title="PHP zero-based introductory tutorial" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/6253de27bc161468.png" alt="PHP zero-based introductory tutorial"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="PHP zero-based introductory tutorial" href="//m.sbmmt.com/course/2.html">PHP zero-based introductory tutorial</a>
<div class="wzrthreerb">
<div>867541 <b class="kclbcollectb"></b></div>
<div class="courseICollection" data-id="2">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
<ul class="two" style="display: none;">
<li>
<a target="_blank" href="//m.sbmmt.com/course/812.html" title="The latest ThinkPHP 5.1 world premiere video tutorial (60 days to become a PHP expert online training course)" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/041/620debc3eab3f377.jpg" alt="The latest ThinkPHP 5.1 world premiere video tutorial (60 days to become a PHP expert online training course)"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="The latest ThinkPHP 5.1 world premiere video tutorial (60 days to become a PHP expert online training course)" href="//m.sbmmt.com/course/812.html">The latest ThinkPHP 5.1 world premiere video tutorial (60 days to become a PHP expert online training course)</a>
<div class="wzrthreerb">
<div >1427566 times of learning</div>
<div class="courseICollection" data-id="812">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/286.html" title="JAVA Beginner's Video Tutorial" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a2bacfd9379.png" alt="JAVA Beginner's Video Tutorial"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="JAVA Beginner's Video Tutorial" href="//m.sbmmt.com/course/286.html">JAVA Beginner's Video Tutorial</a>
<div class="wzrthreerb">
<div >2578507 times of learning</div>
<div class="courseICollection" data-id="286">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/504.html" title="Little Turtle's zero-based introduction to learning Python video tutorial" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62590a67ce3a6655.png" alt="Little Turtle's zero-based introduction to learning Python video tutorial"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Little Turtle's zero-based introduction to learning Python video tutorial" href="//m.sbmmt.com/course/504.html">Little Turtle's zero-based introduction to learning Python video tutorial</a>
<div class="wzrthreerb">
<div >510352 times of learning</div>
<div class="courseICollection" data-id="504">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/901.html" title="Quick introduction to web front-end development" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/64be28a53a4f6310.png" alt="Quick introduction to web front-end development"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Quick introduction to web front-end development" href="//m.sbmmt.com/course/901.html">Quick introduction to web front-end development</a>
<div class="wzrthreerb">
<div >216284 times of learning</div>
<div class="courseICollection" data-id="901">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/234.html" title="Master PS video tutorials from scratch" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/068/62611f57ed0d4840.jpg" alt="Master PS video tutorials from scratch"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Master PS video tutorials from scratch" href="//m.sbmmt.com/course/234.html">Master PS video tutorials from scratch</a>
<div class="wzrthreerb">
<div >899573 times of learning</div>
<div class="courseICollection" data-id="234">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
<ul class="three" style="display: none;">
<li>
<a target="_blank" href="//m.sbmmt.com/course/1648.html" title="[Web front-end] Node.js quick start" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png" alt="[Web front-end] Node.js quick start"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="[Web front-end] Node.js quick start" href="//m.sbmmt.com/course/1648.html">[Web front-end] Node.js quick start</a>
<div class="wzrthreerb">
<div >8224 times of learning</div>
<div class="courseICollection" data-id="1648">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/1647.html" title="Complete collection of foreign web development full-stack courses" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/6628cc96e310c937.png" alt="Complete collection of foreign web development full-stack courses"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Complete collection of foreign web development full-stack courses" href="//m.sbmmt.com/course/1647.html">Complete collection of foreign web development full-stack courses</a>
<div class="wzrthreerb">
<div >6558 times of learning</div>
<div class="courseICollection" data-id="1647">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/1646.html" title="Go language practical GraphQL" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662221173504a436.png" alt="Go language practical GraphQL"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Go language practical GraphQL" href="//m.sbmmt.com/course/1646.html">Go language practical GraphQL</a>
<div class="wzrthreerb">
<div >5409 times of learning</div>
<div class="courseICollection" data-id="1646">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/1645.html" title="550W fan master learns JavaScript from scratch step by step" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/662077e163124646.png" alt="550W fan master learns JavaScript from scratch step by step"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="550W fan master learns JavaScript from scratch step by step" href="//m.sbmmt.com/course/1645.html">550W fan master learns JavaScript from scratch step by step</a>
<div class="wzrthreerb">
<div >746 times of learning</div>
<div class="courseICollection" data-id="1645">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
<li>
<a target="_blank" href="//m.sbmmt.com/course/1644.html" title="Python master Mosh, a beginner with zero basic knowledge can get started in 6 hours" class="wzrthreelaimg">
<img src="https://img.php.cn/upload/course/000/000/067/6616418ca80b8916.png" alt="Python master Mosh, a beginner with zero basic knowledge can get started in 6 hours"/>
</a>
<div class="wzrthree-right">
<a target="_blank" title="Python master Mosh, a beginner with zero basic knowledge can get started in 6 hours" href="//m.sbmmt.com/course/1644.html">Python master Mosh, a beginner with zero basic knowledge can get started in 6 hours</a>
<div class="wzrthreerb">
<div >27660 times of learning</div>
<div class="courseICollection" data-id="1644">
<b class="nofollow small-nocollect"></b>
</div>
</div>
</div>
</li>
</ul>
</div>
<script>
var mySwiper = new Swiper('.swiper2', {
autoplay: false,//可选选项,自动滑动
slidesPerView : 'auto',
})
$('.wzrthreeTab>div').click(function(e){
$('.wzrthreeTab>div').removeClass('check')
$(this).addClass('check')
$('.wzrthreelist>ul').css('display','none')
$('.'+e.currentTarget.dataset.id).show()
})
</script>
</div>
<div class="wzrFour">
<div class="wzrfour-title">
<div>Latest Downloads</div>
<a href="//m.sbmmt.com/xiazai">More>
</a>
</div>
<script>
$(document).ready(function(){
var sjyx_banSwiper = new Swiper(".sjyx_banSwiperwz",{
speed:1000,
autoplay:{
delay:3500,
disableOnInteraction: false,
},
pagination:{
el:'.sjyx_banSwiperwz .swiper-pagination',
clickable :false,
},
loop:true
})
})
</script>
<div class="wzrfourList swiper3">
<div class="wzrfourlTab swiper-wrapper">
<div class="check swiper-slide" data-id="onef">Web Effects <div></div></div>
<div class="swiper-slide" data-id="twof">Website Source Code<div></div></div>
<div class="swiper-slide" data-id="threef">Website Materials<div></div></div>
<div class="swiper-slide" data-id="fourf">Front End Template<div></div></div>
</div>
<ul class="onef">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery enterprise message form contact code" href="//m.sbmmt.com/toolset/js-special-effects/8071">[form button] jQuery enterprise message form contact code</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="HTML5 MP3 music box playback effects" href="//m.sbmmt.com/toolset/js-special-effects/8070">[Player special effects] HTML5 MP3 music box playback effects</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="HTML5 cool particle animation navigation menu special effects" href="//m.sbmmt.com/toolset/js-special-effects/8069">[Menu navigation] HTML5 cool particle animation navigation menu special effects</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery visual form drag and drop editing code" href="//m.sbmmt.com/toolset/js-special-effects/8068">[form button] jQuery visual form drag and drop editing code</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="VUE.JS imitation Kugou music player code" href="//m.sbmmt.com/toolset/js-special-effects/8067">[Player special effects] VUE.JS imitation Kugou music player code</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="Classic html5 pushing box game" href="//m.sbmmt.com/toolset/js-special-effects/8066">[html5 special effects] Classic html5 pushing box game</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="jQuery scrolling to add or reduce image effects" href="//m.sbmmt.com/toolset/js-special-effects/8065">[Picture special effects] jQuery scrolling to add or reduce image effects</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a target="_blank" title="CSS3 personal album cover hover zoom effect" href="//m.sbmmt.com/toolset/js-special-effects/8064">[Photo album effects] CSS3 personal album cover hover zoom effect</a>
</div>
</li>
</ul>
<ul class="twof" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8328" title="Home Decor Cleaning and Repair Service Company Website Template" target="_blank">[Front-end template] Home Decor Cleaning and Repair Service Company Website Template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8327" title="Fresh color personal resume guide page template" target="_blank">[Front-end template] Fresh color personal resume guide page template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8326" title="Designer Creative Job Resume Web Template" target="_blank">[Front-end template] Designer Creative Job Resume Web Template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8325" title="Modern engineering construction company website template" target="_blank">[Front-end template] Modern engineering construction company website template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8324" title="Responsive HTML5 template for educational service institutions" target="_blank">[Front-end template] Responsive HTML5 template for educational service institutions</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8323" title="Online e-book store mall website template" target="_blank">[Front-end template] Online e-book store mall website template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8322" title="IT technology solves Internet company website template" target="_blank">[Front-end template] IT technology solves Internet company website template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8321" title="Purple style foreign exchange trading service website template" target="_blank">[Front-end template] Purple style foreign exchange trading service website template</a>
</div>
</li>
</ul>
<ul class="threef" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-materials/3078" target="_blank" title="Cute summer elements vector material (EPS PNG)">[PNG material] Cute summer elements vector material (EPS PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-materials/3077" target="_blank" title="Four red 2023 graduation badges vector material (AI EPS PNG)">[PNG material] Four red 2023 graduation badges vector material (AI EPS PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-materials/3076" target="_blank" title="Singing bird and cart filled with flowers design spring banner vector material (AI EPS)">[banner picture] Singing bird and cart filled with flowers design spring banner vector material (AI EPS)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-materials/3075" target="_blank" title="Golden graduation cap vector material (EPS PNG)">[PNG material] Golden graduation cap vector material (EPS PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-materials/3074" target="_blank" title="Black and white style mountain icon vector material (EPS PNG)">[PNG material] Black and white style mountain icon vector material (EPS PNG)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-materials/3073" target="_blank" title="Superhero silhouette vector material (EPS PNG) with different color cloaks and different poses">[PNG material] Superhero silhouette vector material (EPS PNG) with different color cloaks and different poses</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-materials/3072" target="_blank" title="Flat style Arbor Day banner vector material (AI+EPS)">[banner picture] Flat style Arbor Day banner vector material (AI+EPS)</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-materials/3071" target="_blank" title="Nine comic-style exploding chat bubbles vector material (EPS+PNG)">[PNG material] Nine comic-style exploding chat bubbles vector material (EPS+PNG)</a>
</div>
</li>
</ul>
<ul class="fourf" style="display:none">
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8328" target="_blank" title="Home Decor Cleaning and Repair Service Company Website Template">[Front-end template] Home Decor Cleaning and Repair Service Company Website Template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8327" target="_blank" title="Fresh color personal resume guide page template">[Front-end template] Fresh color personal resume guide page template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8326" target="_blank" title="Designer Creative Job Resume Web Template">[Front-end template] Designer Creative Job Resume Web Template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8325" target="_blank" title="Modern engineering construction company website template">[Front-end template] Modern engineering construction company website template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8324" target="_blank" title="Responsive HTML5 template for educational service institutions">[Front-end template] Responsive HTML5 template for educational service institutions</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8323" target="_blank" title="Online e-book store mall website template">[Front-end template] Online e-book store mall website template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8322" target="_blank" title="IT technology solves Internet company website template">[Front-end template] IT technology solves Internet company website template</a>
</div>
</li>
<li>
<div class="wzrfourli">
<span class="layui-badge-dots wzrflr"></span>
<a href="//m.sbmmt.com/toolset/website-source-code/8321" target="_blank" title="Purple style foreign exchange trading service website template">[Front-end template] Purple style foreign exchange trading service website template</a>
</div>
</li>
</ul>
</div>
<script>
var mySwiper = new Swiper('.swiper3', {
autoplay: false,//可选选项,自动滑动
slidesPerView : 'auto',
})
$('.wzrfourlTab>div').click(function(e){
$('.wzrfourlTab>div').removeClass('check')
$(this).addClass('check')
$('.wzrfourList>ul').css('display','none')
$('.'+e.currentTarget.dataset.id).show()
})
</script>
</div>
</div>
</div>
<footer>
<div class="footer">
<div class="footertop">
<img src="/static/imghw/logo.png" alt="">
<p>Public welfare online PHP training,Help PHP learners grow quickly!</p>
</div>
<div class="footermid">
<a href="//m.sbmmt.com/about/us.html">About us</a>
<a href="//m.sbmmt.com/about/disclaimer.html">Disclaimer</a>
<a href="//m.sbmmt.com/update/article_0_1.html">Sitemap</a>
</div>
<div class="footerbottom">
<p>
© php.cn All rights reserved
</p>
</div>
</div>
</footer>
<input type="hidden" id="verifycode" value="/captcha.html">
<script>layui.use(['element', 'carousel'], function () {var element = layui.element;$ = layui.jquery;var carousel = layui.carousel;carousel.render({elem: '#test1', width: '100%', height: '330px', arrow: 'always'});$.getScript('/static/js/jquery.lazyload.min.js', function () {$("img").lazyload({placeholder: "/static/images/load.jpg", effect: "fadeIn", threshold: 200, skip_invisible: false});});});</script>
<script src="/static/js/common_new.js"></script>
<script type="text/javascript" src="/static/js/jquery.cookie.js?1736707011"></script>
<script src="https://vdse.bdstatic.com//search-video.v1.min.js"></script>
<link rel='stylesheet' id='_main-css' href='/static/css/viewer.min.css?2' type='text/css' media='all'/>
<script type='text/javascript' src='/static/js/viewer.min.js?1'></script>
<script type='text/javascript' src='/static/js/jquery-viewer.min.js'></script>
<script type="text/javascript" src="/static/js/global.min.js?5.5.53"></script>
<!-- Matomo -->
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function() {
var u="https://tongji.php.cn/";
_paq.push(['setTrackerUrl', u+'matomo.php']);
_paq.push(['setSiteId', '9']);
var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
})();
</script>
<!-- End Matomo Code -->
</body>
</html>



